ConcurrentSkipListMap的使用场景
有了ConcurrentHashMap了,我们还需要设计其他并发容器么?
没错,ConcurrentHashMap无法保证我们存储数据的有序性。
假设现在有这么一个需求。我们现在有一个教育系统,这个教育系统对应了无数学生上传自己的数学成绩。学生上传的数据规则为<key:分数,value:姓名>。然后我们的教育系统需要对所有的数据进行汇总并排序。此时我们的ConcurrentHashMap就有点束手无策了。我们的ConcurrentSkipListMap在此时也就闪亮登场了。
当然,除了我们安全有序的Map:ConcurrentSkipListSet 也还有我们安全有序的Set:ConcurrentSkipListSet。他们的底层都由SkipList(跳表)实现。
ConcurrentSkipListMap的设计思路
我们现在站在设计师的角度。如果要设计这个有序的并发集合,有哪些基础数据结构可以使用呢?
链表的思路
底层用链表实现便可以维持有序性。
但是对于单链表存在着一些弊端。例如:
- 锁粒度过大:我们要并发的存储数据,那么每次插入,删除必然要将整个链表锁住。
- 查询效率:如果我们想要查找其中某一个数据,也就只能从头到尾遍历链表。这样效率自然就会低很多。
平衡树思路
假设使用平衡树,可以实现数据的有序性,并且比起链表,查询效率也有了大幅提升(由O(n)->O(logn))。但是,平衡树依旧有两个问题:
- 锁粒度过大:我们要并发的存储数据,那么每次插入,删除必然要将整棵树锁住。
- 新增元素时,很可能会涉及多个结点的旋转、变色操作。(消耗太大)
总结老的基础数据结构实现存在的问题
我们发现,从实现的角度,其实还有许多数据结构都可以实现这个有序的Map容器,但是普遍存在两个问题:
- 多线程环境下,对锁的竞争过大;
- 为了维护有序,总会出现查询,或者增加的效率底下问题
基于这两个问题,我们的JDK开发人员研究了一种新的数据结构——跳表。
跳表skiplist的概念
首先,我先告诉你,跳表的查询效率可以达到平衡二叉树的查询效率,也就是O(logn)。

什么?这么快?我们来瞅瞅它的数据结构。
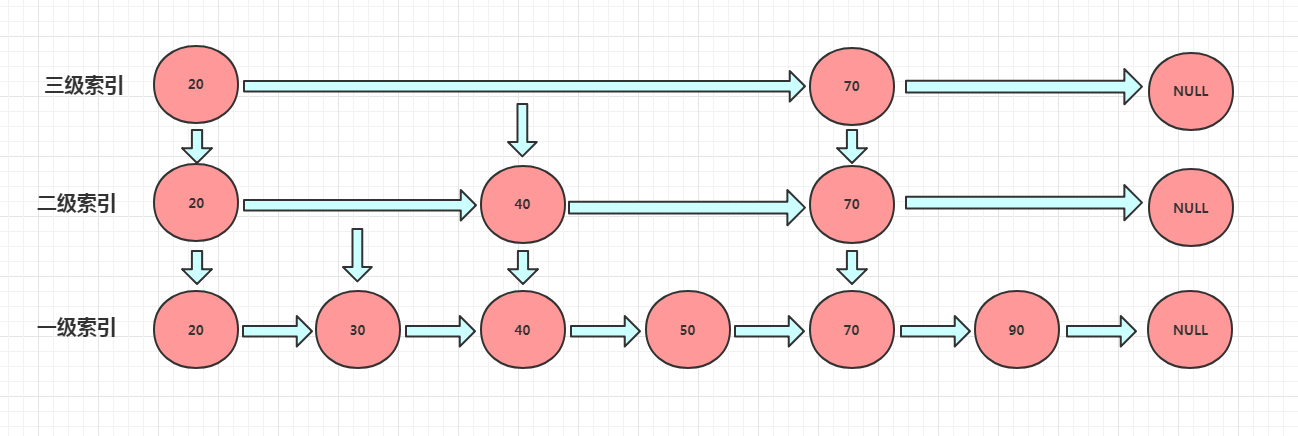
这就是跳表的本质,也就是同时维护了多个链表。并且链表是分层的。
跳表skiplist的使用
假设,我们现在要查找上图的90,那么流程是这样的:
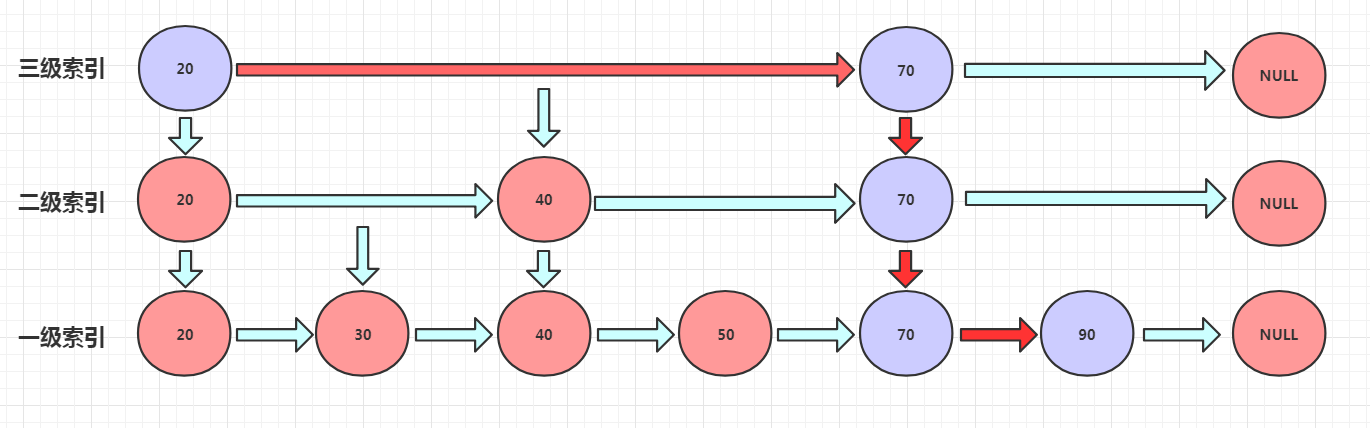
跳表内所有链表的元素都是排序的。查找时,可以从顶级链表开始找。一旦发现被查找的元素大于当前链表中的当前取值,并小于下一个值时,就会转入下一层链表继续找。这也就是说在查找过程中,搜索是跳跃式的。
原本的查询流程为直接遍历一级索引,共需要遍历6个单位查找到90。
使用我们的跳表,就仅仅需要遍历图中的5个紫色单位即可查到90.
当然,这个例子差距没有特别明显,但随着一级索引的加长,我们会出现四级索引,五级索引,六级索引...然后再走高级索引去定位我们一级索引时,效率的提升也就会愈发明显。
跳表skiplist如何解决我们的问题
再把我们之前遇到的两个问题列出来:
- 多线程环境下,对锁的竞争过大;
- 为了维护有序,总会出现查询,或者增删的效率底下问题
对平衡树的插入和删除往往很可能导致平衡树进行一次全局的调整;而对跳表的插入和删除,只需要对整个数据结构的局部进行操作即可。
这样带来的好处是:在高并发的情况下,需要一个全局锁,来保证整个平衡树的线程安全;而对于跳表,则可以实现为lock free(底层由CAS实现)。这样,在高并发环境下,就可以拥有更好的性能。就查询的性能而言,跳表的时间复杂度是 O(logn), 所以在并发数据结构中,JDK 使用跳表来实现一个 Map。
跳表skiplist的优点
- 并发环境下可以实现lock free,提高并发效率。
- 查询效率,在维护了多个链表后,可以轻松从上级索引跳跃式的定位到一级索引中元素的位置。
- 插入数据仅仅需要通过跳表特有的查询机制,定位到要插入的位置,再修改该位置元素的前后指针即可完成插入。
跳表skiplist的缺点
缺点其实我们在不停地提到,就是我们需要维护的链表,这是相当的消耗空间的。因此,跳表本身的设计理念也是用空间换时间。不得不感叹,在内存白菜价的时代,越来越多的设计思想偏向用内存去换取更高的执行效率。目前开源软件Redis和lucence都有用到它。