数据结构 ONE
一. 数据
1.数据项 最小数据单位
2.数据元素 数据的基本单位
3.数据对象 数据元素的集合 数据的子集
数据结构=逻辑结构+存储结构+操作实现
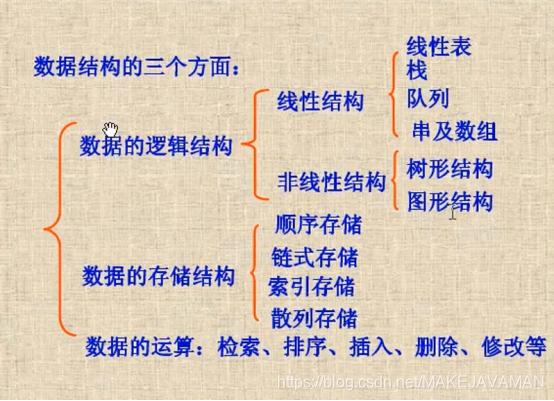
二.数据的逻辑结构
.一.线性结构 ( 一对多的关系)
1.集合中必须存在唯一的一个“第一个元素”
2.集合中必须存在唯一的一个“最后的元素”
3.除最后一个元素,其他数据元素均有唯一的“后继“
4.除第一个元素外,其他数据元素均有唯一的“前驱”
其实说白了就是一串连着的首尾呼应的糖葫芦,计科专业学过数据结构自动忽略,像和我一样电信专业就是信号与系统里流图的通路一样。
二.非线性结构 (就像族谱一样有分叉)
一个结点元素可能有多个直接的“前驱和后继”
树形结构 一对多的关系
网状结构 多对多的关系
集合结构 一个结合 直接没有关系 关系很弱 不深入研究
问:一个班的学生是什么结构?
打饭时是线性结构 (排成一列)
交作业是树形结构 (组员交给组长,组长交给课代表)
座位是网状结构 (前后左右都有相连)
三.数据的存储结构
1.顺序存储结构:把逻辑上相邻的节点存储在物理位置上相邻的存储单元中,结点之间的逻辑关系由存储单元的邻接关系来体现。由此得到的存储结构为顺序存储结构,通常顺序存储结构是借助于计算机程序设计语言( 例如C/C++ )的数组来描述的。(数据元素的存储对应于一块连续的存储空间 ,数据元素之间的前驱和后续关系通过数据元素,在存储器中的相对位置来反映)。
优点:节省存储空间,因为分配给数据的存储单元全用存放结点的数据(不考虑c/cpp语言中数组需指定大小的情况) , 结点之间的逻辑关系没有占用额外的存储空间。
采用这种方法时,可实现对结点的随机存取,即每个结点对应一个序号 ,由该序号可以直接计算出来结点的存储地址。
缺点:插入和删除操作需要移动元素,效率较低。
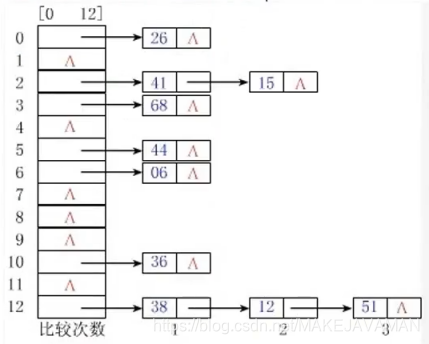
二.链式存储结构:数据元素的存储对应的是不连续的存储空间,每个存储节点对应一个需要存储的数据元素。每个结点是由数据域和指针域组成。元素之间的逻辑关系通过存储节点之间的链接关系反映出来。
特点:
1、比顺序存储结构的存储密度小(每个节点都由数据域和指针域组成,所以相同空间内假设全存满的话顺序比链式存储更多)。
2、逻辑上相邻的节点物理上不必相邻。
3、插入、删除灵活(不必移动节点,只要改变节点中的指针)。
4、查找结点时链式存储要比顺序存储慢(缺点)。
三.索引存储结构:除建立存储结点信息外,还建立附加的索引表来标识结点的地址。比如图书、字典的目录

四.散列存储结构:根据结点的关键字直接计算出该结点的存储地址,一种神奇的结构,添加、查询速度快。 Hash 数组+链式=牛逼
逻辑结构是唯一的,而存储结构不是唯一的,数据运算的实现依赖于存储结构。