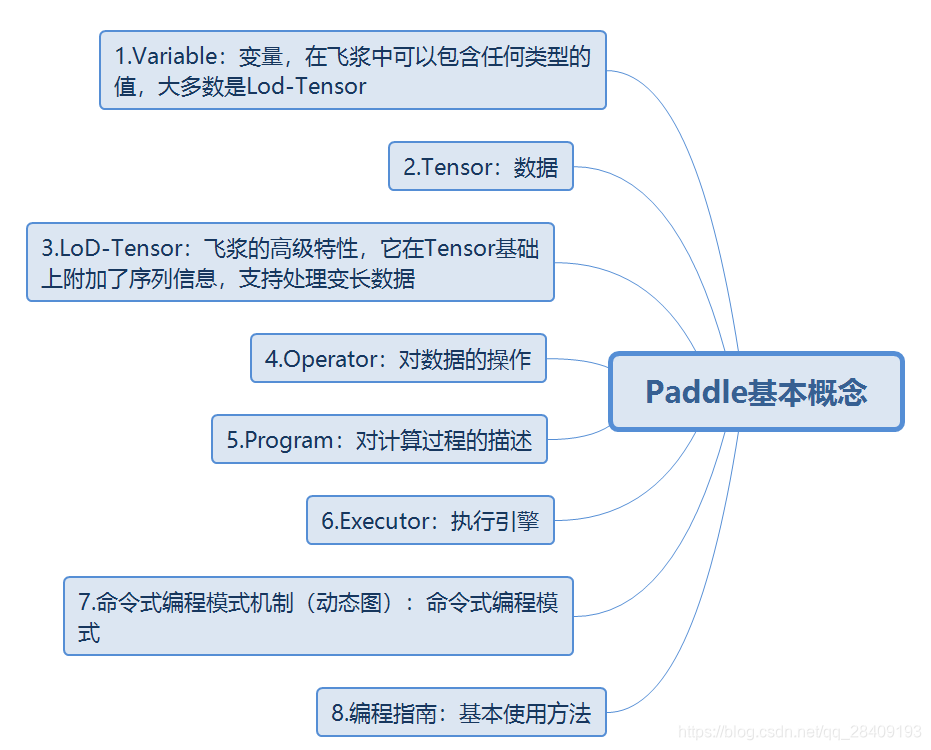
最近报了百度的深度学习认证,需要使用Paddle进行编程实现,找了一些基础教程,特意记录下来,加深印象。思维导图如下:
一、Paddle的内部执行流程
Paddle使用一种编译器式的执行流程,分为编译时和运行时两个部分,具体包括:编译器定义Program,创建Executor运行Program。执行流程图如下:
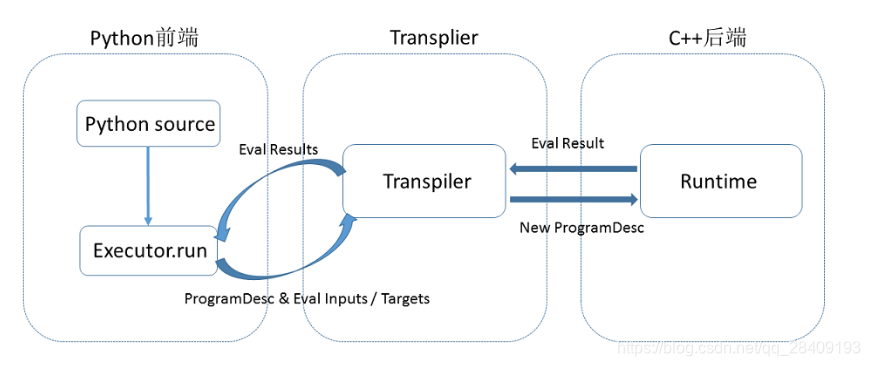
1.编译时,python程序是通过调用Paddle提供的段子,向一段Program中添加变量(Tensor)以及对变量的操作(Operators或者Layers)。用户只需要描述核心的前向计算,不需要关系反向计算、分布式下以及异构设备下如何计算。
2.原始的Program在框架内部转换为中间描述语言:ProgramDesc
3.Transpiler接受一段ProgramDesc,输出一段变化后的ProgramDesc,作为后端Executor最终需要执行的Program。Transpiler并非必需步骤。
4.执行ProgramDesc中定义的Operator(可以类比为程序语言中的指令),在执行过程中会为Operator创建所需的输入输出并进行管理。
二、内部详解
1.Variable(变量)
Variable(变量)可以包含任何类型的值变量,提供的API中用的类型是Tensor。
存在三种Variable:
(1)模型中的可学习参数
例如,神经网络中的权重和偏置会接受优化算法额更新,因此,应该是一个变量类型的数据,表示为:
w = fluid.layers.create_parameter(name="w",shape=[1],dtype='float32')但是,Paddle中大部分的神经网络都是封装好的,可以直接创建权重和偏置,无需显示调用Parameter相关接口来创建。例如:
y = fluid.layers.fc(input=x, size=128, bias_attr=True)其中,fluid.layers.fc是全连接神经网络的API。
(2)占位Variable
在声明式编程模式(静态图)中,组网不知道实际输入的信息,此刻需要一个占位的Variable,表示一个待提供输入的Variable。fluid.data表示需要提供输入Tensor的形状信息,当遇到无法确定的维度时,相应维度指定为None,如下:
import paddle.fluid as fluid
#定义x的维度为[3,None],其中我们只能确定x的第一的维度为3,第二个维度未知,要在程序执行过程中才能确定
x = fluid.data(name="x", shape=[3,None], dtype="int64")
#若图片的宽度和高度在运行时可变,将宽度和高度定义为None。
#shape的三个维度含义分别是:batch_size, channel、图片的宽度、图片的高度
b = fluid.data(name="image",shape=[None, 3,None,None],dtype="float32")dtype是表示数据类型,int64是有符号的64位整数数据类型,可支持的类型如下:

(3)常量Variable
可以通过fluid.layers.fill_constant来实现常量Variable,并可以指定内部的Tensor形状,数据类型和常量值。
import paddle.fluid as fluid
data = fluid.layers.fill_constant(shape=[1], value=0, dtype='int64')2.Tensor
Tensor可以简单理解为多维数组,同一个Tensor每个元素的数据类型是一样的,Tensor的形状是Tensor的维度。
Tensorflow中Tensor(张量)与Numpy的ndarray对象相似,每个Tensor都有一个形状和数据类型,Numpy数组和Tensor的区别是:
(1)张量可以有加速器内存(CPU,GPU)支持
(2)张量是不变的
下图直观的表达了1~6维的Tensor:

对于一些任务中batch内样本大小不一致的问题,Paddle提供了两种解决方案:
(1)padding:将大小不一致的样本padding到同样的大小。
(2)Lod-Tensor:记录每一个样本的大小,减少无用的计算量,Lod牺牲灵活性来提升性能。当样本无法通过分桶、排序等方式使得大小接近,可以用Lod-Tensor。
Tensor的API有:
- create_tensor:创建一个指定数据类型的Lod-Tensor变量
- create_parameter:创建一个可学习的参数
- create_grobal_var:创建一个全局的tensor
- cast:将数据转换为指定类型
- concat:将输入数据沿指定维度连接
- sums:对输入数据加和
- fill_constant:创建一个具有特定形状和类型的tensor,可以通过value设置该变量的初始值
- assign:复制一个变量
- argmin:计算输入tensor指定轴上最小元素的索引
- argmax:计算输入tensor指定轴上最大元素的索引
- argsort:对输入Tensor在指定轴上进行排序,并返回排序后的数据变量及其对应的索引值
- ones:创建一个指定大小和数据类型的Tensor,且初始值为1
- zeros:创建一个指定大小和数据类型的Tensor,且初始值为0
- reverse:使用reverse沿指定轴反转Tensor
3.Lod-Tensor
在nlp任务中,一个batch中包含N个句子,句子的长度不一,为了解决长度不一致的问题,Paddle提供了两种方案:(1)padding,(2)Lod-Tensor,tensor中同时保存序列的长度信息。
对于padding的方式,会增加框架的计算量,但是可以通过分桶,排序等机制,使得一个batch内的句子长度尽可能接近,能够降低padding的比例,还通过引入mask来记录padding 信息,来移除padding对于训练效果的影响。
但是对于一些nlp任务,例如聊天任务,需要计算query(问题)和多个答案之间的相似度,且答案都是在一个batch中,就可以采用Lod-Tensor方式,Lod-Tensor存储了样本的长度信息,不需要增加padding的词。
Lod-Tensor是将长度不一致的维度拼接为一个大的维度,并引入了一个索引数据结构(LoD)来将张量分割成序列。
4.Operator(算子)
所有对数据的操作都由Operator表示,在paddle.fluid.layers,paddle.fluid.nets模块中。例如:利用paddle.fluid.layers.elementwise_add()实现加法:
import paddle.fluid as fluid
import numpy
a = fluid.data(name="a",shape=[1],dtype='float32')
b = fluid.data(name="b",shape=[1],dtype='float32')
result = fluid.layers.elementwise_add(a,b)
# 定义执行器,并且制定执行的设备为CPU
cpu = fluid.core.CPUPlace()
exe = fluid.Executor(cpu)
exe.run(fluid.default_startup_program())
x = numpy.array([5]).astype("float32")
y = numpy.array([7]).astype("float32")
outs = exe.run(
feed={'a':x,'b':y},
fetch_list=[a,b,result])
# 打印输出结果,[array([12.], dtype=float32)]
print( outs )输出结果为:
[array([5.], dtype=float32), array([7.], dtype=float32), array([12.], dtype=float32)]
在程序语言中,控制流(control flow)决定了语句的执行顺序,常见的控制流包括顺序执行、分支和循环等。
(1)If-else条件分支
条件分支,允许对同一个batch的输入,根据给定的条件,分别选择true_block或false_block中的逻辑执行,执行后再将两个分支的输出合并为一个输出。
(2)Switch
多分支选择结构,如同程序语言中常见的switch-case声明,其根据输入表达式的取值不同,选择不同的分支执行。Fluid所定义的控制流的特性有:
- case的条件是个bool类型的值,即在Program中是一个张量类型的Variable;
- 依次检查逐个case,选择第一个满足条件的case执行,完成执行后即退出所属的block;
- 如果所有case均不满足条件,会选择默认的case进行执行
(3)while
While 循环,当条件判断为真时,循环执行 While 控制流所属 block 内的逻辑,条件判断为假时退出循环。与之相关的API有
- increment :累加API,通常用于对循环次数进行计数;
- array_read :从
LOD_TENSOR_ARRAY中指定的位置读入Variable,进行计算; - array_write :将 Variable 写回到
LOD_TENSOR_ARRAY指定的位置,存储计算结果。
(4)DynamicRNN
动态RNN可处理一个batch不等长的序列数据,其接受lod_level=1的Variable作为输入,在DynamicRNNde block内,用户需自定义RNN的单步计算逻辑。在每一时间步,用户可将需记忆的状态写入到DynamicRNN的merory中,并将需要的输出写出到其output中。
(5)StaticRNN
静态RNN,只能处理固定长度的序列数据,接受 lod_level=0 的 Variable 作为输入。与 DynamicRNN 类似,在RNN的每单个时间步,用户需自定义计算逻辑,并可将状态和输出写出
5.Program
用Program的形式动态描述整个计算过程。这种描述方式,兼具网络结构修改的灵活性和模型搭建的便捷性,在保证性能的同时极大地提高了框架对模型的表达能力。
用户定义的Operator会被顺序的放入Program中,在网络搭建过程中,由于不能使用python的控制流,Paddle通过同时提供分布和循环两类控制流op结构的支持,让用户可以通过组合描述任意复杂的模型。
顺序执行:
x = fluid.data(name='x',shape=[None, 13], dtype='float32')
y_predict = fluid.layers.fc(input=x, size=1, act=None)
y = fluid.layers.data(name='y', shape=[1], dtype='float32')
cost = fluid.layers.square_error_cost(input=y_predict, label=y)Fluid中还有switch,if else类来实现条件选择。
Program设计思想
用户完成网络定义后,一段Paddle程序中通常会存在2个Program:
1.fluid.default_startup_program:定义了模型参数初始化、优化器参数初始化、reader初始化等各种操作。
2.fluid.default_main_program:定义了神经网络模型、前向反向计算,以及模型参数更新、优化器参数更新等各种操作。
Program的基本结构
Paddle的Program的基本结构是一些嵌套的blocks,形式上类似一段C++或Java程序。blocks的概念和通用程序一样。blocks中包含:(1)本地变量的定义,(2)一系列的Operator
import paddle.fluid as fluid
x = fluid.data(name='x', shape=[1], dtype='int64') # block 0
y = fluid.data(name='y', shape=[1], dtype='int64') # block 0
def true_block():
return fluid.layers.fill_constant(dtype='int64', value=1, shape=[1]) # block 1
def false_block():
return fluid.layers.fill_constant(dtype='int64', value=0, shape=[1]) # block 2
condition = fluid.layers.less_than(x, y) # block 0
out = fluid.layers.cond(condition, true_block, false_block) # block 0BlocksDesc和ProgramDesc
用户描述的block和Program信息在Paddle中以protobuf格式保存,在framework.proto中,在Paddle中被称为BlockDesc和ProgramDesc.BlockDesc和ProgramDesc的概念类似于一个抽象语法树。
BlocksDesc中包含本地变量的定义vars,和一系列的Operator ops:
message BlockDesc {
required int32 idx = 1;
required int32 parent_idx = 2;
repeated VarDesc vars = 3;
repeated OpDesc ops = 4;
}parent_idx表示父块,因此block中的操作符可以引用本地定义的变量,也可以 引用祖先块中的定义
Program中的每层block都被压平并存储在数组中。并通过Blocks ID进行索引。
message ProgramDesc {
repeated BlockDesc blocks = 1;
}Blocks的Operator
If-else的Operator包含两个block——True分支和false分支。
6.Executor(执行器)
Paddle的设计思想类似于高级编程语言C++和java等,程序的执行过程被分为编译过程和执行过程。用户完成对Program的定义后,Executor接受这段Program并转换为C++后端真正可执行的FluidProgram,这个叫编译。编译过后需要用Executor进行执行编译好的FluidProgram。
Executor 在运行时将接受一个ProgramDesc、一个block_id和一个Scope。ProgramDesc是block的列表,每一项包含block中所有参数和operator的protobuf定义;block_id指定入口块;Scope是所有变量实例的容器。
其中 Scope 包含了 name 与 Variable 的映射,所有变量都被定义在 Scope 里。大部分API会默认使用 global_scope ,例如 Executor.run ,您也可以指定网络运行在某个特定的 Scope 中,一个网络可以在不同的 Scope内运行,并在该 Scope 内更新不同的 Variable。
完成的编译执行的具体过程如下图所示:
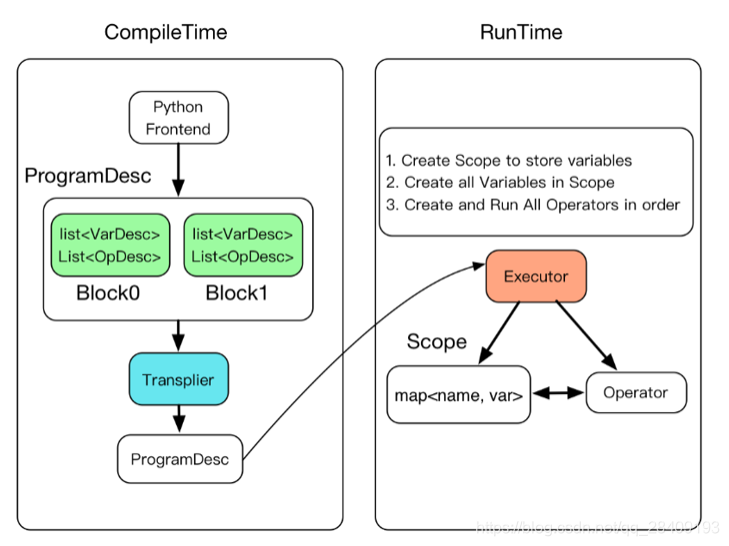
- Executor 为每一个block创建一个Scope,Block是可嵌套的,因此Scope也是可嵌套的。
- 创建所有Scope中的变量。
- 创建并执行所有operator。
(1)创建Executor
#使用CPU
cpu=fluid.CPUPlace()
#创建执行器
exe = fluid.Executor(cpu)(2)运行Executor
正式训练之前,需先执行参数初始化。
#参数初始化
exe.run(fluid.default_startup_program())由于传入数据和传出数据存在多列,因此Paddle通过feed映射定义数据的传输数据,通过fetch_list取出结果。
x = numpy.random.random(size=(10, 1)).astype('float32')
outs = exe.run(
feed={'X': x},
fetch_list=[loss.name])7.命令式编程
从编程范式上说,飞浆兼容支持声明式编程(静态图)和命令式编程(动态图),在飞浆的设计中,把一个神经网络定义成一段类似程序的描述,也就是用户在写程序的过程中,就定义了模型表达及计算。在静态图的控制流实现方面,飞浆用了自己的控制流OP,这使得在飞浆中的定义的program即一个网络模型,可以有一个内部表达,是可以全局优化编译执行的,同时也提供了Python原生控制流,并通过解释方式执行,这就是命令式编程模式。(是不是没看懂,我也没)
声明式编程:先编译后执行,用户需预先定义完整的网络结构,再对网络结构进行编译优化,然后执行获得结果。
命令式编程:解析式执行,每写一行代码,即可获得计算结果
声明式编程存在的问题:
- 采用先编译后执行的方式,组网阶段和执行阶段割裂,导致调试不方便。
- 属于一种符号化的编程方式,要学习新的编程方式,有一定的入门门槛。
- 网络结构固定,对于一些树结构的任务支持的不够好。
命令式编程的优势:
- 代码运行完成后,可以立马获取结果,支持使用 IDE 断点调试功能,使得调试更方便。
- 属于命令式的编程方式,与编写Python的方式类似,更容易上手。
- 网络的结构在不同的层次中可以变化,使用更灵活。
两者之间的代码对比:
import numpy as np
import paddle.fluid as fluid
from paddle.fluid.dygraph.base import to_variable
main_program = fluid.Program()
startup_program = fluid.Program()
with fluid.program_guard(main_program=main_program, startup_program=startup_program):
# 利用np.ones函数构造出[2*2]的二维数组,值为1
data = np.ones([2, 2], np.float32)
# 静态图模式下,使用layers.data构建占位符用于数据输入
x = fluid.layers.data(name='x', shape=[2], dtype='float32')
print('In static mode, after calling layers.data, x = ', x)
# 静态图模式下,对Variable类型的数据执行x=x+10操作
x += 10
# 在静态图模式下,需要用户显示指定运行设备
# 此处调用fluid.CPUPlace() API来指定在CPU设备上运行程序
place = fluid.CPUPlace()
# 创建“执行器”,并用place参数指明需要在何种设备上运行
exe = fluid.Executor(place=place)
# 初始化操作,包括为所有变量分配空间等,比如上面的‘x’,在下面这行代码执行后才会被分配实际的内存空间
exe.run(fluid.default_startup_program())
# 使用执行器“执行”已经记录的所有操作,在本例中即执行layers.data、x += 10操作
# 在调用执行器的run接口时,可以通过fetch_list参数来指定要获取哪些变量的计算结果,这里我们要获取‘x += 10’执行完成后‘x’的结果;
# 同时也可以通过feed参数来传入数据,这里我们将data数据传递给‘fluid.layers.data’指定的‘x’。
data_after_run = exe.run(fetch_list=[x], feed={'x': data})
# 此时我们打印执行器返回的结果,可以看到“执行”后,Tensor中的数据已经被赋值并进行了运算,每个元素的值都是11
print('In static mode, data after run:', data_after_run)
# 开启动态图模式
with fluid.dygraph.guard():
# 动态图模式下,将numpy的ndarray类型的数据转换为Variable类型
x = fluid.dygraph.to_variable(data)
print('In DyGraph mode, after calling dygraph.to_variable, x = ', x)
# 动态图模式下,对Variable类型的数据执行x=x+10操作
x += 10
# 动态图模式下,调用Variable的numpy函数将Variable类型的数据转换为numpy的ndarray类型的数据
print('In DyGraph mode, data after run:', x.numpy())静态图结果输出:
In static mode, after calling layers.data, x = name: "x"
type {
type: LOD_TENSOR
lod_tensor {
tensor {
data_type: FP32
dims: -1
dims: 2
}
lod_level: 0
}
}
persistable: false
In static mode, data after run: [array([[11., 11.],
[11., 11.]], dtype=float32)]动态图结果输出:
In DyGraph mode, after calling dygraph.to_variable, x = name generated_var_0, dtype: VarType.FP32 shape: [2, 2] lod: {}
dim: 2, 2
layout: NCHW
dtype: float
data: [1 1 1 1]
In DyGraph mode, data after run: [[11. 11.]
[11. 11.]]8.编程指南
展示一个完成的编程实例。
# 加载库
import paddle.fluid as fluid
import numpy
# 定义输入数据
train_data=numpy.array([[1.0],[2.0],[3.0],[4.0]]).astype('float32')
y_true = numpy.array([[2.0],[4.0],[6.0],[8.0]]).astype('float32')
# 组建网络
x = fluid.data(name="x",shape=[None, 1],dtype='float32')
y = fluid.data(name="y",shape=[None, 1],dtype='float32')
y_predict = fluid.layers.fc(input=x,size=1,act=None)
# 定义损失函数
cost = fluid.layers.square_error_cost(input=y_predict,label=y)
avg_cost = fluid.layers.mean(cost)
# 选择优化方法
sgd_optimizer = fluid.optimizer.SGD(learning_rate=0.01)
sgd_optimizer.minimize(avg_cost)
# 网络参数初始化
cpu = fluid.CPUPlace()
exe = fluid.Executor(cpu)
exe.run(fluid.default_startup_program())
# 开始训练,迭代100次
for i in range(100):
outs = exe.run(
feed={'x':train_data, 'y':y_true},
fetch_list=[y_predict, avg_cost])
# 输出训练结果
print (outs)输出结果为:
[array([[2.2075021], [4.1005487], [5.9935956], [7.8866425]], dtype=float32), array([0.01651453], dtype=float32)]