文章目录
- 论文地址:https://arxiv.org/pdf/2009.07111.pdf
- 来源:AAAI, 2021
- 关键词:semi-supervised learning, GCN, Contrastive Learning, GCN
1 前言
该论文主要解决的是基于图的半监督学习中的监督信息短缺的问题,该论文结合数据之间的相似性和图结构来丰富监督信息。
2 问题定义
假设共有 n = l + u n=l+u n=l+u个样本(结点), Ψ = { x 1 , ⋯ , x l , x l + 1 , ⋯ , x n } \Psi=\left\{\mathbf{x}_{1}, \cdots, \mathbf{x}_{l}, \mathbf{x}_{l+1}, \cdots, \mathbf{x}_{n}\right\} Ψ={ x1,⋯,xl,xl+1,⋯,xn},其中前 l l l个样本为带标签的样本,标签为 { y i } i = 1 l \{y_i\}_{i=1}^l { yi}i=1l,后 u u u个样本不带标签,通常在半监督学习中 l l l远小于 u u u。特征矩阵为 X ∈ R n × d \mathbf{X} \in \mathbb{R}^{n \times d} X∈Rn×d, Y ∈ R n × c \mathbf{Y} \in \mathbb{R}^{n \times c} Y∈Rn×c为标签矩阵。该论文的目标就是找到后 u u u个结点的标签。(这是一个transductive的方法)。
3 思路
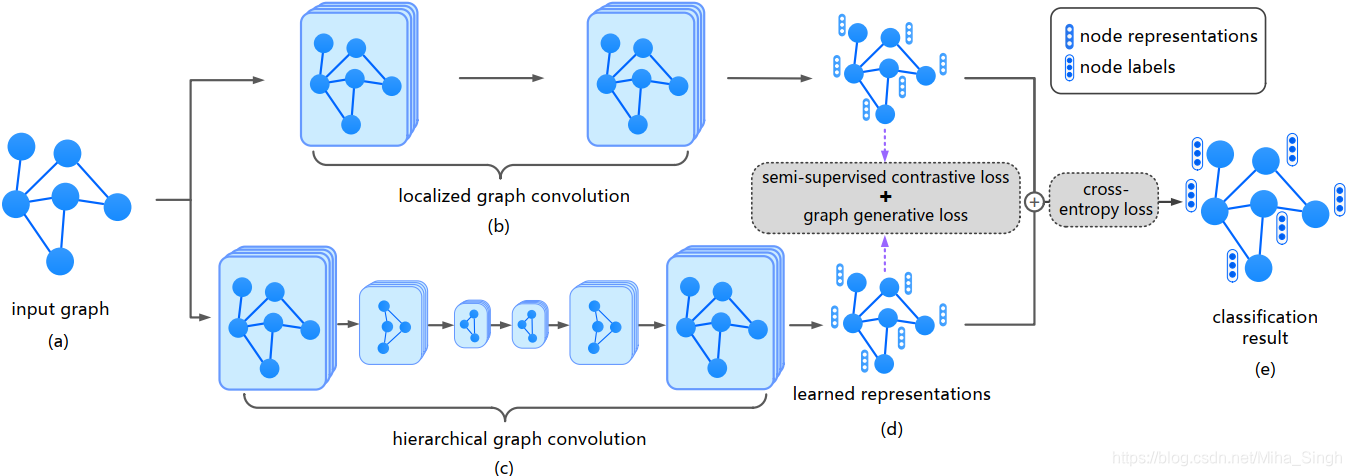
整体框架如上图所示。为了丰富监督信息,论文使用结点之间的相似性和图结构来丰富监督信息,分别使用半监督的对比学习来捕获数据之间的相似性和图生成损失来捕获图结构信息。
3.1 Semi-Supervised Contrastive Learning}
对比学习通过数据之间的相似性与相异性来学习数据的表征,但是对比学习通常用在无标签数据中,不能利用标签数据。为此,论文中提出半监督的对比学习来利用带标签的数据。半监督的对比学习损失可以分为两部分:无监督的对比损失和监督的对比损失。
论文中使用local和global两种视角的GCN来生成结点表征(目的是为了后续的对比学习),分别表示为 H ϕ 1 , H ϕ 2 \mathbf{H}^{\phi_1}, \mathbf{H}^{\phi_2} Hϕ1,Hϕ2。无监督的对比损失为:
L u c = 1 2 n ∑ i = 1 n ( L u c ϕ 1 ( x i ) + L u c ϕ 2 ( x i ) ) \mathcal{L}_{u c}=\frac{1}{2 n} \sum_{i=1}^{n}\left(\mathcal{L}_{u c}^{\phi_{1}}\left(\mathbf{x}_{i}\right)+\mathcal{L}_{u c}^{\phi_{2}}\left(\mathbf{x}_{i}\right)\right) Luc=2n1i=1∑n(Lucϕ1(xi)+Lucϕ2(xi))
其中 L u c ϕ 1 ( x i ) , L u c ϕ 2 ( x i ) \mathcal{L}_{u c}^{\phi_{1}}\left(\mathbf{x}_{i}\right), \mathcal{L}_{u c}^{\phi_{2}}\left(\mathbf{x}_{i}\right) Lucϕ1(xi),Lucϕ2(xi)分别为:
L u c ϕ 1 ( x i ) = − log exp ( ⟨ h i ϕ 1 , h i ϕ 2 ⟩ ) ∑ j = 1 n exp ( ⟨ h i ϕ 1 , h j ϕ 2 ⟩ ) L u c ϕ 2 ( x i ) = − log exp ( ⟨ h i ϕ 2 , h i ϕ 1 ⟩ ) ∑ j = 1 n exp ( ⟨ h i ϕ 2 , h j ϕ 1 ⟩ ) \begin{array}{l} \mathcal{L}_{u c}^{\phi_{1}}\left(\mathbf{x}_{i}\right)=-\log \frac{\exp \left(\left\langle\mathbf{h}_{i}^{\phi_{1}}, \mathbf{h}_{i}^{\phi_{2}}\right\rangle\right)}{\sum_{j=1}^{n} \exp \left(\left\langle\mathbf{h}_{i}^{\phi_{1}}, \mathbf{h}_{j}^{\phi_{2}}\right\rangle\right)}\\ \mathcal{L}_{u c}^{\phi_{2}}\left(\mathbf{x}_{i}\right)=-\log \frac{\exp \left(\left\langle\mathbf{h}_{i}^{\phi_{2}}, \mathbf{h}_{i}^{\phi_{1}}\right\rangle\right)}{\sum_{j=1}^{n} \exp \left(\left\langle\mathbf{h}_{i}^{\phi_{2}}, \mathbf{h}_{j}^{\phi_{1}}\right\rangle\right)} \end{array} Lucϕ1(xi)=−log∑j=1nexp(⟨hiϕ1,hjϕ2⟩)exp(⟨hiϕ1,hiϕ2⟩)Lucϕ2(xi)=−log∑j=1nexp(⟨hiϕ2,hjϕ1⟩)exp(⟨hiϕ2,hiϕ1⟩)
有监督的对比损失为:
L s c = 1 2 l ∑ i = 1 l ( L s c ϕ 1 ( x i ) + L s c ϕ 2 ( x i ) ) \mathcal{L}_{s c}=\frac{1}{2 l} \sum_{i=1}^{l}\left(\mathcal{L}_{s c}^{\phi_{1}}\left(\mathbf{x}_{i}\right)+\mathcal{L}_{s c}^{\phi_{2}}\left(\mathbf{x}_{i}\right)\right) Lsc=2l1i=1∑l(Lscϕ1(xi)+Lscϕ2(xi))
其中 L s c ϕ 1 ( x i ) , L s c ϕ 2 ( x i ) \mathcal{L}_{s c}^{\phi_{1}}\left(\mathbf{x}_{i}\right), \mathcal{L}_{s c}^{\phi_{2}}\left(\mathbf{x}_{i}\right) Lscϕ1(xi),Lscϕ2(xi)分别为:
L s c ϕ 1 ( x i ) = − log ∑ k = 1 l 1 [ y i = y k ] exp ( ⟨ h i ϕ 1 , h k ϕ 2 ⟩ ) ∑ j = 1 l exp ( ⟨ h i ϕ 1 , h j ϕ 2 ⟩ ) L s c ϕ 2 ( x i ) = − log ∑ k = 1 l 1 [ y i = y k ] exp ( ⟨ h i ϕ 2 , h k ϕ 1 ⟩ ) ∑ j = 1 l exp ( ⟨ h i ϕ 2 , h j ϕ 1 ⟩ ) , \begin{array}{l} \mathcal{L}_{s c}^{\phi_{1}}\left(\mathbf{x}_{i}\right)=-\log \frac{\sum_{k=1}^{l} \mathbb{1}_{\left[y_{i}=y_{k}\right]} \exp \left(\left\langle\mathbf{h}_{i}^{\phi_{1}}, \mathbf{h}_{k}^{\phi_{2}}\right\rangle\right)}{\sum_{j=1}^{l} \exp \left(\left\langle\mathbf{h}_{i}^{\phi_{1}}, \mathbf{h}_{j}^{\phi_{2}}\right\rangle\right)} \\ \mathcal{L}_{s c}^{\phi_{2}}\left(\mathbf{x}_{i}\right)=-\log \frac{\sum_{k=1}^{l} \mathbb{1}_{\left[y_{i}=y_{k}\right]} \exp \left(\left\langle\mathbf{h}_{i}^{\phi_{2}}, \mathbf{h}_{k}^{\phi_{1}}\right\rangle\right)}{\sum_{j=1}^{l} \exp \left(\left\langle\mathbf{h}_{i}^{\phi_{2}}, \mathbf{h}_{j}^{\phi_{1}}\right\rangle\right)}, \end{array} Lscϕ1(xi)=−log∑j=1lexp(⟨hiϕ1,hjϕ2⟩)∑k=1l1[yi=yk]exp(⟨hiϕ1,hkϕ2⟩)Lscϕ2(xi)=−log∑j=1lexp(⟨hiϕ2,hjϕ1⟩)∑k=1l1[yi=yk]exp(⟨hiϕ2,hkϕ1⟩),
半监督对比损失为: L s s c = L u c + L s c \mathcal{L}_{ssc} = \mathcal{L}_{uc} + \mathcal{L}_{sc} Lssc=Luc+Lsc。
3.2 Graph Generative Loss
为了利用图的结构作为监督信息引入了图生成损失。在现有生成模型的启示下,将图中边 e i j e_{ij} eij视为二元变量,并且该变量是条件独立的。所以在给定local和global视角的结点表征时,图的概率表示为:
p ( G ∣ H ϕ 1 , H ϕ 2 ) = ∏ i , j p ( e i j ∣ H ϕ 1 , H ϕ 2 ) = ∏ i , j p ( e i j ∣ h i ϕ 1 , h j ϕ 2 ) = ∏ i , j δ ( [ h i ϕ 1 , h j ϕ 2 ] w ) \begin{aligned} p(\mathcal{G} | \mathbf{H}^{\phi_1}, \mathbf{H}^{\phi_2}) = \prod_{i,j} p(e_{ij}| \mathbf{H}^{\phi_1}, \mathbf{H}^{\phi_2}) \\ = \prod_{i,j} p(e_{ij}| \mathbf{h}_i^{\phi_1}, \mathbf{h}_j^{\phi_2}) \\ = \prod_{i,j} \delta([\mathbf{h}_i^{\phi_1}, \mathbf{h}_j^{\phi_2}] \mathbb{w}) \end{aligned} p(G∣Hϕ1,Hϕ2)=i,j∏p(eij∣Hϕ1,Hϕ2)=i,j∏p(eij∣hiϕ1,hjϕ2)=i,j∏δ([hiϕ1,hjϕ2]w)(类似于极大似然概率),其中 δ \delta δ为逻辑回归函数。
图生成损失为: L g 2 = − p ( G ∣ H ϕ 1 , H ϕ 2 ) \mathcal{L}_{g^2} = - p(\mathcal{G} | \mathbf{H}^{\phi_1}, \mathbf{H}^{\phi_2}) Lg2=−p(G∣Hϕ1,Hϕ2)。
3.3 Model Training
因为采用了local和global的视角,结点最终的表征为: O = f λ ϕ 1 H ϕ 1 + ( 1 − λ ϕ 1 ) H ϕ 2 \mathbf{O} =f \lambda^{\phi_1}\mathbf{H}^{\phi_1} + (1-\lambda^{\phi_1})\mathbf{H}^{\phi_2} O=fλϕ1Hϕ1+(1−λϕ1)Hϕ2。
因为还存在一部分带标签的数据,因此可以借助这一部分数据产生交叉熵损失: L c e = − ∑ i = 1 l ∑ j = 1 c Y i j l n O i j \mathcal{L}_{ce} = -\sum_{i=1}^l \sum_{j=1}^c \mathbf{Y}_{ij} ln\mathbf{O}_{ij} Lce=−∑i=1l∑j=1cYijlnOij。
最终模型的损失即为:
L = L c e + λ s s c L s s c + λ g 2 L g 2 \mathcal{L} = \mathcal{L}_{ce} + \lambda_{ssc}\mathcal{L}_{ssc} + \lambda_{g^2}\mathcal{L}_{g^2} L=Lce+λsscLssc+λg2Lg2
其中 λ s s c , λ g 2 \lambda_{ssc}, \lambda_{g^2} λssc,λg2均为超参数。
4 方法的优势与局限性
4.1 优势
- 将对比学习引入到半监督学习中,结合了不带标签的数据和带标签的数据
- 利用结点相似性与图结构来丰富监督信息
4.2 局限性
- 论文中的方法为transductive,不能应用于未见过的结点
- 将论文中的方法改为inductive的
欢迎访问我的个人博客~~~