文章目录
1 条件随机场定义
1.1 马尔科夫随机场
1.1.1 用图模型表示概率
图G=(V,E),V表示顶点集合,E表示边的集合。
概率图模型表示用图表示概率的分布。
可以用无向图G表示联合概率分布P(Y)。Y一定是一个矢量。
顶点 v ∈ V v \in V v∈V表示一个随机变量 Y v Y_v Yv, Y = ( Y v ) v ∈ V Y = (Y_v)_{v \in V} Y=(Yv)v∈V。
边 e ∈ E e \in E e∈E表示随机变量之间的概率依赖关系。
1.1.2 局部马尔科夫性
成对马尔科夫性,局部马尔科夫性以及全局马尔科夫性是等价的。
v是无向图G中任意一个结点,对应随机变量 Y v Y_v Yv。
W是与v有边链接的所有结点,对应随机变量组是 Y W Y_W YW。
O是v,W以外的所有结点,对应随机变量组是 Y O Y_O YO。
那么 P ( Y v , Y O ∣ Y W ) = P ( Y v ∣ Y W ) P ( Y O ∣ Y W ) P(Y_v,Y_O|Y_W) =P(Y_v|Y_W)P(Y_O|Y_W) P(Yv,YO∣YW)=P(Yv∣YW)P(YO∣YW),说明给定 Y W Y_W YW条件下 Y v Y_v Yv和 Y O Y_O YO是条件独立的。也就是说v只与W有关系。
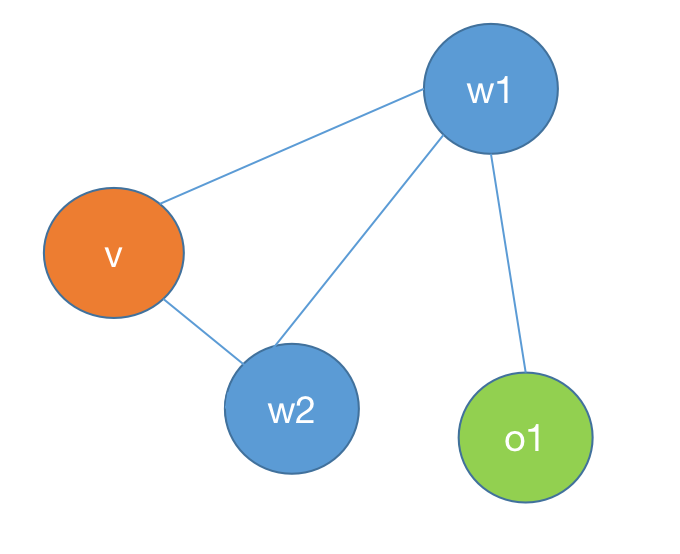
如图所示W表示所有与v相连的点。O表示除v和W之外的所有点。
我们再看 P ( Y v , Y O ∣ Y W ) = P ( Y v ∣ Y O , Y W ) P ( Y O ∣ Y W ) P(Y_v,Y_O|Y_W) =P(Y_v|Y_O,Y_W)P(Y_O|Y_W) P(Yv,YO∣YW)=P(Yv∣YO,YW)P(YO∣YW)(根据条件概率公式)
两个公式联合起来得到结论: P ( Y v ∣ Y W ) = P ( Y v ∣ Y O , Y W ) P(Y_v|Y_W) = P(Y_v|Y_O,Y_W) P(Yv∣YW)=P(Yv∣YO,YW)
1.2 马尔科夫随机场的因子分解
团:无向图中任意两个结点均有边相连的节点子集。
最⼤团:⽆向图 中的⼀个团,并且不能再加进任何⼀个结点使其成为⼀个更⼤的团。
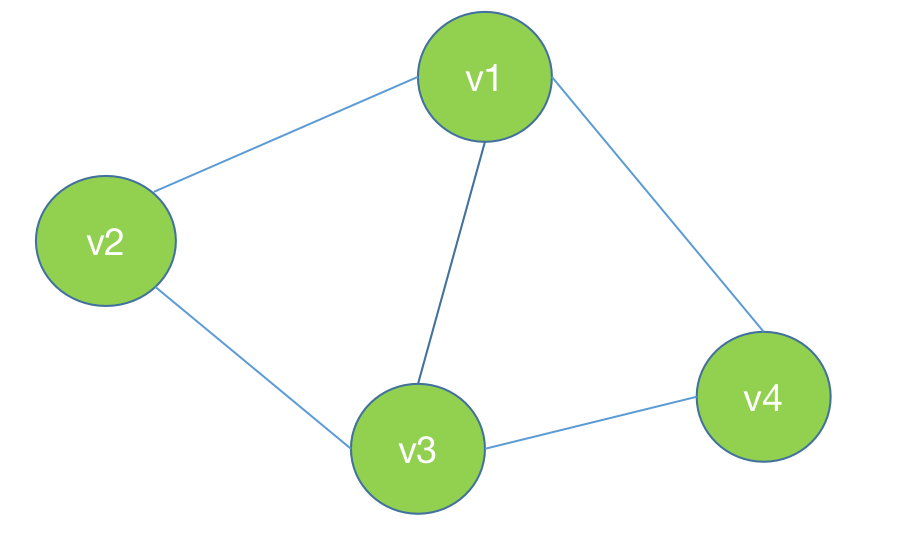
这个图中的最大团是(v1,v2,v3)或者(v1,v3,v4)
概率图像图的联合概率分布 P ( Y ) = 1 Z ∏ C Φ C ( Y C ) P(Y) = \dfrac{1}{Z}\prod_C \Phi_C(Y_C) P(Y)=Z1∏CΦC(YC)
其中C是无向图的最大团, Y C Y_C YC是C的节点对应的随机变量,
势函数 Φ C ( Y C ) = e x p { − E ( Y C ) } \Phi_C(Y_C)=exp\{-E(Y_C)\} ΦC(YC)=exp{
−E(YC)}
Z是规范化因子,是一个全概率分布, Z = ∑ Y ∏ C Φ C ( Y C ) Z=\sum_Y\prod_C\Phi_C(Y_C) Z=∑Y∏CΦC(YC)
乘积是在无向图所有的最大图上进行的。
1.3 条件随机场及线性连条件随机场
我们用无向图G表示事件Y的概率,Y中包含Y1,Y2,Y3…Yn。这些事件之间具有线性关系。
再假设还有条件X,X包含X1,X2,X3…Xn。X和Y之间具有线性关系。如下图所示。
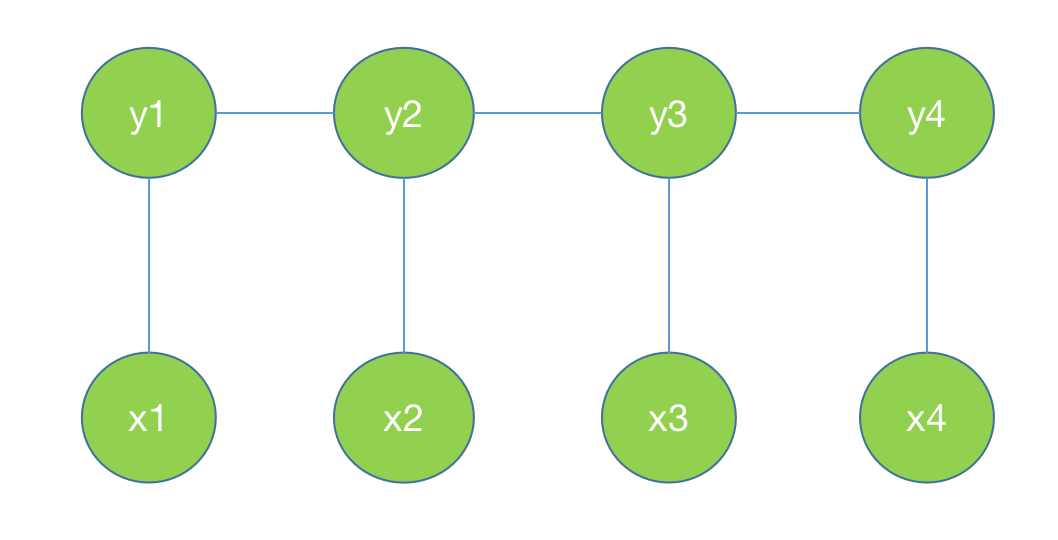
那么条件概率P(Y|X)
P ( Y v ∣ X , Y w , w ≠ v ) = P ( Y v ∣ X , Y w , w − v ) P(Y_v|X,Y_w,w\ne v) = P(Y_v|X,Y_w,w-v) P(Yv∣X,Yw,w=v)=P(Yv∣X,Yw,w−v)对任意节点v成立,则称条件概率分布P(Y|X)为条件随机场。w-v表示w是与v相连的所有点。也就是说v事件发生的概率只与与它相连的点有关系。
说明:X是Y的条件,X是输入,Y是输出。
再加上条件Y是具有线性关系的,X和Y具有相同的线性结构。上面的公式可以写为: P ( Y i ∣ X , Y 1 , Y 2 . . . Y i − 1 , Y i + 1 , . . . Y n ) = P ( Y v ∣ X , Y i − 1 , Y i + 1 ) P(Y_i|X,Y_1,Y_2...Y_{i-1},Y_{i+1},...Y_n) = P(Y_v|X,Y_{i-1},Y_{i+1}) P(Yi∣X,Y1,Y2...Yi−1,Yi+1,...Yn)=P(Yv∣X,Yi−1,Yi+1)。这个公式称为线性链条件随机场。
2条件随机场的表示形式
2.1 参数化形式
定义了每个节点和每条边的特征函数,用特征函数表示概率。
P ( Y ) = s 1 t 1 s 2 t 2 . . . t n − 1 s n P(Y)=s_1t_1s_2t_2...t_{n-1}s_n P(Y)=s1t1s2t2...tn−1sn
设P(Y|X)为线性链条件随机场,则在随机变量X取值为x的条件下,随机变量Y取值为y的条件概率
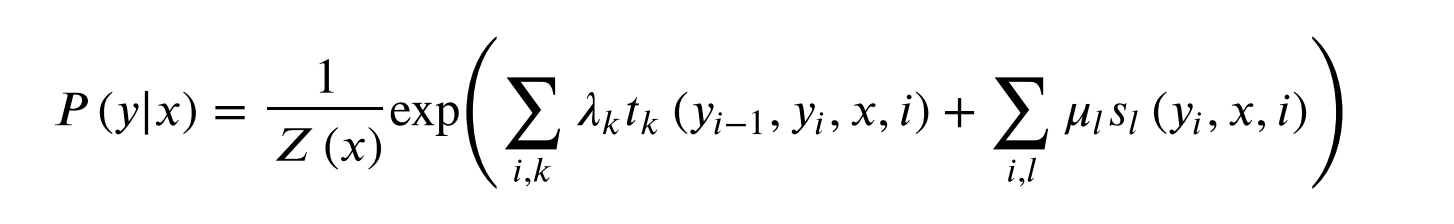
其中,
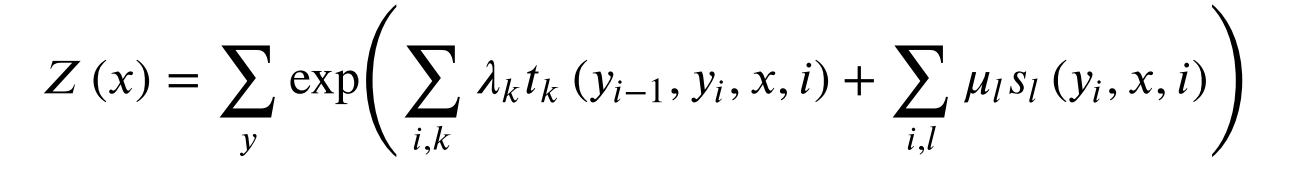
t k t_k tk是定义在边上的特征函数。依赖于当前和前一个位置。
s l s_l sl是定义在结点上的特征函数,称为状态特征,依赖于当前位置。
t k t_k tk和 s l s_l sl值为1或者0。
λ k \lambda_k λk和 μ l \mu_l μl是对应的权值。
Z(x)是规范化因子,求和是在所有可能的输出序列上。
s l s_l sl的个数应该等于边的个数每个顶点可能的取值集合个数
t k t_k tk个数=边的个数(第一个顶点取值个数*第二个顶点取值个数)
2.2 简化形式
用 f k f_k fk表示边的特征函数和节点的特征函数。
用w表示边的权重和节点的权重。
用向量化表示为:
P ( y ∣ x ) = e x p ( w . F ( y , x ) ) Z w ( x ) P(y|x)=\dfrac{exp(w.F(y,x))}{Z_w(x)} P(y∣x)=Zw(x)exp(w.F(y,x)),其中
Z w ( x ) = ∑ y e x p ( w . F ( y , x ) ) Z_w(x) = \sum_y exp(w.F(y,x)) Zw(x)=∑yexp(w.F(y,x))
2.3 矩阵形式
引入一个特殊的起点标记 y 0 = s t a r t y_0=start y0=start表示开始状态, y n + 1 = s t o p y_{n+1}=stop yn+1=stop表示终止状态。定义一个m阶矩阵。
m是 y i y_i yi取值的个数。
如果 y i y_i yi表示骰子出现的某一面,那么m=6;如果 y i y_i yi表示一枚硬件哪面朝上,那么m=2。
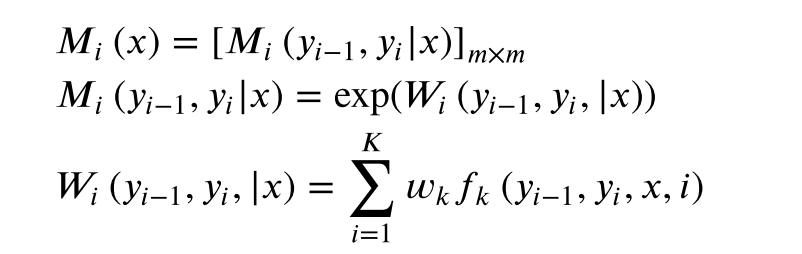
P ( y ∣ x ) = 1 Z w ( x ) ∏ i = 1 n + 1 M i ( y i − 1 , y i ∣ x ) P(y|x) = \dfrac{1}{Z_w(x)}\prod^{n+1}_{i=1}M_i(y_{i-1},y_i|x) P(y∣x)=Zw(x)1∏i=1n+1Mi(yi−1,yi∣x),
其中 Z w ( x ) = ( M 1 ( x ) , M 2 ( x ) , . . . M n + 1 ( x ) ) s t a r t , s t o p Z_w(x)=(M_1(x),M_2(x),...M_{n+1}(x))_{start,stop} Zw(x)=(M1(x),M2(x),...Mn+1(x))start,stop
矩阵最关注矩阵的形状。
3 最大熵模型
3.1最大熵模型定义
模型就是一个从输入到输出的一个映射,可以是一个f(x),也可以是一个P(y|x)。当在所有条件都满足的时候,这个函数不唯一的时候,就使用最大熵策略来选择模型。所以最大熵模型是一种选择策略,是一种世界观。
熵最大=变量几乎可以均匀分布
特征函数f(x,y)关于经验分布 P ^ ( X , Y ) \hat{P}(X,Y) P^(X,Y)的期望应该等于关于模型P(Y|X)与经验分布 P ^ ( X , Y ) \hat{P}(X,Y) P^(X,Y)的期望。
最⼤熵模型:假设满⾜所有约束条件的模型集合为 C ≡ P C\equiv {P} C≡P
定义在条件概率分布P(Y|X)上的条件熵为: H ( P ) = − ∑ x , y P ^ ( x ) P ( y ∣ x ) l o g P ( y ∣ x ) H(P)=-\sum_{x,y}\hat{P}(x)P(y|x)logP(y|x) H(P)=−∑x,yP^(x)P(y∣x)logP(y∣x)
3.2 最大熵模型学习
拉格朗日乘子法
1 构建拉格朗日乘子
2 求min
3 求max
这部分的学习跳过了。直接用结论。
4 条件随机场的概率计算
前向计算
后向计算
这里的结果是中间量
5 条件随机场的学习算法
由训练数集,计算经验概率分布 P ^ ( X , Y ) \hat{P}(X,Y) P^(X,Y)。
6 条件随机场的预测算法
给定条件随机场P(Y|X)和输入观测序列x,求条件概率最大的标记序列y*。
公式太多,没有记录。