深度强化学习 Deep Reinforcement Learning
DQN
DQN的出现事实上是解决了Q-learning中state数量的限制,在Q-learning中,无论是state的数量还是action的数量都没法做到很大,而DQN利用神经网络取代了Q-learning中的Q表从而解决了第一个问题:state数量的限制,这是一个novel 的ideal,2013年第一篇论文问世,随之在2015年nature刊登。
先给出一个算法框图,源自一位班级同学:

要是觉得上面这个同学的图过于眼花缭乱,看下面这张简图:

这个框图描述的是2015年Nature版本的DQN,主要就是两个网络,一个eval_net,一个target_net,你可以把这两个网络想象成从q-learning Q表中衍生而来的,eval_net用于评价当前状态下各个action的Q值,使用e贪婪策略选取action,当然神经网络的更新需要loss,而loss从哪而来?答案是target_net,输入target_net的是s‘,也就是在s下执行动作a后进入的新状态s’,使用它的输出值来代替传统Q表更新时查找Q(s’)最大值的操作。loss就按如下式子得到,不过具体的计算过程还会有点出入,因为是通过Batch_size的矩阵输入训练的。
r j + γ max a ′ Q ^ ( ϕ j + 1 , a ′ ; θ − ) r_{j}+\gamma \max _{a^{\prime}} \hat{Q}\left(\phi_{j+1}, a^{\prime} ; \theta^{-}\right) rj+γa′maxQ^(ϕj+1,a′;θ−)
- target_net负责agent与环境的交互决策,agent将当前state输入target_net得到shape=(1,action_num)的输出,利用e贪婪选择执行的动作a,即可得到下一个state:s‘。
- DQN利用记忆单元存放(s,a,r,s’),这个回忆单元有容量上限,每次learn从这个回忆单元sample一组batch_size来train。解决了训练样本的关联性问题。
- 每隔N个时间步长将eval_net的网络参数copy到target_net中。
训练时数据维度探讨
输入target_net的训练矩阵A.shape = (Batch_size,state_num) ps:A(s,a,r,s’),输出B.shape = (Batch_size, action_num),同时A矩阵输入eval_net,输出C.shape = (Batch_size, action_num),利用B中的数据和A中的reward使用上面讲到的公式计算"loss",其对应到C中action的位置。最后loss再做均方差后梯度反向传递更新网络参数。
算法伪代码

这里面的 ϕ ( s t ) \phi(s_t) ϕ(st)就是对状态的一种表达,可以理解为状态是一个抽象的东西,而 ϕ \phi ϕ为抽取状态的具象表达(状态空间)。理解DQN的关键就在于理解target_net是如何得到所谓的loss的。
Policy Gradient
PG即策略梯度,相较于DQN而言最大的差别在于网络不再输出一个状态下每个action的Q值,而是使用输出概率分布的方式(网络最后一层为softmax),这也就代表PG是一种随机性策略算法(probalistic)。例如在状态 s t s_t st下,PG输出3个动作的概率分布 [ 0.2 , 0.6 , 0.2 ] [0.2,0.6,0.2] [0.2,0.6,0.2],那么根据这个分布利用tfp中函数就能随机出一个基于概率的action_value,注意,动作不再是离散值了,而是在action范围内的值。
算法伪代码

红线部分是理解PG的核心,我们稍后再讲。我们先讲PG相较于DQN而言的另一个差别就是回合更新制,什么叫回合更新呢,你可以想象RL训练倒立摆,训练过程中由于不稳定导致倒立摆偏出中心位置一定距离后,我们认为该回合结束,把这一回合中所有经历过的样本 ( s , a , r , s ) (s,a,r,s_) (s,a,r,s)组成一个训练集一起对网络进行参数更新,反之DQN则是几步一更新。
算法框图
这里再次引用同学绘制的简图:

理解PG中loss怎么计算
PG中只有一个网络,我们称其为PG_net,很有趣的是,PG_net的更新机制是==“自我更新”==,这和DQN又有点出入了,DQN在计算loss时是使用到了另外一个网络来帮助其完成反向传播的。
另外,PG在存储训练样本时也和DQN有所不同,PG存储的是 ( s , a , r ) (s,a,r) (s,a,r)而DQN存储的是 ( s , a , r , s _ ) (s,a,r,s\_) (s,a,r,s_),PG不需要下一时刻的state,这就涉及到PG的思想了“根据reward调整自己的动作”。
下面讲解一下loss的计算过程,我们假设一个回合结束了,将经验存储池中的训练集A(size,(s,a,r,s_))中s(size,state_num)输入PG_net,将得到一个输出res(size,action_num),这个res就是预测的概率分布:

对每个元素加上 − l o g -log −log:
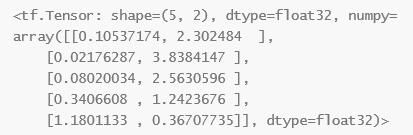
这时取A中的action部分也就是a,加入 a = [ 1 , 1 , 0 , 0 , 0 ] a = [1, 1, 0, 0, 0] a=[1,1,0,0,0],我们根据a的值挑选这个概率分布:

即用上面这个矩阵乘以-log后的矩阵(元素乘法),做完这个操作后shape还是(5,2),再按行做均值得到C,shape变为(5,1),之后再对每个元素乘以 v t v_t vt,这时一个奖励因子向量,由训练样本集A中的r列表求得:
( e p r s [ 4 ] ∗ γ 4 + e p r s [ 3 ] ∗ γ 3 + e p r s [ 2 ] ∗ γ 2 + e p r s [ 1 ] ∗ γ 1 + e p r s [ 0 ] e p r s [ 4 ] ∗ γ 3 + e p r s [ 3 ] ∗ γ 2 + e p r s [ 2 ] ∗ γ 1 + e p r s [ 1 ] e p r s [ 4 ] ∗ γ 2 + e p r s [ 3 ] ∗ γ 1 + e p r s [ 2 ] e p r s [ 4 ] ∗ γ 1 + e p r s [ 3 ] e p r s [ 4 ] ) \left(\begin{array}{c} e p r s[4] * \gamma^{4}+e p r s[3] * \gamma^{3}+e p r s[2] * \gamma^{2}+e p r s[1] * \gamma^{1}+e p r s[0] \\ e p r s[4] * \gamma^{3}+e p r s[3] * \gamma^{2}+e p r s[2] * \gamma^{1}+e p r s[1] \\ e p r s[4] * \gamma^{2}+e p r s[3] * \gamma^{1}+e p r s[2] \\ e p r s[4] * \gamma^{1}+e p r s[3] \\ e p r s[4] \end{array}\right) ⎝⎜⎜⎜⎜⎛eprs[4]∗γ4+eprs[3]∗γ3+eprs[2]∗γ2+eprs[1]∗γ1+eprs[0]eprs[4]∗γ3+eprs[3]∗γ2+eprs[2]∗γ1+eprs[1]eprs[4]∗γ2+eprs[3]∗γ1+eprs[2]eprs[4]∗γ1+eprs[3]eprs[4]⎠⎟⎟⎟⎟⎞
eprs就是r列表,例如eprs = [1,1,1,1,1]。这里这个计算思想来源于Q-learning中贝尔曼方程, γ \gamma γ让强化学习模型适当地调节其“眼界”, γ \gamma γ越小,其越容易只满足于当下的reward而失去了探索精神,这也是权衡exploration和exploitation的过程。这让我想到了Bayesian Optimization algorithm…
将上式子元素乘法乘上C,最后再做一次均值,得到一个标量,我们称其为loss,将其反向传播,完成更新。
每完成一个回合,存储池中三个列表清空。
Actor Critic
AC分为两个部分:Actor和Critic,Actor负责执行决策,Critic负责告诉Actor决策的正确性。
Actor网络
Actor网络输入还是state,但是输出是一个二维的张量,一个是均值 μ \mu μ,一个是方差 σ \sigma σ,利用这两个数即可构建正太分布。没错,Actor就是输出一个纯正的连续分布,在选择action时也是基于这个分布选择,并且会有更大概率选择到均值 μ \mu μ的附近。
Critic网络
理解一个强化学习算法的核心是去找它的执行网络的“loss”是如何计算的,在AC算法中,Critic网络就起到为Actor更新参数提供误差td_error的作用。而这个td_error是如何计算的呢:
with tf.GradientTape() as tape:
v_ = self.Critic_net(s_)
v = self.Critic_net(s)
td_error = tf.reduce_mean(r + GAMMA * v_ - v)
loss = tf.square(td_error)
原来critic网络分别输入s和s_,得到两个输出v,v_(cirtic是输出一个标量的网络),这个时候又需要用到从Q-learning中传承下来的贝尔曼方程进行td_error的计算,另外值得注意的是Critic网络可不是定期从Actor复制参数过来,而是直接使用td_error进行更新,也就是Actor和Critic都是通过这个td_error更新网络参数的,更新的目标是最小化td_error的平方。
更新机制
AC算法的learn与DQN和PG都有所不同,DQN是间隔几步更新一次,有存储池,PG是一个回合更新一次,有存储列表,而AC属于单步更新,没有存储池,这也就导致了AC学到的样本的关联性较大,不容易收敛。但是AC算法的思想为后来的DDPG提供了基础。
DDPG
DDPG的出现就如同iphone4在iphone家族中的地位。
DDPG解决了Q-learning中的两个连续化的问题,第一个是state的连续化,第二个是输出的连续化。与PG和AC输出概率分布不同,DDPG是一种确定策略的算法,Actor的输出不再是一个分布,而是一个确定的值。
另外,DDPG的Actor可以输出多个维度的Action,例如一个司机同时需要决策油门大小和方向盘转动角度,这让DDPG在决策上优势显著。
同时,DDPG的网络数量直接在AC算法上double了,共4个网络,分为actor的估计和现实网络,critic的估计和现实网络。

DDPG四个网络的更新过程

DDPG内存池即learn方式
DDPG也借鉴了PG和DQN的内存池方式,同样为了减小样本之间的关联性,sample过程也与DQN很像,这里不赘述。DDPG的内存池溢出时sample一组样本进行训练,也与DQN一致。关于内存池,下面我摘一段一个大佬描述它的言论:
off-policy 算法在训练开始前,使用随机策略预先探索环境,保存到 replay buffer,用于增加训练前期稳定性,减少随机重启对RL 的影响。
DDPG相当于借鉴了DQN的内存池机制,PG的思想,AC利用td_error的更新方式。
关于DDPG的一些细节
- Replay Buffer方法中,Policy所表示的策略基本上就是围绕buffer中的经验来更新。使用Replay Buffer方法时,DDPG会很快找到一个确定性的策略,并且不再进行更多的探索,一旦在“收敛”后,遇到了Buffer中较长时间没有出现的状态,那么我们的策略将会瞬间变差
Soft Actor-Critic
学习资料
pytorch开源代码:
https://github.com/higgsfield/RL-Adventure-2/blob/master/7.soft%20actor-critic.ipynb
https://github.com/openai/spinningup
博客:
https://zhuanlan.zhihu.com/p/70360272 (有阅读门槛)
https://blog.csdn.net/qq_38587510/article/details/104970837(阅读门槛稍低,给出了SAC的一份伪代码,有参考价值,说明了SAC的主要思想,说明了一个分布的熵在SAC中是如何计算的)
https://blog.csdn.net/Sufail/article/details/104888861 (介绍性)
https://blog.csdn.net/weixin_44436360/article/details/108077422?utm_medium=distribute.pc_relevant.none-task-blog-title-4&spm=1001.2101.3001.4242(对原论文算法伪代码做了解释:分别更新的是哪些网络)
论文:
https://arxiv.org/abs/1801.01290
文章:
https://bair.berkeley.edu/blog/2017/10/06/soft-q-learning/(讲解最大熵RL、Soft Bellman Equation and Soft Q-Learning)
SAC网络结构以及更新法则
我用IPAD绘制了这部分内容:

可以看到,SAC共有三个网络:Actor(选择动作)、critic(评价动作)、target_critic(目标评价),其中critic和target_critic是twin网络结构,内部为两个网络构成,网络结构相同,target_critic和critic的网络结构又相同,在更新时target_critic网络从critic网络soft update参数。Actor的输入为state(或者为next_state),critic(或者是target_critic)的输入是state+action。另外比较有意思的是我看的这份代码中 α \alpha α也是需要反向传递loss更新的。有关更新的细节可以看上面这张图。