什么是哈希?
哈希,也称散列。在某种程度上,散列是与排序相反的一种操作,排序是将集合中的元素按照某种方式比如大小顺序排列在一起,而散列通过计算哈希值,打破元素之间原有的关系,使集合中的元素按照散列函数的分类进行排列。
为什么用哈希?
我们通常使用数组或者链表来存储元素,一旦存储的内容数量特别多,需要占用很大的空间,而且在查找某个元素是否存在的过程中,数组和链表都需要挨个循环比较,而通过 哈希 计算,可以大大减少比较次数。下面举个例子!
现在有 4 个数 {2,5,9,13},需要查找 13 是否存在。
1.使用数组存储,需要新建个数组 new int[]{2,5,9,13},然后需要写个循环遍历查找,这样需要遍历 4 次才能找到,时间复杂度为 O(n)。
2.而假如存储时先使用哈希函数进行计算,这里我随便用个函数:
H[key] = key % 3;
四个数 {2,5,9,13} 对应的哈希值为:
H[2] = 2 % 3 = 2;
H[5] = 5 % 3 = 2;
H[9] = 9 % 3 = 0;
H[13] = 13 % 3 = 1;
然后把它们存储到对应的位置。
当要查找 13 时,只要先使用哈希函数计算它的位置,然后去那个位置查看是否存在就好了,本例中只需查找一次,时间复杂度为 O(1)。
因此可以发现,哈希 其实是随机存储的一种优化,先进行分类,然后查找时按照这个对象的分类去找。
哈希通过一次计算大幅度缩小查找范围,自然比从全部数据里查找速度要快。
比如你和我一样是个剁手族买书狂,家里书一大堆,如果书存放时不分类直接摆到书架上(数组存储),找某本书时可能需要脑袋从左往右从上往下转好几圈才能发现;如果存放时按照类别分开放,技术书、小说、文学等等分开(按照某种哈希函数计算),找书时只要从它对应的分类里找,自然省事多了。
哈希函数
哈希函数是一种映射关系,根据数据的关键词 key ,通过一定的函数关系,计算出该元素存储位置的函数。
表示为:
address = H [key]
几种常见的哈希函数构造方法:直接定址法、除留余数法、数字分析法、平方取中法、叠加法、随机数法。
哈希表
哈希表是实现关联数组(associative array)的一种数据结构,广泛应用于实现数据的快速查找。
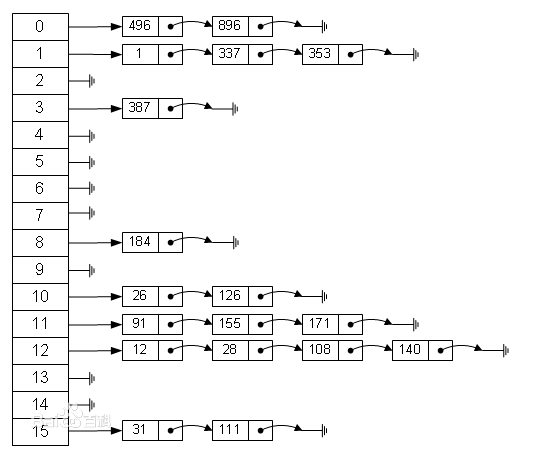
用哈希函数计算关键字的哈希值(hash value),通过哈希值这个索引就可以找到关键字的存储位置,即桶(bucket)。哈希表不同于二叉树、栈、序列的数据结构一般情况下,在哈希表上的插入、查找、删除等操作的时间复杂度是 O(1)。
查找过程中,关键字的比较次数,取决于产生冲突的多少,产生的冲突少,查找效率就高,产生的冲突多,查找效率就低。因此,影响产生冲突多少的因素,也就是影响查找效率的因素。