前言:这节,主要是讲授无人驾驶中的图片处理算法,老套路,论文引入深度学习图片处理算法加项目实战,一样的不懂及不复现。好了,这篇也仅供参考,欢迎各位大佬批评指正。
下面开始激动人心时刻:
1、无人驾驶中的检测

2、基于图片的检测算法基本概述
2.1储备知识:
Classification VS detection (分类vs检测)
Classification:类别
Detection: 类别 、位置

2.2 检测流程
流程:
–位置:先找到所有的ROI(Region of Interest,bounding box my containing object)
–类别:对每一个ROI做分类获取类别信息
–位置修正:Bounding box Regression
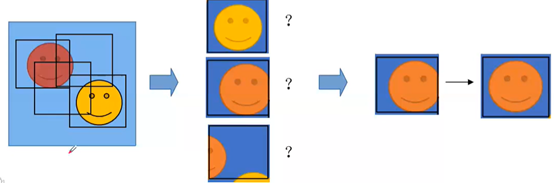
2.3 How to generate ROI
(获取感兴趣区域:针对检测流程中的第一步:位置)
1)Method1: sliding window(滑窗方法)
–all location: up->down left->right
–all different scale and ratio(比率)(far and near objects)
–many invalid boxes, complex computation
–good for fixed aspect ratio objects such as faces or pedestrians(行人)
(从上到下,大概意思就是:从左到右获取很多的框,而且这些框大小不一,并且距离物体的远近比率也不同;不过,这种方式有很多没用的框,需要很复杂的计算;这方法适用于长宽比固定对象,如脸或者行人)
2)Method2:Region proposal(基于分割的方法)
–identify prospective(预期的) objects in an image using segmentation
–reduce the invalid boxes,less pathes to classify
–(典型例子)Selective search: over segmentation,merge adjacent boxes according similarity.
(https://www.learnopencv.com/selective-search-for-object-detection-cpp-python/)
(这方法基于普通分割;减少无用框,方便分类;典型例子,选择搜索,过分割,根据相似度对分割区域进行合并重复多次)
3)Method3:CNN(深度学习方法)
–anchor boxes (similar to sliding windows)(类似滑窗方法)
–RPN(from Faster-RCNN)
2.4 how to classify ROI
(匹配检测流程中的第二步划分类别)
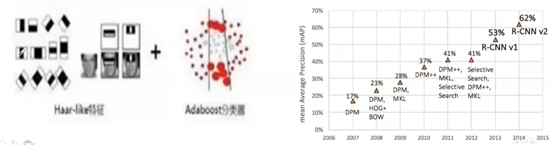
1)Extract feature from ROI(从感兴趣区域里面抽取特征):
–Haar LBP SIFT SURT HOG DPM …(传统方法)
–CNN(conv pooling …)
2)Classifier(分类):
–SVM Adaboost…(传统分类器)
–CNN(softmax …) (神经网络分类器)

2.5小结
1)获取ROI位置方法:
–Sliding window/Slective Search/ …|CNN(RPN …)
2)划分类别方法:
–HOG/DPM/SIFT/LBP/ …|CNN(conv pooling) (特征提取方法)
–SVM/Adaboost/ …|CNN(softmax …) (分类器)
3)位置修正(Bounding box Regression【边界框回归】)
–Linear Regresion/… |CNN(regression …) (回归)
3、基于图片的检测算法(两步)
–two-step:RCNN、SPPnet、Fast-RCNN、Faster-RCNN(这些算法都属于两步法范围)
两步法:
第一步:提取候选框
第二部:分类、回归
(1) 在CNN引入图片处理之前,检测算法的基本操作:
–位置:sliding window(滑窗)/region proposal(提取区域方法)
–类别:HOG/DOM/Haar/SIFT/ … + SVM/Adaboost/ …
–位置修正(Bbox Regression):Linear regression/ …
(2)R-CNN
位置:Selective Search 提取候选框
类别:CNN提取特征+SVM分类
位置修正:Linear Regression

相对传统方法,改进地方是,使用CNN来提取特征
(3)SPPnet
位置: Selective Search提取候选框
类别:CNN提取特征+SVM分类(改进地方还是cnn提取特征这一块)
–共享卷积:大大降低计算量(见下图1右侧;图2是详解共享卷积)
–SPP层:不同尺度的特征->固定特尺度特征(后接全链接层)(见下图1左侧)
位置修正:Linear Regression
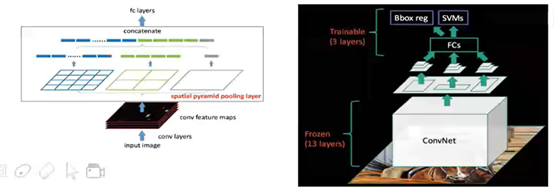
SPPnet相对(2)方法,在提出特征方面,这里是采用一次性卷积完成的(共享卷积),而(2)需要多次卷积

(4)Fast-RCNN
–位置:Selective Search提取候选框
–类别:CNN提取特征+CNN分类(相对前面,创新点在于使用CNN分类)(下方骑马图)
–分类和回归都用CNN实现:两种损失可以反转以实现联动调参(半end-to-end)
–SPP层->ROI pooling:加速计算(图1)
位置修正:CNN回归 (这也是一大创新点)

上图,灰色部分是金字塔里面没有纳入计算部分,只是提取亮色部分(网格划分最细的部分)进行计算,这这里大大提高效率(节省计算量),但会损失精度。
Softmax/bbox regressor这里实现了分类和回归操作

共享卷积提取特征->把特征图框映射到特征图上面->这些特征图通过ry图例得到一个固定尺度(图框),再跟全链接层(fcs)链接,再连接分类(linear+softmax)和回归(linear)【如下图示】
(log loss + smooth Li loss 表示总的损失)

(5)Faster-RCNN
位置:CNN提取候选框
–RPN:Region Proposal Net (较(4)增加了这一层,用于提取特征)
–feature点对应的原图感受野框处生成不同ratio/scale的anchor box
–anchor box(毛点框)二分类+回归
类别:CNN提取特征+CNN分类
位置修正:CNN回归

下图,特征点映射回原图,会对其框进行修正

小结:
根据上面的(2)-(5)算法处理流程,two-step的含义:
第一步:提取候选框
第二部:分类、回归
(6)监督学习:
自动提取的框(预测框),手工绘制的框(真实框),手工框减去自取框有一个差值,这个差值就是模型学习的部分,最后的目的是让训练模型的预测框越来越接近真实框。【个人所理解的表述】
4、基于图片的检测算法(单步)
–one-step:YOLO SSD YOLOv2 YOLOv3
单步,也就是说,没有预选框步骤,直接分类
4.1 YOLO
1)位置:
–Faster-RCNN
1)feature点对应的原图感受野处生成不同的ratio/scale的anchor box
2从anchor box中提取候选框(二分类+回归)
3)再对候选框做回归修正
–YOLO:
1)全图划分为7X7网络,每个网络对应有2个default box
2)没有候选框。直接对default box做全分类+回归(box中心坐标的x、y相对于对应的网格归一化到0-1之间,w、h用图像的width和height归一化到0-1之间)
2) 类别:CNN提取特征+CNN分类
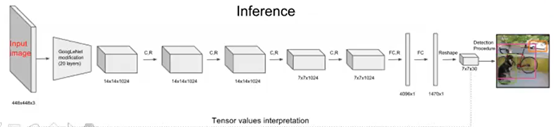

上图,颜色格子做的是多分类,其上方框框图做的是回归
3)YOLO 优缺点:
3-1)优点:实时性
3-2)缺点:
–准确性不高(不如Faster R-CNN):定位精度差(anchor box不够丰富且只能回归修正一次)
–小物体差:anchor的scale不够多样
–不规则物体差:anchor的ratio不够多样
4)

这个图是上面7X7图中每个网格(这里有两个人为指定的先验框,对应上图的两组4,1;回归也是对这两个框进行回归的)对应的30(20+1+4+4+1)个向量,【20个分类结果(图中4、20后面的xywh是写错了的);最上方的4是回归值;1 confidence表示置信度,表示框中包含物体可能性的大小;后面的4,1含义一致】
4.2 SSD
1)位置:
–借鉴RPN的anchor box机制(把预选框数量增多,如图2):feature点对应的原图感受野框处生成不同的ratio/scale default box
–没有候选框,直接对default box做全分类+回归
–多感受野特征层输出(如图1):前面层感受野小,适合小物体,后面层感受野大,适合大物体。

上为图1,下为图2

4.3 YOLOv2
特点:
(1)更丰富的default box(人为指定的先验框)
–从数据集统计出default box(k-means)【先统计一下数据集里同一类物体的框长度和宽度,然后选择平均值作为先验框长度和宽度的标准,如下图3,蓝色就是统计出来的最常见的框】:随着k的增大IOU也在增大(高召回率)但是复杂度也在增加,最终选择K=5;
(2)更灵活的类别预测
–把预测类别的机制从空间位置(cell)中解耦,由default box 同时预测类别和坐标,有效解决物体重叠(对应下图2)
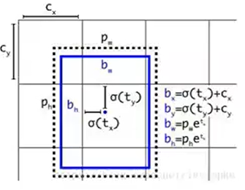
图1
上面的一个网格展示,下面是一个网格对应的是,20类别和两个框,网格来负责20类别,两个框负责回归;下图左侧可见,框和类别被绑定一起的,导致一个网格无论有多少框,都只能识别出一个类别,当物体重叠时,就无法预测了。v2就对v1进行了改进,一个框可以单独预测出自己的物体(这个过程又称为解耦)

上图2,下图3

4.4 YOLOv3
特点:
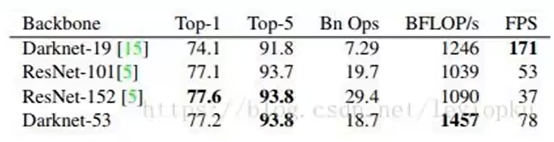
(1)更好的基础网络:
–darknet-19->darknet-53
(2)考虑多尺度:【图2】
–多尺度:感受野多样性/anchor box(default box)多样性
–多感受野特征层输出:上采样融合之后再输出(借鉴feature pyramid networks)【可见这论文在使得特征丰富作用上有效】而SSD是直接输出不融合
–更多default box:LK=9,被3个输出平分3*(5+80)=255
3个box、5个(x,y,w,h,confi)、 80(coco class)
上图1,下图2

4.5小结(含第3章)
图片检测算法主要有:
1)第3章涉及的两步法:
Two step method:
–RCNN(把cnn引入特征提取)、SPPnet(提特征时,共享卷积,降低计算量)、Fast R-CNN(分类回归引入神经网络)、Faster- R-CNN(预选框提取也放到神经网络里面来)、R-FCN、Mask R-CNN(除了做检测之外,添加一个分支做分割)
–End-to-End:Get ROI,Extract feature,Classify,Bbox regression(all CNN)【越来越端对端了,获取感兴趣区域,提取特征,分类,边框回归,都转移到神经网络】
【上述的算法早期都是基caffe框架开源的】
2)第4章介绍的一步法:
One step method:
–OverFeat、YOLO、SSD、YOLO-v2、RetinaNet、YOLO-v3
参考资料:
–《基于深度学习的目标检测(上)》
–《基于深度学习的目标检测(下)》
–https://github.com/hoya012/deep_learning_object_detection(下图链接)

标红色都是值得看的
大佬经验分享:
a、深度学习:工业上发现不好地方,先明确不好点在哪,然后查找学术界相关论文,拿来训练一下自己的模型,看看效果如何。
b、阿波罗项目,使用的就是YOLO,速度比较快。YOLO-v3很不错,速度精度都挺不错。
5、实战:Faster-RCNN
1)材料准备:
源码:https://github.com/andylei77/object-detector/blob/v0.1.0/object_detection_tutorial.py
查看README.md文件:
–下载模型
–运行脚本+指定模型路径
2)源码解析:
import numpy as np
import tensorflow as tf
import argparse
import sys
import os
import time
import cv2
from distutils.version import StrictVersion
from PIL import Image
from matplotlib import pyplot as plt
FLAGS = None
if StrictVersion(tf.__version__) < StrictVersion('1.9.0'):
raise ImportError('Please upgrade your TensorFlow installation to v1.9.* or later!')
from label_utils import label_map_util
def isimage(path):
return os.path.splitext(path)[1].lower() in ['.jpg', '.png', '.jpeg']
def create_graph(model_path):#创建计算图
detection_graph = tf.Graph()#创建一个空图
with detection_graph.as_default():
od_graph_def = tf.GraphDef()#图定义
with tf.gfile.GFile(model_path, 'rb') as fid:#根据路径打开模型文件
serialized_graph = fid.read()#打开图文件,解析到空图定义里面
od_graph_def.ParseFromString(serialized_graph)#把上面序列化图的定义,进行反序列化
tf.import_graph_def(od_graph_def, name='')#将反序列化的图加载到默认图里面
return detection_graph#上面有点迷,个人感觉,作者说可以搜索官方文档进行查看学习
def load_image_into_numpy_array(image):#加载图片并转为numpy格式
(im_width, im_height) = image.size
return np.array(image.getdata()).reshape(
(im_height, im_width, 3)).astype(np.uint8)#把图片格式的形状格式,数据结构变一下,转为numpy格式
def run_inference_for_single_image(image, graph):#接收一个图片和一个计算图
with graph.as_default():#把做好的计算图作为默认计算图
with tf.Session() as sess:#Session函数的作用就是,将前端创建好的计算图graph发给后端(底层)进行解析计算
#后端处理时,只会处理计算图中所依赖的节点
# Get handles to input and output tensors
ops = tf.get_default_graph().get_operations()#从计算图中抓取输入输出节点
all_tensor_names = {
output.name for op in ops for output in op.outputs}
tensor_dict = {
}
for key in [
'num_detections', 'detection_boxes', 'detection_scores',
'detection_classes', 'detection_masks'#tensorflow提供的输出节点
]:
tensor_name = key + ':0'
if tensor_name in all_tensor_names:
tensor_dict[key] = tf.get_default_graph().get_tensor_by_name(
tensor_name)#抓取计算图的节点名称,并放到字典里面
image_tensor = tf.get_default_graph().get_tensor_by_name('image_tensor:0')#通过节点名称获取输入节点的名称
# Run inference
start_time = time.time()
output_dict = sess.run(tensor_dict,
feed_dict={
image_tensor: np.expand_dims(image, 0)})#image_tensor上述抓取的输入节点;expand_dims扩张一个维度
end_time = time.time()
print("run time:", end_time - start_time)#打印运行时间
# all outputs are float32 numpy arrays, so convert types as appropriate
num = int(output_dict['num_detections'][0])#将output_dict的输出结果拿到,并把对应的量值装起来
output_dict['num_detections'] = num
output_dict['detection_classes'] = output_dict['detection_classes'][0].astype(np.uint8)[:num]
output_dict['detection_boxes'] = output_dict['detection_boxes'][0][:num]
output_dict['detection_scores'] = output_dict['detection_scores'][0][:num]#[0][:num]表示截取的是0~num号的框,其他的就属于不关心范围
return output_dict
def main():
# labels
category_index = label_map_util.create_category_index_from_labelmap(FLAGS.label_path, use_display_name=True)
#使用该工具label_map_util,创建类别字典
# create graph
detection_graph = create_graph(FLAGS.model_frozen)
#创建计算图
image_paths = []#判断图片路径是否有文件,最后保存的是图片文件路径
if os.path.isfile(FLAGS.image_path):
image_paths.append(FLAGS.image_path)
else:
for file_or_dir in os.listdir(FLAGS.image_path):
file_path = os.path.join(FLAGS.image_path, file_or_dir)
if os.path.isfile(file_path) and isimage(file_path):
image_paths.append(file_path)
print(image_paths)
for image_path in image_paths:#遍历每个图片路径
# prepare data
image = Image.open(image_path)#使用该库函数打开图片
(image_width, image_height) = image.size#获取图片的宽高
image_np = load_image_into_numpy_array(image)#把图片格式转换为numpy格式
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
# Actual detection.
output_dict = run_inference_for_single_image(image_np, detection_graph)#前项传播(是main函数重点),将numpy格式的图片告诉这个函数,告
#诉该函数使用哪个计算图来执行
#下面为上述函数的输出结果
for i in range(output_dict['num_detections']):
cls_id = output_dict['detection_classes'][i]
cls_name = category_index[cls_id]['name']
score = output_dict['detection_scores'][i]
box_ymin = int(output_dict['detection_boxes'][i][0]*image_height)
box_xmin = int(output_dict['detection_boxes'][i][1]*image_width)
box_ymax = int(output_dict['detection_boxes'][i][2]*image_height)
box_xmax = int(output_dict['detection_boxes'][i][3]*image_width)#这几项读取数据里面详细参数进行处理的
cv2.rectangle(image_np, (box_xmin,box_ymin), (box_xmax,box_ymax), (0,255,0),3)#在图片上画一个矩形框
text = "%s:%.2f" % (cls_name,score)#标示所画的矩形框的得分
cv2.putText(image_np, text, (box_xmin,box_ymin-4),cv2.FONT_HERSHEY_COMPLEX_SMALL, 0.8, (255,0,0))
plt.figure(figsize=(12, 8)) # Size, in inches
plt.imshow(image_np)
plt.show()#显示处理后的图片
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--image_path', type=str,
default='test_images/',
help='image path')#图片路径
parser.add_argument('--model_frozen', type=str,
default='/home/andy/selfdrivingcar/TFMODEL/ssd_mobilenet_v1_coco_2018_01_28/frozen_inference_graph.pb',
help='model path')#模型路径
parser.add_argument('--label_path', type=str,
default='label_utils/mscoco_label_map.pbtxt',
help='label path')#标签路径
FLAGS, unparsed = parser.parse_known_args()
main()
#代码是初始版本,由于每次载入新图片都会初始化一次tf.Session()函数,所以导致每次处理图片都得花费2秒多,很慢!
3)Tensorflow,底层是c++,上层是python、c++或者java;上层和底层通过接口通信(c层);上层的上方是api层,api层又分为底层和高层,tf.convs啥的都属于底层,高层的api时对底层的api进行了封装。
4)软件工程小知识,例子体会:
V0.1.0 软件工程解析:最后一个0位置修改,表示改进一些小bug;中间数字1位置修改,表示有重大的改变;最左边的0修改时候,表示版本已改变
6、答疑环节
1)Yolo精度很差,怎么解决?
答:百度阿波罗采用的是yolo,可能在数据集上面做功夫,训练模型
2)阿波罗基于检测方法来做的跟踪,从而获取前方车辆行驶的轨迹
3)Focal loss ohem可以提高精度原因是,给正样本权重高一些,负权重低一些
4)一般情况,无人驾驶代码都是c++写的,因为速度快
5)Ros实时通信有缺陷,目前满足不了车规级,阿波罗后面都开始去ros化
6)关于调参技巧,南大出了一本神经网络调参的书,有需要可以网购查看
7)工业界使用的模型,不是单纯拿别人训练好的,而是根据自己实际场景需要进行训练的(比如自己采集数据集来进行训练)
8)Coco是一个数据集,tensorflow是一个深度学习框架
9)目前的计算机视觉,只是单纯从图片表面看问题,图片背后隐含信息并没有读取。比如,都是看一张狗的图片,人不仅仅是看图像,可能还知道这狗的主人是谁,价格是多少,这类信息。
10)强大的ai,需要一个强大的知识图谱
11)无人车,可以采用多传感器,获取很多信息,做更好的识别
12)无人车方面算法,基于图片与点云的分割,检测,跟踪,三大块
13)大公司作算法的话,就是针对性写一些算法,训练相应模型
个人小结:
这一章主要介绍了cnn系列目标检测上面应用,并实战了一个案例。里面介绍了不少的图片处理的算法相关的文献,如何使用数据集,在tensorflow框架上面进行深度学习训练。对cnn图片处理有了更大的了解。但是,很遗憾,深度学习框架tensorflow在Ubuntu16.04可能python版本原因,还是什么,现在启动项目还是失败的。目前为止,只有上一节传统方式的车道线识别成功复现,其他牵涉深度学习的都是失败的。
#####################
不积硅步,无以至千里
好记性不如烂笔头
图片版权归原作者所有
感恩授课老师的付出