摘要
focal loss是retinanet网络提出的新型损失函数,重点就是对正负样本差距过大,导致训练效果低下,那么该如何减少负样本的loss,增加正样本占全部loss的比重,就能有效的控制样本差距带来的好的模型学习能力。在下文中a是alpha,y是gamma
FL损失函数
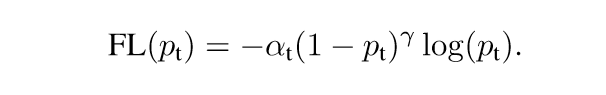
a 是用来调解正负样本,根据不同的比例来减少正负样本loss的比例,从而提高模型学习能力,一般情况下正样本远远小于负样本,所以设置a=0.25,负样本为0.75就能缩小loss的比例。
γ 负责降低简单样本的损失值, 以解决加总后负样本loss值很大,这样可以让模型学习的时候多学习到困难样本的特征来达到更好的识别效果。
(1-pt)这里可以代表预测的分值越高则值越小,pt越小值越大,这种的好处是一旦分很低,造成的loss更大,让模型学习效果更好。
focal loss整体就可以处理正负样本不平衡的情况,效果比CE好上很多,现在对比看一下
CE损失函数
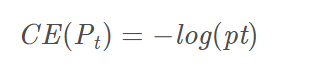
CE没有FL的a和y值得调解,就是简单的通过log来对应loss值
效果对比
用相同的数据来看下loss,测试代码
t.manual_seed(50) #随机种子确保每次input tensor值是一样的
input = torch.randn(5, 5, dtype=torch.float32, requires_grad=True)
print('input值为\n', input)
targets = t.randint(5, (5, ))
print('targets值为\n', targets)
criterion = FocalLoss(5, alpha=0.25, gamma=2, size_average=True)
loss = criterion(input, targets)
loss.backward()
print('FL loss',loss)
a=F.cross_entropy(input, targets)
print('CE loss',a)

同样的数据,不一样的loss值,可以很明显的看出FL的效果,
具体的数来对比
现在只考虑y=2的时候,pt=0.95来进行运算,
FL=(1-0.95)**2*log(0.95)=0.00005569
CE=−log(0.95)=0.02227639
这样就将分值高的loss尽可能的低,这样在模型学习的时候注意力集中在分值很低的预测来降低loss。在进行梯度下降的时候,模型通过训练只是为了loss的降低,这样就专门针对导致loss大的值进行修改来降低loss,就能获得好的模型。

这里是作者的实验图,通过设置y来看对整体loss的影响效果,y=2时是效果最好的时候,
a的效果
假设我们模型
负样本10000笔资料probability(pt) = 0.95(简单样本), 这边可以理解为easy-example
正样本10笔资料, probability(pt) = 0.05(困难样本),
CE的值
- 负样本 : log(p_t) * 样本数(100000) = 0.02227 * 100000 = 2227
- 正样本 : log(p_t) * 样本数(10) = 1.30102 * 10 = 13.0102
total loss = 2227+13.0102 = 2240
正样本占比:13.0102 / 2240 = 0.0058
FL的值 a=0.25 y=2
- 负样本 : 0.75*(1-0.95)^2 * 0.02227 *样本数(100000) = 0.00004176 * 100000 = 4.1756
- 正样本 : 0.25* (1-0.05)^2 * 1.30102 *样本数(10)= 0.29354264 * 10 = 2.935
total loss = 4.175 + 2.935 = 7.110
正样本占比:2.935/7.110 = 0.4127(与0.0058差距甚大)
代码实现
from torch import nn
import torch
from torch.nn import functional as F
class focal_loss(nn.Module):
def __init__(self, alpha=0.25, gamma=2, num_classes=5, size_average=True):
super(focal_loss, self).__init__()
self.size_average = size_average
if isinstance(alpha, (float, int)): #仅仅设置第一类别的权重
self.alpha = torch.zeros(num_classes)
self.alpha[0] += alpha
self.alpha[1:] += (1 - alpha)
if isinstance(alpha, list): #全部权重自己设置
self.alpha = torch.Tensor(alpha)
self.gamma = gamma
def forward(self, inputs, targets):
alpha = self.alpha
print('aaaaaaa',alpha)
N = inputs.size(0)
C = inputs.size(1)
P = F.softmax(inputs,dim=1)
print('ppppppppppppppppppppp', P)
# ---------one hot start--------------#
class_mask = inputs.data.new(N, C).fill_(0) # 生成和input一样shape的tensor
print('依照input shape制作:class_mask\n', class_mask)
class_mask = class_mask.requires_grad_() # 需要更新, 所以加入梯度计算
ids = targets.view(-1, 1) # 取得目标的索引
print('取得targets的索引\n', ids)
class_mask.data.scatter_(1, ids.data, 1.) # 利用scatter将索引丢给mask
print('targets的one_hot形式\n', class_mask) # one-hot target生成
# ---------one hot end-------------------#
probs = (P * class_mask).sum(1).view(-1, 1)
print('留下targets的概率(1的部分),0的部分消除\n', probs)
# 将softmax * one_hot 格式,0的部分被消除 留下1的概率, shape = (5, 1), 5就是每个target的概率
log_p = probs.log()
print('取得对数\n', log_p)
# 取得对数
loss = torch.pow((1 - probs), self.gamma) * log_p
batch_loss = -alpha *loss.t() # 對應下面公式
print('每一个batch的loss\n', batch_loss)
# batch_loss就是取每一个batch的loss值
# 最终将每一个batch的loss加总后平均
if self.size_average:
loss = batch_loss.mean()
else:
loss = batch_loss.sum()
print('loss值为\n', loss)
return loss
torch.manual_seed(50) #随机种子确保每次input tensor值是一样的
input = torch.randn(5, 5, dtype=torch.float32, requires_grad=True)
print('input值为\n', input)
targets = torch.randint(5, (5, ))
print('targets值为\n', targets)
criterion = focal_loss()
loss = criterion(input, targets)
loss.backward()
