文章目录
一、环境描述
1.1 服务部署规划
| 服务器名称 | IP地址 | 服务配置 |
|---|---|---|
| mdw | 172.16.104.11 | grafana、prometheus、ck |
| sdw1 | 172.16.104.12 | chproxy、ck、zk |
| sdw2 | 172.16.104.13 | ck、zk |
| sdw3 | 172.16.104.14 | ck、zk |
本地环境资源有所限制,生产环境建议不同的服务分别部署在不同的服务器上。
1.2 CK集群设置
┌─cluster──────┬─shard_num─┬─shard_weight─┬─replica_num─┬─host_name─┬─host_address──┬─port─┬─is_local─┬─user────┬─default_database─┬─errors_count─┬─estimated_recovery_time─┐
│ shard2_repl1 │ 1 │ 1 │ 1 │ mdw │ 172.16.104.11 │ 9000 │ 1 │ default │ │ 0 │ 0 │
│ shard2_repl1 │ 1 │ 1 │ 2 │ sdw1 │ 172.16.104.12 │ 9000 │ 0 │ default │ │ 0 │ 0 │
│ shard2_repl1 │ 2 │ 1 │ 1 │ sdw2 │ 172.16.104.13 │ 9000 │ 0 │ default │ │ 0 │ 0 │
│ shard2_repl1 │ 2 │ 1 │ 2 │ sdw3 │ 172.16.104.14 │ 9000 │ 0 │ default │ │ 0 │ 0 │
└──────────────┴───────────┴──────────────┴─────────────┴───────────┴───────────────┴──────┴──────────┴─────────┴──────────────────┴──────────────┴─────────────────────────┘
二、chproxy的使用
2.1 chproxy的优势
1、原生clickhouse集群的缺点
- ck通过本地表和分布式表来完成分布式查询与写入,这就导致语句执行初始数据库节点(配合zk进行协调处理操作)进行数据下发时产生大量的网络带宽消耗;
- 对于分布式表的写入,数据会先在分布式表所在的机器进行落盘,然后异步的发送到本地表所在机器进行存储,中间没有一致性的校验,存在数据一致性风险;
- 对于分布式表的写入,分布式表所在机器时如果机器出现down机,会存在数据丢失风险;
- 某些场景下,使用原生分布式表,会导致分片节点上数据写入分布不均匀;
- 谨慎使用on cluster的SQL,目前该语法还不是很完善,某些情况下会导致SQL hang住的情况;
- 对于分布式表的使用,建议只再个别节点创建,专门用来进行分布式查询操作;
2、chproxy的优化
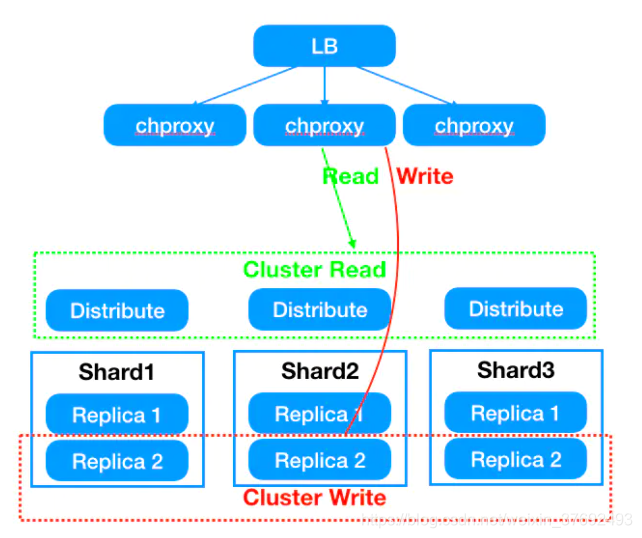
- 直接通过chproxy进行轮询路由,将数据直接写入本地表,避免原生分布式表可能会产生的数据一致性、数据丢失的风险;
- 直接通过chproxy进行轮询路由,避免多分片表节点数据分布不均;
- 直接通过chproxy进行轮询路由,避免语句执行初始数据库节点进行数据下发时,产生的成倍的网络带宽消耗;
- chproxy可将ck集群划分为多个逻辑集群,不同逻辑集群按需进行配置(不同逻辑指定CK集群内指定节点,将数据写入、查询进行逻辑上的隔离,避免资源影响干扰等)
- 在Chproxy上层挂在负载均衡,可做到chproxy层面的高可用,也可横向扩展业务能力
- 对逻辑用户进行查询、访问、安全等限制;
2.2 Clickhouse集群安装部署
可参考文档:CK集群搭建部署
2.3 chproxy安装部署
1、软件安装
# wget -c https://github.com/Vertamedia/chproxy/releases/download/v1.14.0/chproxy-linux-amd64-v1.14.0.tar.gz
# tar xf chproxy-linux-amd64-v1.14.0.tar.gz
2、编写chproxy配置文件
# mkdir -pv /data/chproxy
# touch /data/chproxy/config.yml
# vim /data/chproxy/config.yml
log_debug: false # debug日志
hack_me_please: true
# cache设置,可设置长期缓存或者短期缓存,按组区分
caches: # 缓存设置
- name: "longterm"
dir: "/data/chproxy/longterm/cachedir"
max_size: 100Gb
expire: 1h
grace_time: 20s
- name: "shortterm"
dir: "/data/chproxy/shortterm/cachedir"
max_size: 100Mb
expire: 10s
# 网络白名单组,按组区分
network_groups: # 白名单组,可设置多个白名单组
- name: "cluster_internal"
networks: ["172.16.104.0/24"]
- name: "office_addrs"
networks: ["192.168.102.0/24"]
# 参数设置,按组区分
param_groups: # 参数组,可设置多个参数
- name: "cron-job"
params:
- key: "max_memory_usage"
value: "40000000000"
- key: "max_bytes_before_external_group_by"
value: "20000000000"
- name: "web"
params:
- key: "max_memory_usage"
value: "5000000000"
- key: "max_columns_to_read"
value: "30"
- key: "max_execution_time"
value: "30"
# chproxy server相关设置,一般分为http、https、metrics
server:
http:
listen_addr: ":9090" # chproxy 服务监听端口
allowed_networks: ["office_addrs", "cluster_internal"] # 允许访问chproxy服务白名单
read_timeout: 5m
write_timeout: 10m
idle_timeout: 20m
metrics:
allowed_networks: ["office_addrs", "cluster_internal"] # 暴露给prometheus使用的白名单
# 用户设置,按组区分
users:
- name: "web" # chproxy 用户名
password: "123456" # chproxy 密码
to_cluster: "chproxy_ck_cluster_1" # 用户可访问的cluster名称
to_user: "web" # chproxy用户对应的ck用户
deny_http: false # 是否允许http请求
allow_cors: true
requests_per_minute: 20 # 限制该用户每分钟请求次数
# cache: "longterm" # 使用缓存,若使用缓存,查询优先走缓存,而不是按照规则轮询
params: "web" # 应用“web”指定的参数集
max_queue_size: 100 # 最大队列数
max_queue_time: 35s # 队列最大等待时间
- name: "default" # chproxy 用户
to_cluster: "chproxy_ck_cluster_2" # 不同的chproxy用户,可对应不同的cluster集群
to_user: "default"
allowed_networks: ["office_addrs", "cluster_internal", "172.16.104.12"]
max_concurrent_queries: 4
max_execution_time: 1m
deny_https: false
# 逻辑集群设置,按组区分
clusters:
- name: "chproxy_ck_cluster_1" # chproxy 集合名称
scheme: "http" # 请求类型,http/https
nodes: ["mdw:8123","sdw2:8123"] # 集群可访问节点,http使用端口默认为8123,https使用端口默认为8443,查看ck服务的config.xml配置文件查询
heartbeat: # 集群内部心跳检测定义
interval: 1m
timeout: 10s
request: "/?query=SELECT%201%2B1"
response: "2\n"
kill_query_user: # 达到上限自动执行kill用户
name: "default"
password: ""
users:
- name: "web" # 集群对应chproxy用户信息
password: "123456"
max_concurrent_queries: 4
max_execution_time: 1m
- name: "chproxy_ck_cluster_2" # chproxy 集群2名称,可从逻辑上定义多个集群
scheme: "http"
replicas: # 集群可访问节点
- name: "replica1"
nodes: ["mdw:8123", "sdw1:8123"]
- name: "replica2"
nodes: ["sdw2:8123", "sdw3:8123"]
users:
- name: "default"
max_concurrent_queries: 4
max_execution_time: 1m
一些配置信息注意点:
1)用户配置
- chproxy中定义了两种类型的用户:in-users、out-users
- in-users是指chproxy中逻辑上定义的用户,out-users是指ck中真实创建的用户
- 1个out-users可以对应1个或多个in-users,一些查询的限制如最大并发、最差查询时间等可以在out-users层做限制
2)集群设置
- chproxy集群可设置1个或多个逻辑集群,每个逻辑集群必须包含一个名称和节点列表、或者副本节点列表
- 对集群节点、副本节点之间的请求采用的是 round-robin + least-loaded 的均衡方式
- 如果在近期对某个节点请求不成功,该节点在很短的时间间隔内优先度会被自动降低。这意味着 chproxy 在每次请求中,会自动选择副本负载最小的健康节点
- 集群内部可通过心跳检测来检查各个节点的可用性,业务请求的路由会自动排除不可用节点
- 集群可通过kill_query_user的设置,自动kill掉达到 max_execution_time 限制的查询
- 若集群没有指定用户,默认使用default用户
3)缓存设置
- chproxy支持配置缓存设置,有利于加快查询速率
- 缓存可大致分为长期缓存和短期缓存
- 添加缓存后,请求会优先通过缓存查询返回结果集,一定程度上会看似各个请求路由不均衡,但是不影响整体的集群性能
4)安全设置
- hack_me_please默认情况下启动安全检查
- 可配置访问对象白名单
- 支持https
3、chproxy服务启动
# ./chproxy -config=/data/chproxy/config.yml >> /data/chproxy/error.log 2>&1 &
[1] 32538
2.4 chproxy功能测试
1、遍历查询测试
[root@sdw3 ~]# echo 'select * from system.clusters' | curl 'http://172.16.104.12:9090/?user=default&password=' --data-binary @-
shard2_repl1 1 1 1 mdw 172.16.104.11 9000 0 default 0 0
shard2_repl1 1 1 2 sdw1 172.16.104.12 9000 0 default 0 0
shard2_repl1 2 1 1 sdw2 172.16.104.13 9000 1 default 0 0
shard2_repl1 2 1 2 sdw3 172.16.104.14 9000 0 default 0 0
[root@sdw3 ~]# echo 'select * from system.clusters' | curl 'http://172.16.104.12:9090/?user=default&password=' --data-binary @-
shard2_repl1 1 1 1 mdw 172.16.104.11 9000 1 default 0 0
shard2_repl1 1 1 2 sdw1 172.16.104.12 9000 0 default 0 0
shard2_repl1 2 1 1 sdw2 172.16.104.13 9000 0 default 0 0
shard2_repl1 2 1 2 sdw3 172.16.104.14 9000 0 default 0 0
[root@sdw3 ~]# echo 'select * from system.clusters' | curl 'http://172.16.104.12:9090/?user=default&password=' --data-binary @-
shard2_repl1 1 1 1 mdw 172.16.104.11 9000 0 default 0 0
shard2_repl1 1 1 2 sdw1 172.16.104.12 9000 0 default 0 0
shard2_repl1 2 1 1 sdw2 172.16.104.13 9000 0 default 0 0
shard2_repl1 2 1 2 sdw3 172.16.104.14 9000 1 default 0 0
[root@sdw3 ~]# echo 'select * from system.clusters' | curl 'http://172.16.104.12:9090/?user=default&password=' --data-binary @-
shard2_repl1 1 1 1 mdw 172.16.104.11 9000 0 default 0 0
shard2_repl1 1 1 2 sdw1 172.16.104.12 9000 1 default 0 0
shard2_repl1 2 1 1 sdw2 172.16.104.13 9000 0 default 0 0
shard2_repl1 2 1 2 sdw3 172.16.104.14 9000 0 default 0 0
[root@sdw3 ~]# echo 'select * from system.clusters' | curl 'http://172.16.104.12:9090/?user=web&password=123456' --data-binary @-
shard2_repl1 1 1 1 mdw 172.16.104.11 9000 1 default 0 0
shard2_repl1 1 1 2 sdw1 172.16.104.12 9000 0 default 0 0
shard2_repl1 2 1 1 sdw2 172.16.104.13 9000 0 default 0 0
shard2_repl1 2 1 2 sdw3 172.16.104.14 9000 0 default 0 0
[root@sdw3 ~]# echo 'select * from system.clusters' | curl 'http://172.16.104.12:9090/?user=web&password=123456' --data-binary @-
shard2_repl1 1 1 1 mdw 172.16.104.11 9000 0 default 0 0
shard2_repl1 1 1 2 sdw1 172.16.104.12 9000 0 default 0 0
shard2_repl1 2 1 1 sdw2 172.16.104.13 9000 1 default 0 0
shard2_repl1 2 1 2 sdw3 172.16.104.14 9000 0 default 0 0
三、chproxy监控
3.1 安装grafana
1、软件包安装
# tar xf grafana-7.1.5.linux-amd64.tar.gz -C /usr/local
2、服务启动
# ./grafana-server &
3、服务验证
grafana默认监听端口号为3000,访问http://172.16.104.11:3000/进行验证。初始账号密码为: admin/admin
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7FCLHVFH-1615029258561)(http://note.youdao.com/yws/res/80721/B978CBF7CCC84475A9D6E68732E6414B)]](https://img-blog.csdnimg.cn/20210306191717969.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl8zNzY5MjQ5Mw==,size_16,color_FFFFFF,t_70)
3.2 安装prometheus
1、软件包安装
# tar xf prometheus-2.21.0.linux-amd64.tar.gz -C /usr/local
2、修改配置文件
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'clickhouse-chproxy'
scrape_interval: 10s
static_configs:
- targets: ['172.16.104.12:9090'] # 监听 chproxy 服务的IP:Port
3、启动服务
# ./prometheus &
4、服务验证
grafana默认监听端口号为9090,访问http://172.16.104.11:9090/targets进行验证,查看job状态是否正常。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Lj23YjGT-1615029258565)(http://note.youdao.com/yws/res/80742/FE3A896A8EBF4FE28E537CF12584F0C8)]](https://img-blog.csdnimg.cn/20210306191735971.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl8zNzY5MjQ5Mw==,size_16,color_FFFFFF,t_70)
3.3 配置chproxy监控
1、导入chproxy监控模版
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QXG4CRMb-1615029258567)(http://note.youdao.com/yws/res/80744/EAAC793EA51B4E6BB7CD6FC599B5A7B4)]](https://img-blog.csdnimg.cn/20210306191753818.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl8zNzY5MjQ5Mw==,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-prhZSVJC-1615029258570)(http://note.youdao.com/yws/res/80748/82784E80F21D479885AC4ED5C74531B8)]](https://img-blog.csdnimg.cn/20210306191806334.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl8zNzY5MjQ5Mw==,size_16,color_FFFFFF,t_70)
2、json模版内容如下
https://github.com/Vertamedia/chproxy/blob/master/chproxy_overview.json
3、效果测试
1)手动通过chproxy进行一些数据操作
[root@sdw3 ~]# echo 'insert into db1.t1 select * from numbers(1000000);' | curl 'http://172.16.104.12:9090/?user=default&password=' --data-binary @-
[root@sdw3 ~]# echo 'insert into db1.t1 select * from numbers(1000000);' | curl 'http://172.16.104.12:9090/?user=default&password=' --data-binary @-
[root@sdw3 ~]# echo 'insert into db1.t1 select * from numbers(1000000);' | curl 'http://172.16.104.12:9090/?user=default&password=' --data-binary @-
[root@sdw3 ~]# echo 'insert into db1.t1 select * from numbers(1000000);' | curl 'http://172.16.104.12:9090/?user=default&password=' --data-binary @-
[root@sdw3 ~]# echo 'insert into db1.t1 select * from numbers(1000000);' | curl 'http://172.16.104.12:9090/?user=default&password=' --data-binary @-
[root@sdw3 ~]# echo 'insert into db1.t1 select * from numbers(1000000);' | curl 'http://172.16.104.12:9090/?user=default&password=' --data-binary @-
[root@sdw3 ~]# echo 'insert into db1.t1 select * from numbers(1000000);' | curl 'http://172.16.104.12:9090/?user=default&password=' --data-binary @-
2)查看监控
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-coKVPhBR-1615029258572)(http://note.youdao.com/yws/res/80751/7E961E0DBC20427FB36D3CD11FCD29FC)]](https://img-blog.csdnimg.cn/20210306191828210.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl8zNzY5MjQ5Mw==,size_16,color_FFFFFF,t_70)
参考文档:
https://github.com/Vertamedia/chproxy
https://www.jianshu.com/p/9498fedcfee7