siamfc-pytorch代码讲解(一):backbone&head
最近才真正开始研究目标跟踪领域(好吧,是真的慢)。就先看了一篇论文:
Fully-Convolutional Siamese Networks for Object Tracking【ECCV2016 workshop】
又因为学的是PyTorch框架,所以找了一份比较clean的代码,还是pytorch1.0的:
https://github.com/huanglianghua/siamfc-pytorch
因为这个作者也是GOT-10k toolkit的主要贡献者,所以用上这个工具箱之后显得training和test会clean一些,要能跑训练和测试代码,还得去下载GOT-10k数据集,训练数据分成了19份,如果只是为了跑一下下一份就行。
论文概述
SiamFC这篇论文算是将深度神经网络较早运用于tracking的,比它还早一点的就是SINT了,主要是运用了相似度学习的思想,采用孪生网络,把127×127的exemplar image z z z 和255×255的search image x x x 输入同一个backbone(论文中就是AlexNet)也叫Embedding Network,生成各自的Embedding,然后这两个Embedding经过互相关计算的得到score map,其上大的位置就代表对应位置上的Embedding相似度大,反之亦然。整个训练流程可以用下图表示:
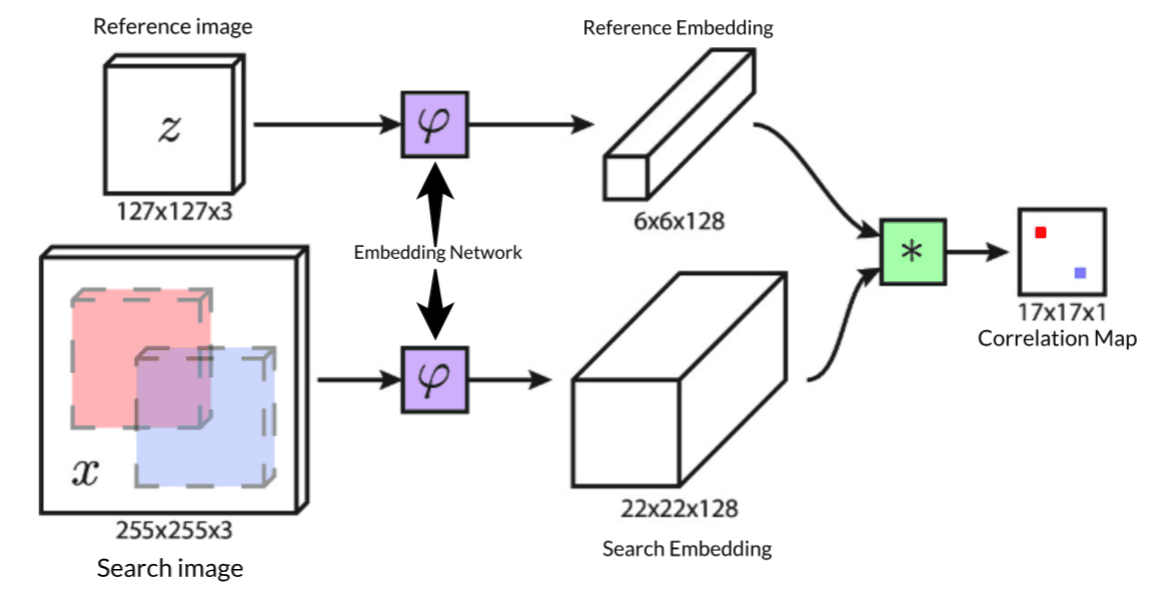
个人感觉,训练就是为了优化Embedding Network,在见到的序列中生成一个更好embedding,从而使生成的score map和生成的ground truth有更小的logistic loss。更多细节在之后的几篇会和代码一起分析。
backbones.py分析
from __future__ import absolute_import
import torch.nn as nn
__all__ = ['AlexNetV1', 'AlexNetV2', 'AlexNetV3']
class _BatchNorm2d(nn.BatchNorm2d):
def __init__(self, num_features, *args, **kwargs):
super(_BatchNorm2d, self).__init__(
num_features, *args, eps=1e-6, momentum=0.05, **kwargs)
class _AlexNet(nn.Module):
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
return x
class AlexNetV1(_AlexNet):
output_stride = 8
def __init__(self):
super(AlexNetV1, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 96, 11, 2),
_BatchNorm2d(96),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2))
self.conv2 = nn.Sequential(
nn.Conv2d(96, 256, 5, 1, groups=2),
_BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2))
self.conv3 = nn.Sequential(
nn.Conv2d(256, 384, 3, 1),
_BatchNorm2d(384),
nn.ReLU(inplace=True))
self.conv4 = nn.Sequential(
nn.Conv2d(384, 384, 3, 1, groups=2),
_BatchNorm2d(384),
nn.ReLU(inplace=True))
self.conv5 = nn.Sequential(
nn.Conv2d(384, 256, 3, 1, groups=2))
class AlexNetV2(_AlexNet):
output_stride = 4
def __init__(self):
super(AlexNetV2, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 96, 11, 2),
_BatchNorm2d(96),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2))
self.conv2 = nn.Sequential(
nn.Conv2d(96, 256, 5, 1, groups=2),
_BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 1))
self.conv3 = nn.Sequential(
nn.Conv2d(256, 384, 3, 1),
_BatchNorm2d(384),
nn.ReLU(inplace=True))
self.conv4 = nn.Sequential(
nn.Conv2d(384, 384, 3, 1, groups=2),
_BatchNorm2d(384),
nn.ReLU(inplace=True))
self.conv5 = nn.Sequential(
nn.Conv2d(384, 32, 3, 1, groups=2))
class AlexNetV3(_AlexNet):
output_stride = 8
def __init__(self):
super(AlexNetV3, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 192, 11, 2),
_BatchNorm2d(192),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2))
self.conv2 = nn.Sequential(
nn.Conv2d(192, 512, 5, 1),
_BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2))
self.conv3 = nn.Sequential(
nn.Conv2d(512, 768, 3, 1),
_BatchNorm2d(768),
nn.ReLU(inplace=True))
self.conv4 = nn.Sequential(
nn.Conv2d(768, 768, 3, 1),
_BatchNorm2d(768),
nn.ReLU(inplace=True))
self.conv5 = nn.Sequential(
nn.Conv2d(768, 512, 3, 1),
_BatchNorm2d(512))
这个module主要实现了3个AlexNet版本作为backbone,开头的__all__ = ['AlexNetV1', 'AlexNetV2', 'AlexNetV3']主要是为了让别的module导入这个backbones.py的东西时,只能导入__all__后面的部分。
后面就是三个类AlexNetV1、AlexNetV2、AlexNetV3,他们都集成了类_AlexNet,所以他们都是使用同样的forward函数,依次通过五个卷积层,每个卷积层使用nn.Sequential()堆叠,只是他们各自的total_stride和具体每层卷积层实现稍有不同(当然跟原本的AlexNet还是有些差别的,比如通道数上):
- AlexNetV1和AlexNetV2:
- 共同点:conv2、conv4、conv5这几层都用了groups=2的分组卷积,这跟原来的AlexNet会更接近一点
- 不同点:conv2中的MaxPool2d的stride不一样大,conv5层的输出通道数不一样
- AlexNetV1和AlexNetV3:前两层的MaxPool2d是一样的,但是中间层的卷积层输入输出通道都不一样,最后的输出通道也不一样,AlexNetV3最后输出经过了BN
- AlexNetV2和AlexNetV3:conv2中的MaxPool2d的stride不一样,AlexNetV2最后输出通道数小很多
其实感觉即使有这些区别,但是这并不是很重要,这一部分也是整体当中容易理解的,所以不必太去纠结为什么不一样,最后作者用的是AlexNetV1,论文中是这样的结构,其实也就是AlexNetV1:

注意:有些人会感觉这里输入输出通道对不上,这是因为像原本AlexNet分成了2个group,所以会有48->96, 192->384这样。
也可以在此py文件下面再加一段代码,测试一下打印出的tensor的shape:
if __name__ == '__main__':
alexnetv1 = AlexNetV1()
import torch
z = torch.randn(1, 3, 127, 127)
output = alexnetv1(z)
print(output.shape) # torch.Size([1, 256, 6, 6])
x = torch.randn(1, 3, 256, 256)
output = alexnetv1(x)
print(output.shape) # torch.Size([1, 256, 22, 22])
# 换成AlexNetV2依次是:
# torch.Size([1, 32, 17, 17])、torch.Size([1, 32, 49, 49])
# 换成AlexNetV3依次是:
# torch.Size([1, 512, 6, 6])、torch.Size([1, 512, 22, 22])
heads.py
先放代码为敬:
class SiamFC(nn.Module):
def __init__(self, out_scale=0.001):
super(SiamFC, self).__init__()
self.out_scale = out_scale
def forward(self, z, x):
return self._fast_xcorr(z, x) * self.out_scale
def _fast_xcorr(self, z, x):
# fast cross correlation
nz = z.size(0)
nx, c, h, w = x.size()
x = x.view(-1, nz * c, h, w)
out = F.conv2d(x, z, groups=nz) # shape:[nx/nz, nz, H, W]
out = out.view(nx, -1, out.size(-2), out.size(-1)) #[nx, 1, H, W]
return out
- 为什么这里会有个out_scale,根据作者说是因为, z z z和 x x x互相关之后的值太大,经过sigmoid函数之后会使值处于梯度饱和的那块,梯度太小,乘以out_scale就是为了避免这个。
- _fast_xcorr函数中最关键的部分就是F.conv2d函数了,可以通过官网查询到用法
torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1) → Tensor
- input – input tensor of shape ( minibatch \text{minibatch} minibatch, in_channels \text{in\_channels} in_channels , i H iH iH, i W iW iW)
- weight – filters of shape ( out_channels \text{out\_channels} out_channels, in_channels groups \frac{\text{in\_channels}}{\text{groups}} groupsin_channels, k H kH kH, k W kW kW)
所以根据上面条件,可以得到:x shape:[nx/nz, nz*c, h, w] 和 z shape:[nz, c, hz, wz],最后out shape:[nx, 1, H, W]
其实最后真实喂入此函数的z embedding shape:[8, 256, 6, 6], x embedding shape:[8, 256, 20, 20], output shape:[8, 1, 15, 15]【这个之后再回过来看也行】
同样的,也可以用下面一段代码测试一下:
if __name__ == '__main__':
import torch
z = torch.randn(8, 256, 6, 6)
x = torch.randn(8, 256, 20, 20)
siamfc = SiamFC()
output = siamfc(z, x)
print(output.shape) # torch.Size([8, 1, 15, 15])
好了,这部分先讲到这里,这一块还是算简单的,一般看一下应该就能理解,之后的代码会更具挑战性,嘻嘻,放一个辅助链接,下面这个版本中有一些动图,还是会帮助理解的:
还有下面是GOT-10k的toolkit,可以先看一下,但是训练部分代码还不是涉及很多: