目录
pandas的series和dataFrame
pandas和numpy的关系:numpy是列表,pandas是字典,pandas基于numpy构建。
Series的形式:索引在左边,值在右边。没有为数据指定索引会自动创建0到N-1(N为长度)的整数型索引。
DataFrame是一个表格型的数据结构,每列可以是不同的值类型,既有行索引也有列索引。

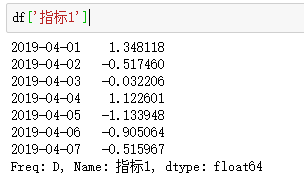
取df的“指标1”列:df['指标1']
创建一组没有给定行标签和列标签的数据:pd.DataFrame(np.arange(12).reshape((3,4)))
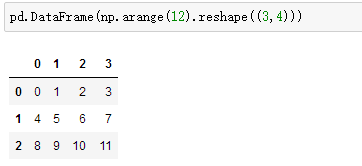
创建对每一列的数据进行特殊对待的数据:

查看数据类型:df.dtypes
查看索引(行)的序号:df.index
查看每种数据(列)的名:df.columns
查看df的所有值:df.values
查看数据的总结(计数、平均值、最值等):df.describe()

翻转数据:df.T
对数据的 index 进行排序:df.sort_index(axis=1, ascending=False)
对数据的 值 进行排序:df.sort_values(by='A')
pandas选择数据
选择某列A: df['A'] 或 df.A
选择0到2多列:df[0:2]
根据标签选择1行:df.loc[0] 【选择索引为0的一行】
选择所有行(: 代表所有行):df.loc[:,['A','B']] 【选择所有行的A、B两列】
df.loc[3,['A','B']] 【选择第3行的A、B两列】
根据位置(索引)进行选择数据:df.iloc[3,1] 【第3行第1列的数据】
df.iloc[2:3,0:3] 【第2到3行,第0到3列的数据】
df.iloc[[0,3],0:3] 【第0、3行,第0到3列的数据】
通过判断的筛选:df[df.A==2] 【选择列A的值为2的行】
pandas设置值
利用索引:df.iloc[2,2] = 1111 【修改第2行、 第2列】
利用标签:df.loc['20190401','B'] = 2222 【修改行‘20190401’、 列‘B’】
根据条件:df.B[df.A>4] = 0 【列A大于4的都改成0】
按行或列:df['F'] = np.nan 【加上新列F,并设值为NaN】
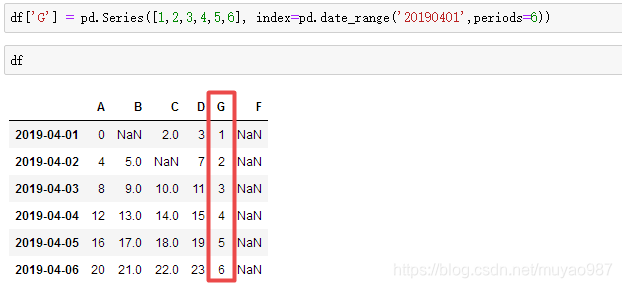
df_original['title_keywords'] = ['' for _ in range(content_num)]添加数据:df['G'] = pd.Series([1,2,3,4,5,6], index=pd.date_range('20190401',periods=6))
pandas处理丢失数据NaN
直接去掉有 NaN 的行或列(pd.dropna()):

将 NaN 的值用其他值代替(pd.fillna()):df.fillna(value=0) 【全替换成0】
判断每个值是否是缺失数据:df.isnull()
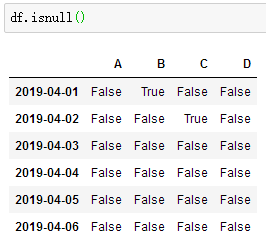
检测整个数据表中是否存在 NaN, 如果存在就返回 True:np.any(df.isnull()) == True
pandas导入导出
pandas可以读取与存取的格式:csv、excel、json、html、pickle等 【官方文档】
读取csv:data = pd.read_csv('student.csv')
将资料存取成pickle:data.to_pickle('student.pickle')
pandas数据合并
concat纵向合并:res = pd.concat([df1, df2, df3], axis=0) 【可以发现索引没变】

concat参数之ignore_index (重置 index) :res = pd.concat([df1, df2, df3], axis=0, ignore_index=True)
concat参数之join (合并方式,默认join='outer') :res = pd.concat([df1, df2], axis=0, join='outer') 【依照column来做纵向合并,有相同的column上下合并在一起,其他独自的column个自成列,原本没有值的位置皆以NaN填充。】
concat参数之join (合并方式,改为join='inner') :res = pd.concat([df1, df2], axis=0, join='inner') 【只有相同的column合并在一起,其他的会被抛弃】
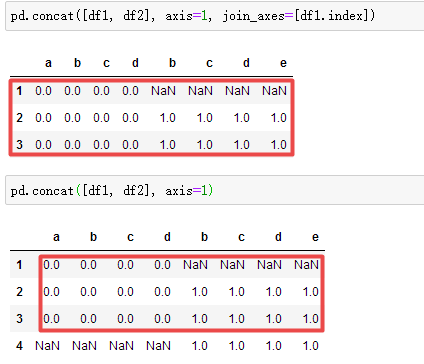
concat参数之join_axes:【根据df1的行索引来join,下图2为去掉join_axes】
append只有纵向合并,没有横向合并:
df1.append(df2, ignore_index=True) 【将df2合并到df1的下面,重置index】
df1.append([df2, df3], ignore_index=True) 【合并多个df,将df2与df3合并至df1的下面,重置index】
df1.append(s1, ignore_index=True) 【合并series,将s1合并至df1,重置index】
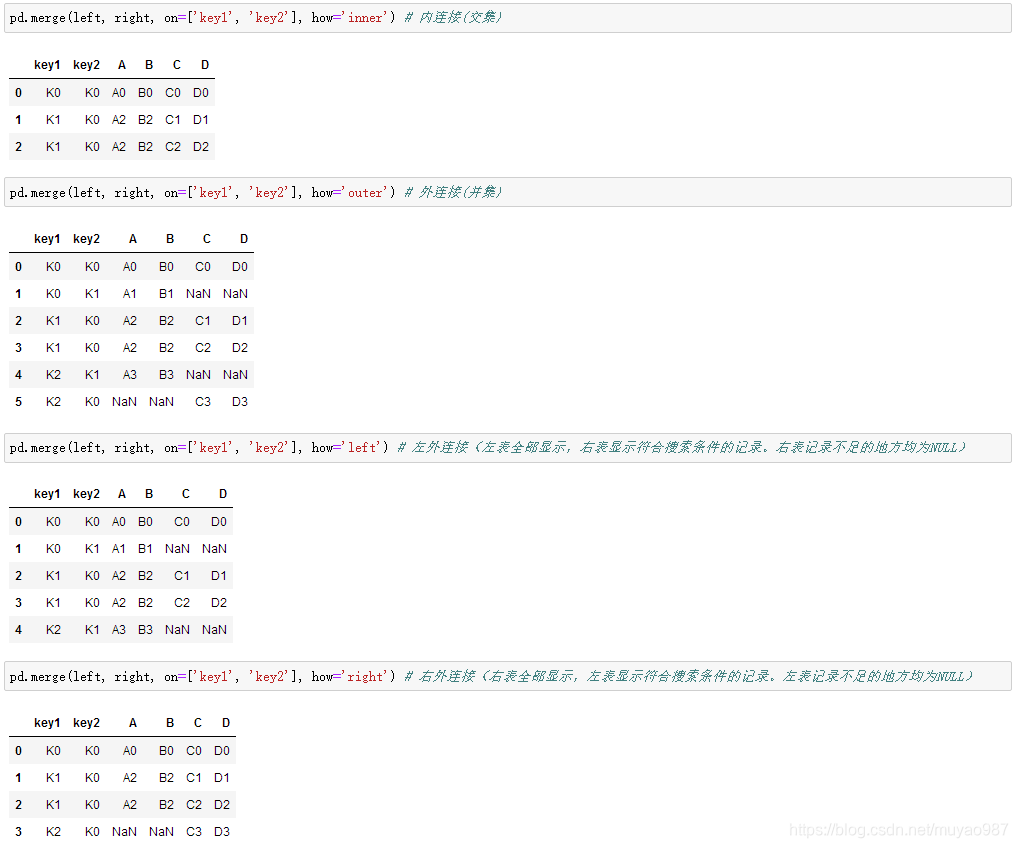
merge用于两组有key column的数据【样例数据如下】

依据key1与key2 columns进行合并,并打印出四种结果['left', 'right', 'outer', 'inner']:
merge参数之indicator=True会将合并的记录放在新的一列
merge参数之indicator=str,自定义列名

根据index合并:res = pd.merge(left, right, left_index=True, right_index=True, how='outer')
merge参数之suffixes解决overlapping(重叠)的问题 【名为K0的有一个1岁男、1个4岁女、1个5岁女】

pandas结合plot绘图
import matplotlib.pyplot as plt
随机生成1000个数据,Series 默认的 index 就是从0开始的整数

生成一个1000*4 的DataFrame,并对他们累加

散点图scatter只有x,y两个属性,我们我们就可以分别给x, y指定数据【下图line1】
再画一个在同一个ax上面,选择不一样的数据列,不同的 color 和 label【下图line2】
显示图片【下图line3】
