off-policy全系列(DDPG-TD3-SAC-SAC-auto)+优先经验回放PER-代码-实验结果分析
文章目录
前言:
ps: 欢迎做强化的同学加群一起学习:
深度强化学习-DRL:799378128
前后花了我两周时间,说一句全网最全PER的博客不过分吧。
三连走一个?东西仍然有点乱,欢迎大家评论区指正反馈~
之前在【一文弄懂】优先经验回放(PER)论文-算法-代码
分析讨论了一下,TD3-PER的效果。
但是当时由于忘了per的精髓,也没静下心去看原文。
我写错了per中的td_error…
将r+gamma*q_target写成了q_target
没想到的是,它在有些任务下,竟然也好使,效果也好像。要不是这玩意儿实在是没有物理意义,说不定还能水一篇文章…
重新编辑莫烦的教程:
–更新–
发现了一个新的参考博客:
强化学习(十一) Prioritized Replay DQN
大家可以直接看莫烦大佬的教程,写的比我上面的教程好理解多了~
但有点小细节需要注释一下。
正文:
- 缘起:当奖励稀疏时,少量高价值transition,被采样的频次会比较低,因此要增加他们的采样的权重。
- Prioritized replay 算法:

- 这一套算法重点就在我们 batch 抽样的时候并不是随机抽样, 而是按照 Memory 中的样本优先级来抽. 所以这能更有效地找到我们需要学习的样本.
那么样本的优先级是怎么定的呢? 原来我们可以用到 TD-error, 也就是Q现实 - Q估计
(即r+gammaQ_target - Q_eval,莫烦对Q现实和Q估计的定义有些不一样)
(二次注释:强化里面的notation经常会出现一些不匹配的问题。在spinup中,直接用来采样动作的一般称作为eval,用来稳定的网络一般叫做target部分,它的q值成为q_targ。但是用来真正更新critic网络的loss是由这两个变量决定的:
td_error = Q_target - Q(s,a) = r+gammaq_targ(s_,a_)-q_eval(s,a) ------)
来规定优先学习的程度. 如果 TD-error 越大, 就代表我们的预测精度还有很多上升空间, 那么这个样本就越需要被学习, 也就是优先级 p 越高.
有了 TD-error 就有了优先级 p, 那我们如何有效地根据 p 来抽样呢? 如果每次抽样都需要针对 p 对所有样本排序, 这将会是一件非常消耗计算能力的事. 好在我们还有其他方法, 这种方法不会对得到的样本进行排序. 这就是这篇 paper 中提到的 SumTree.
SumTree 是一种树形结构, 最底层每片树叶存储每个样本的优先级 p, 每个树枝节点只有两个分叉, 节点的值是两个分叉的和, 所以 SumTree 的顶端就是所有 p 的和. 正如下面图片(来自Jaromír Janisch), 最下面一层树叶存储样本的 p, 叶子上一层最左边的 13 = 3 + 10, 按这个规律相加, 顶层的 root 就是全部 p 的和了.
先看如何存数据:
- 参考下面的代码,可以看到我们设定两个变量,一个data,一个tree。data的维度是buffer的大小,用下面的树形图举例就是,data.shape=8。可以存8个数据。

抽样时, 我们会将 p 的总合除以batch size, 分成 batch size 那么多区间, ( n = s u m ( p ) / b a t c h s i z e n=sum(p)/batchsize n=sum(p)/batchsize). 如果将所有 node 的 priority 加起来是42的话, 我们如果抽6个样本, 这时的区间拥有的 priority 可能是这样.
[0-7], [7-14], [14-21], [21-28], [28-35], [35-42]
然后在每个区间里随机选取一个数. 比如在第区间 [21-28] 里选到了24, 就按照这个 24 从最顶上的42开始向下搜索. 首先看到最顶上 42 下面有两个 child nodes, 拿着手中的24对比左边的 child 29, 如果 左边的 child 比自己手中的值大, 那我们就走左边这条路, 接着再对比 29 下面的左边那个点 13, 这时, 手中的 24 比 13 大, 那我们就走右边的路, 并且将手中的值根据 13 修改一下, 变成 24-13 = 11. 接着拿着 11 和 16(莫烦的写成了13) 左下角的 12 比, 结果 12 比 11 大, 那我们就选 12 当做这次选到的 priority, 并且也选择 12 对应的数据.
sumtree采样过程。
为什么要这么左右横跳的操作呢?
这个逻辑大概是这样的。
我们看上图最后一行,是将总和42划分成了好多个区间,每个区间的大小是根据前面和以及当前值的大小来的,而这每个区间的大小其实就是节点值。
我们进行采样的时候,其实就是这么个思想,在0到总和42之间,随机取一个值,这个值属于哪个区间,朴素的统计学思想,区间越大,落入的概率越大。
假设随机采样的值是24,那么是属于哪个区间呢?在最后一行一眼看上去,就是落在第三个节点12,也就是区间(13,25)之间。
但是根据这个树存的信息,是无法直接拿到这个区间(13,25)的!
我们必须得根据这个树的规律来。
我们只能按树索骥,先看第二行,其实也是一个区间划分,只不过只有两个大区间,(0,29)和(29,42(即29+13)),那我们很清楚,24是属于左边的区间。即莫烦说的,如果当前值小于左边节点值,那么就进入左边的道路。
再看第三行,我们就有了四个区间(0,13),(13,29),(29,32),(32,42),我们的24即属于区间(13,29),因此要看下面一行。
再看第四行,我们的区间有八个,只看左边四个(0,3),(3,13),(13,25),(25,29),最后一个关键操作就是,为什么要减去左边节点值?因为我们知道当前节点在两个备选区间中,明确大于左边的区间,属于右边的区间,那么下一步要探究,节点在右边区间中,属于哪个小区间。
而右边区间的起始点是左边节点的值,因此我们要先减去左边区间值,才能继续往下走!
对应这段话的代码:
class SumTree(object):
"""
This SumTree code is a modified version and the original code is from:
https://github.com/jaara/AI-blog/blob/master/SumTree.py
Story data with its priority in the tree.
"""
data_pointer = 0
def __init__(self, capacity):
self.capacity = capacity
self.tree = np.zeros(2 * capacity - 1)
self.data = np.zeros(capacity, dtype=object)
def add(self, p, data):
pass
def update(self, tree_idx, p):
pass
def get_leaf(self, v):
"""
Tree structure and array storage:
Tree index:
0 -> storing priority sum
/ \
1 2
/ \ / \
3 4 5 6 -> storing priority for transitions
Array type for storing:
[0,1,2,3,4,5,6]
"""
parent_idx = 0
# the while loop is faster than the method in the reference code
while True:
# this leaf's left and right kids
cl_idx = 2 * parent_idx + 1
cr_idx = cl_idx + 1
# reach bottom, end search
if cl_idx >= len(self.tree):
leaf_idx = parent_idx
break
else:
# downward search, always search for a higher priority node
if v <= self.tree[cl_idx]:
parent_idx = cl_idx
else:
v -= self.tree[cl_idx]
parent_idx = cr_idx
data_idx = leaf_idx - self.capacity + 1
return leaf_idx, self.tree[leaf_idx], self.data[data_idx]
@property
def total_p(self):
return self.tree[0] # the root
sumtree如何插入新数据?
先把代码抽出来。
def add(self, p, data):
tree_idx = self.data_pointer + self.capacity - 1
self.data[self.data_pointer] = data # update data_frame
self.update(tree_idx, p) # update tree_frame
self.data_pointer += 1
if self.data_pointer >= self.capacity: # replace when exceed the capacity
self.data_pointer = 0
def update(self, tree_idx, p):
change = p - self.tree[tree_idx]
self.tree[tree_idx] = p
# then propagate the change through tree
while tree_idx != 0: # this method is faster than the recursive loop in the reference code
tree_idx = (tree_idx - 1) // 2
self.tree[tree_idx] += change
我们已经算出了优先值p,以及对应的数据data=(s,a,r,s_,d)
那么接下来要把这俩,挂到树上。
先查看一下树上本身有多少个数据,当前数据得往后排一个。
我们可以从上面那个sumtree的图中可以直观的看到,真正的数据索引都是在最后一行。
那么第一个数据的索引 ,应该是0到倒数第一层的所有节点的和,即self.capcity-1.
这时候我们拿到了tree_idx = self.data_pointer + self.capacity - 1
先把数据data先存到self.data中。
接下来要更新整个tree的节点了。
这个有点绕,得慢慢说。
因为我们拿到了该数据在tree中的索引tree_idx,以及优先级p,那么进入update函数。
在最低层,对tree_idx索引下的节点直接变更值为p.
往上回溯,得把它的祖宗节点都更新一下。
这时候,我们需要知道它父节点索引和当前节点索引的关系。
直接上结论:
二叉树中父节点为k,它的左子节点下标为2k+1,右子节点是2k+2。
证明见博客:二叉树的父子节点位置关系(学习笔记)
这样就明白了,所有祖宗节点都更新完,这波更新结束。
重要性采样ISweight及化简 :
为什么要用重要性采样,原理,可以见我未来的博客…
这个坑先挖着。。。
也可以直接看李宏毅大佬的b站课程-ppo那一节。
这个 ISweight 到底怎么算. 需要提到的一点是, 代码中的计算方法是经过了简化的, 将 paper 中的步骤合并了一些.
比如
prob = p / self.tree.total_p;
ISWeights = np.power(prob/min_prob, -self.beta)
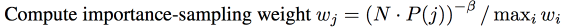
下面是莫烦的推导, 在paper 中,
I S W e i g h t = w j = ( N ∗ P j ) − b e t a / m a x i ( w i ) ISWeight =w_j= (N*P_j)^{-beta}/max_i(w_i) ISWeight=wj=(N∗Pj)−beta/maxi(wi)
里面的 m a x i ( w i ) max_i(w_i) maxi(wi) 是为了 normalize ISWeight,
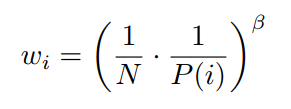
这里面的意思是我当前选择的样本是j,我拿到的权重稀疏是 w j w_j wj,但是我要归一化一下,想到的法子是除以所有样本中最大的那个权重样本i,那么用 m a x i ( w i ) max_{i}(w_i) maxi(wi)来表示。
单纯的 importance sampling 就是 ( N ∗ P j ) − b e t a (N*P_j)^{-beta} (N∗Pj)−beta,
那 m a x i ( w i ) = m a x i [ ( N ∗ P i ) − b e t a ] max_i(w_i) = max_i[(N*P_i)^{-beta}] maxi(wi)=maxi[(N∗Pi)−beta].
如果将这两个式子合并,
I S W e i g h t = ( N ∗ P j ) − b e t a / m a x i [ ( N ∗ P i ) − b e t a ] ISWeight = (N*P_j)^{-beta} / max_i[(N*P_i)^{-beta} ] ISWeight=(N∗Pj)−beta/maxi[(N∗Pi)−beta]
而且如果将
m a x i [ ( N ∗ P i ) − b e t a ] max_i[(N*P_i)^{-beta}] maxi[(N∗Pi)−beta] 中的 (-beta) 提出来,
这就变成了
[ m i n i ( N ∗ P i ) ] − b e t a [min_i(N*P_i) ] ^ {-beta} [mini(N∗Pi)]−beta
看出来了吧, 有的东西可以抵消掉的. 最后
I S W e i g h t = ( P j / m i n i ( P i ) ) − b e t a ISWeight = (P_j / min_i(P_i))^{-beta} ISWeight=(Pj/mini(Pi))−beta
这样我们就有了代码中的样子.
或者直接看下面的公式:
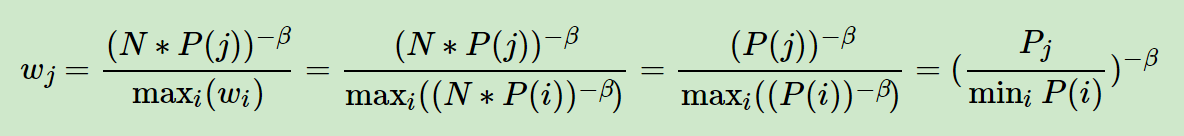
还有代码中的 alpha 是一个决定我们要使用多少 ISweight 的影响, 如果 alpha = 0, 我们就没使用到任何 Importance Sampling.
搭建神经网络时, 我们发现 DQN with Prioritized replay 只多了一个 ISWeights, 这个正是刚刚算法中提到的 Importance-Sampling Weights, 用来恢复被 Prioritized replay 打乱的抽样概率分布.
class DQNPrioritizedReplay:
def _build_net(self)
...
# self.prioritized 时 eval net 的 input 多加了一个 ISWeights
self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # input
self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target') # for calculating loss
if self.prioritized:
self.ISWeights = tf.placeholder(tf.float32, [None, 1], name='IS_weights')
...
# 为了得到 abs 的 TD error 并用于修改这些 sample 的 priority, 我们修改如下
with tf.variable_scope('loss'):
if self.prioritized:
self.abs_errors = tf.reduce_sum(tf.abs(self.q_target - self.q_eval), axis=1) # for updating Sumtree
# self.ISWeights得乘上去!
self.loss = tf.reduce_mean(self.ISWeights * tf.squared_difference(self.q_target, self.q_eval))
else:
self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))
全系列off-policy+PER代码:
我将我的基于spinningup的强化学习库-DRL-tensorflow,重新更新了,删掉了不必要的文件,只保留,最简洁,调试好的算法!
全系列off-policy,好用的强化算法,DDPG-TD3-SAC打包成类,随调随用,非常适合你自己定义的环境!
还有SAC-auto,这个是spinningup没有官方实现的算法,但是在这里,你可以直接享用(也是在大佬的代码基础上改的,代码里好像有标注)~
最后就是最新实现的per,我给上面所有的算法都加了优先经验回放(per)!
一键切换是否调用per!
per的优缺点:
优点:同样的交互次数,更高的性能,适合稀疏奖励环境,或者高奖励难以获得的复杂环境。
缺点:同样的时间,性能不一定更高,即花的时间要多三四倍。
实验测试结果:




实验分析:
- 首先我只在一个测试任务中,测试了一个随机种子,实验结果的偶然性很大,不能将上面的结果,严格的说明某些问题。
- 在DDPG中,官方实现是2500左右,我的标准DDPG也是2500左右,代码也基本上没动,作为基准应该没啥大问题,在此基础上加了per,性能提升到3500,还是有点用的(如果有必要的话);
- 在sac-auto中,这个算法本身就非常强了,官方实现是12000左右,我的基准没达到,应该是超参数不一致。但是加了per,效果提升了。好像也不能说明什么。
- 由于sac和td3性能结果太离谱,我又跑了一组随机种子100,勉强可以解释。1. TD3中,可能是per没加对,也可能是加per效果不好(至少在这个任务中)。2.sac-per一样的结果。
- 在sac中,有两个因素,一个是其他超参数,一个是sac自身的alpha,我可能都没有和spinup的匹配上,所以导致基准结果差很多(原来12000,我的只有8000)。但是sac-per性能这么差(2000),是我没想到的。
- 在td3中基准达到了10000,和官方差不多,但是td3-per性能只有6000,还没有上次写错的高。我也是分析无能了。
- 我在其他关于per的文章中,也看到了,经常一顿操作下来,有per的性能仍然是比没有的差。他们分析是rank形式的和比例形式的在原文中,在不同的雅他利游戏性能也有好有坏。这不是巨坑么…
就这样吧,有时间再测试一下,没时间就算了,大家用的时候,注意下~
时间消耗分析:
一直吐槽PER的时间消耗,但是没有一个定量的分析肯定不合适,本来我是想自己测试一下的。谷歌搜了一下,竟然搜到了一篇paper,人家认真做了time cost analysis,我对比了一下我的实验,发现,基本吻合。还是很棒的。
paper地址:
《Self-Adaptive Priority Correction for Prioritized Experience Replay》
The first one is the sample, which needs to search on the sum-tree. When the capacity of EM goes larger, the sampling time, whose time complexity is O(logN), becomes a bottleneck.
The second one is PER update, which is the same time complexity as sampling.
The last one is the DDQN or DDPG update, which is executed on GPU.
We measure the time cost to correct all priorities of EM(capacity is 106). All data must be predicted by DDQN on GPU, it needs 150+ s. We can see that the update cost is very high.

The total time also includes other processes which are not the main factors.
这里面的是单次采样消耗的时间,对于我的实验来说,episode-time-cost是15s左右,有1000个steps,因此total-time差不多也是0.015s。其中没有PER的TD3时间差不多是6秒左右,也符合。
那么根据这个表,我们可以看到采样的时间要占接近5秒的时间,更新也多了3秒的时间。
采样的时间主要是从sumtree里面拿搜索数据,以及计算 m a x i ( w i ) max_i(w_i) maxi(wi)。这个时间我还得靠自己的实验才能测出来。
等中午再测.
加了per的各模块时间消耗:
Episode: 22 Reward: -119 learn step: 23000 ep_time: 10.259
collection_time : 0.00126
save_time : 0.00036
interect_time : collection-save
total_learn_time : 0.00885
sample_time : 0.002
sample_tree_time : 0.00163
min_prob_time : 0.00034
run_time : 0.00196
update_time : 0.00254
没加per的时间消耗:
ep_time : 3.529
interact_time : 0.00066
total_learn_time : 0.00289
这个测试结果我还是很喜欢的,验证了我的一些猜测,也有一些小意外。
代码:TD3-PER-time-cost-analysis
名词注释:
ep_time: 10.259---1000steps的总时间
collection_time : 0.00126 ---采集1step数据的总时间
save_time : 0.00036 ---存一次数据到sumtree的时间
interect_time : collection-save --- 和环境交互一次的时间
total_learn_time : 0.00885 --- 更新一次参数的总时间,batch_size=100
sample_time : 0.002 --- 采样一个batch的总时间
sample_tree_time : 0.00163 --- 从sumtree中采样一个batch的时间
min_prob_time : 0.00034 --- 计算一次最小概率的时间
run_time : 0.00196 ---tf-网络更新一个batch的时间
update_time : 0.00254 ---更新sumtree 一次的时间
下一步画一下这个min_prob到底有多大的变化。