一、跳跃表
跳跃表(skiplist)是一种随机化的数据结构,由 William Pugh 在论文《Skip lists: a probabilistic alternative to balanced trees》中提出,是一种可以于平衡树媲美的层次化链表结构——查找、删除、添加等操作都可以在对数期望时间下完成
Redis 中为什么使用跳跃表
作者的意思是:比起红黑树,实现起来简单。
1.1 跳跃表的实现
Redis 中的跳跃表由 server.h/zskiplistNode 和 server.h/zskiplist 两个结构定义,前者为跳跃表节点,后者则保存了跳跃节点的相关信息,同之前的 集合 list 结构类似,其实只有 zskiplistNode 就可以实现了,但是引入后者是为了更加方便的操作:
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
// value
sds ele;
// 分值
double score;
// 后退指针
struct zskiplistNode *backward;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned long span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
// 跳跃表头指针
struct zskiplistNode *header, *tail;
// 表中节点的数量
unsigned long length;
// 表中层数最大的节点的层数
int level;
} zskiplist;
正如文章开头画出来的那张标准的跳跃表那样。
随机层数
对于每一个新插入的节点,都需要调用一个随机算法给它分配一个合理的层数,源码在 t_zset.c/zslRandomLevel(void) 中被定义:
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
直观上期望的目标是 50% 的概率被分配到 Level 1,25% 的概率被分配到 Level 2,12.5% 的概率被分配到 Level 3,以此类推…有 2-63 的概率被分配到最顶层,因为这里每一层的晋升率都是 50%。
Redis 跳跃表默认允许最大的层数是 32,被源码中 ZSKIPLIST_MAXLEVEL 定义,当 Level[0] 有 264 个元素时,才能达到 32 层,所以定义 32 完全够用了。
创建跳跃表
这个过程比较简单,在源码中的 t_zset.c/zslCreate 中被定义:
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
// 申请内存空间
zsl = zmalloc(sizeof(*zsl));
// 初始化层数为 1
zsl->level = 1;
// 初始化长度为 0
zsl->length = 0;
// 创建一个层数为 32,分数为 0,没有 value 值的跳跃表头节点
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
// 跳跃表头节点初始化
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
// 将跳跃表头节点的所有前进指针 forward 设置为 NULL
zsl->header->level[j].forward = NULL;
// 将跳跃表头节点的所有跨度 span 设置为 0
zsl->header->level[j].span = 0;
}
// 跳跃表头节点的后退指针 backward 置为 NULL
zsl->header->backward = NULL;
// 表头指向跳跃表尾节点的指针置为 NULL
zsl->tail = NULL;
return zsl;
}
参考资料 https://zhuanlan.zhihu.com/p/109946103
https://www.cnblogs.com/acfox/p/3688607.html
二、整数集合
每个 intset.h/intset 结构表示一个整数集合:
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
contents 数组是整数集合的底层实现: 整数集合的每个元素都是 contents 数组的一个数组项(item), 各个项在数组中按值的大小从小到大有序地排列, 并且数组中不包含任何重复项。
length 属性记录了整数集合包含的元素数量, 也即是 contents 数组的长度。
虽然 intset 结构将 contents 属性声明为 int8_t 类型的数组, 但实际上 contents 数组并不保存任何 int8_t 类型的值 —— contents 数组的真正类型取决于 encoding 属性的值:
- 如果 encoding 属性的值为 INTSET_ENC_INT16 , 那么 contents 就是一个 int16_t 类型的数组, 数组里的每个项都是一个 int16_t 类型的整数值 (最小值为 -32,768 ,最大值为 32,767 )。
- 如果 encoding 属性的值为 INTSET_ENC_INT32 , 那么 contents 就是一个 int32_t 类型的数组, 数组里的每个项都是一个 int32_t 类型的整数值 (最小值为 -2,147,483,648 ,最大值为 2,147,483,647 )。
- 如果 encoding 属性的值为 INTSET_ENC_INT64 , 那么 contents 就是一个 int64_t 类型的数组, 数组里的每个项都是一个 int64_t 类型的整数值 (最小值为 -9,223,372,036,854,775,808 ,最大值为 9,223,372,036,854,775,807 )。
图 6-1 展示了一个整数集合示例:
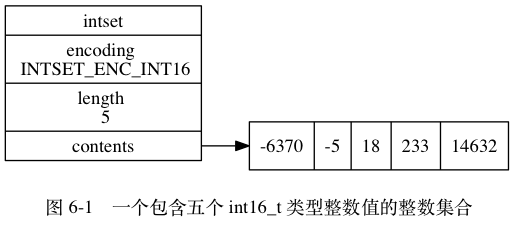
encoding 属性的值为 INTSET_ENC_INT16 , 表示整数集合的底层实现为 int16_t 类型的数组, 而集合保存的都是 int16_t 类型的整数值。
length 属性的值为 5 , 表示整数集合包含五个元素。
contents 数组按从小到大的顺序保存着集合中的五个元素。
因为每个集合元素都是 int16_t 类型的整数值, 所以 contents 数组的大小等于 sizeof(int16_t) * 5 = 16 * 5 = 80 位。
图 6-2 展示了另一个整数集合示例:
- encoding 属性的值为 INTSET_ENC_INT64 , 表示整数集合的底层实现为 int64_t 类型的数组, 而数组中保存的都是 int64_t 类型的整数值。
- length 属性的值为 4 , 表示整数集合包含四个元素。
- contents 数组按从小到大的顺序保存着集合中的四个元素。
因为每个集合元素都是 int64_t 类型的整数值, 所以 contents 数组的大小为 sizeof(int64_t) * 4 = 64 * 4 = 256 位。
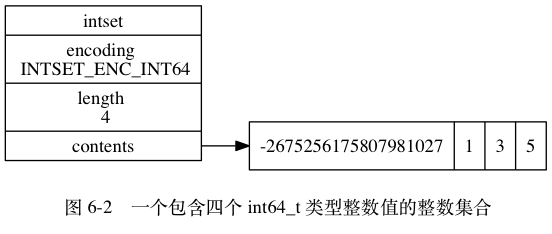
虽然 contents 数组保存的四个整数值中, 只有 -2675256175807981027 是真正需要用 int64_t 类型来保存的, 而其他的 1 、 3 、 5 三个值都可以用 int16_t 类型来保存, 不过根据整数集合的升级规则, 当向一个底层为 int16_t 数组的整数集合添加一个 int64_t 类型的整数值时, 整数集合已有的所有元素都会被转换成 int64_t 类型, 所以 contents 数组保存的四个整数值都是 int64_t 类型的, 不仅仅是 -2675256175807981027 。
2.1升级
每当我们要将一个新元素添加到整数集合里面, 并且新元素的类型比整数集合现有所有元素的类型都要长时, 整数集合需要先进行升级(upgrade), 然后才能将新元素添加到整数集合里面。
升级整数集合并添加新元素共分为三步进行:
- 根据新元素的类型, 扩展整数集合底层数组的空间大小, 并为新元素分配空间。
- 将底层数组现有的所有元素都转换成与新元素相同的类型, 并将类型转换后的元素放置到正确的位上, 而且在放置元素的过程中, 需要继续维持底层数组的有序性质不变。
- 将新元素添加到底层数组里面。
升级设计的目的,提升整数集合的灵活性,节约内存。
2.2降级
整数集合不支持降级操作, 一旦对数组进行了升级, 编码就会一直保持升级后的状态。
举个例子, 对于图 6-11 所示的整数集合来说, 即使我们将集合里唯一一个真正需要使用 int64_t 类型来保存的元素 4294967295 删除了, 整数集合的编码仍然会维持 INTSET_ENC_INT64 , 底层数组也仍然会是 int64_t 类型的。
三、压缩列表
压缩列表(ziplist)是列表键和哈希键的底层实现之一。
当一个列表键只包含少量列表项, 并且每个列表项要么就是小整数值, 要么就是长度比较短的字符串, 那么 Redis 就会使用压缩列表来做列表键的底层实现。
比如说, 执行以下命令将创建一个压缩列表实现的列表键:
redis> RPUSH lst 1 3 5 10086 "hello" "world"
(integer) 6
redis> OBJECT ENCODING lst
"ziplist"
因为列表键里面包含的都是 1 、 3 、 5 、 10086 这样的小整数值, 以及 “hello” 、 “world” 这样的短字符串。
另外, 当一个哈希键只包含少量键值对, 并且每个键值对的键和值要么就是小整数值, 要么就是长度比较短的字符串, 那么 Redis 就会使用压缩列表来做哈希键的底层实现。
举个例子, 执行以下命令将创建一个压缩列表实现的哈希键:
redis> HMSET profile "name" "Jack" "age" 28 "job" "Programmer"
OK
redis> OBJECT ENCODING profile
"ziplist"
压缩列表是Redis为了节约内存而开发的,是由一系列特殊编码的连续内存块组成的顺序性数据结构。一个压缩列表可以包含任意多个节点,每个节点可以保存一个字节数组或者一个整数值。
| zlbytes | zltail | zllen | entry1 | entry2 | … | entryN | zlend |
|---|
因为哈希键里面包含的所有键和值都是小整数值或者短字符串。
压缩列表各个组成部分的详细说明
| 属性 | 用途 |
|---|---|
| zlbytes | 记录整个压缩列表占用的内存字节数:在对压缩列表进行内存重分配,或者计算zlend的位置时使用 |
| zltail | 记录压缩列表表尾节点距离压缩列表的起始地址有多少个字节:通过这个偏移量,程序无需遍历整个压缩列表就可以确定表尾节点的地址 |
| zllens | 记录了压缩列表包含的节点数量 |
| entryX | 压缩列表包含的各个节点,节点的长度由节点保存的内存决定 |
| zlend | 特殊值oxFF(十进制255),用于标记压缩列表的末尾 |
- 压缩列表节点的构成
每个压缩列表节点可以保存一个字节数组或者一个整数值。
previous_entry_length encoding content
每个压缩列表节点都由previous_entry_length、encoding、content三个部分组成
参考资料:
http://redisbook.com/preview/ziplist/list.html
https://segmentfault.com/a/1190000022061626
压缩列表entry 可能是任何类型
四、redis 对象
Redis 并没有直接使用字典、动态字符串SDS、双端链表、压缩列表、整数集合这些数据结构来实现键值对数据库,而是基于这些数据结构创建了一个对象系统,这个系统包含字符串对象,列表对象,哈希对象,集合对象,和有序集合对象这五种类型
redisObject 是 Redis 类型系统的核心,数据库中的每个键、值,以及 Redis 本身处理的参数,
都表示为这种数据类型。
redisObject 的定义位于 redis.h :
/*
* Redis 对象
*/
typedef struct redisObject {
// 类型
unsigned type:4;
// 对齐位
unsigned notused:2;
// 编码方式
unsigned encoding:4;
// LRU 时间(相对于 server.lruclock)
unsigned lru:22;
// 引用计数
int refcount;
// 指向对象的值
void *ptr;
} robj;
type 、 encoding 和 ptr 是最重要的三个属性。
type 记录了对象所保存的值的类型,它的值可能是以下常量的其中一个(定义位于 redis.h):
/*
- 对象类型
*/
#define REDIS_STRING 0 // 字符串
#define REDIS_LIST 1 // 列表
#define REDIS_SET 2 // 集合
#define REDIS_ZSET 3 // 有序集
#define REDIS_HASH 4 // 哈希表
encoding 记录了对象所保存的值的编码,它的值可能是以下常量的其中一个(定
redis.h):
/*
* 对象编码
*/
#define REDIS_ENCODING_RAW 0 // 编码为字符串
#define REDIS_ENCODING_INT 1 // 编码为整数
#define REDIS_ENCODING_HT 2 // 编码为哈希表
#define REDIS_ENCODING_ZIPMAP 3 // 编码为 zipmap
#define REDIS_ENCODING_LINKEDLIST 4 // 编码为双端链表
#define REDIS_ENCODING_ZIPLIST 5 // 编码为压缩列表
#define REDIS_ENCODING_INTSET 6 // 编码为整数集合
#define REDIS_ENCODING_SKIPLIST 7 // 编码为跳跃表
ptr 是一个指针,指向实际保存值的数据结构,这个数据结构由 type 属性和 encoding
定。
举 个 例 子, 如 果 一 个 redisObject 的 type 属 性 为 REDIS_LIST , encoding 属
REDIS_ENCODING_LINKEDLIST ,那么这个对象就是一个 Redis 列表,它的值保存在
端链表内,而 ptr 指针就指向这个双端链表;
另 一 方 面, 如 果 一 个 redisObject 的 type 属 性 为 REDIS_HASH , encoding 属
REDIS_ENCODING_ZIPMAP ,那么这个对象就是一个 Redis 哈希表,它的值保存在一个
里,而 ptr 指针就指向这个 zipmap ;
诸如此类。