1.前期工作
hadoop环境搭建成功。
详细如何搭建hadoop环境可以点击这里
2.在server最小化系统进行单词计数
2.1切换用户,查看进程
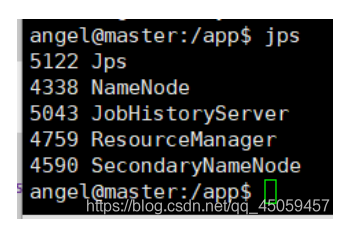
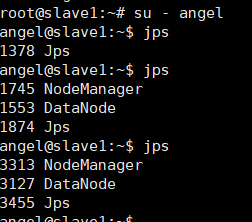
目的:保证hadoop集群开启
su - angel
主节点进程
从节点进程
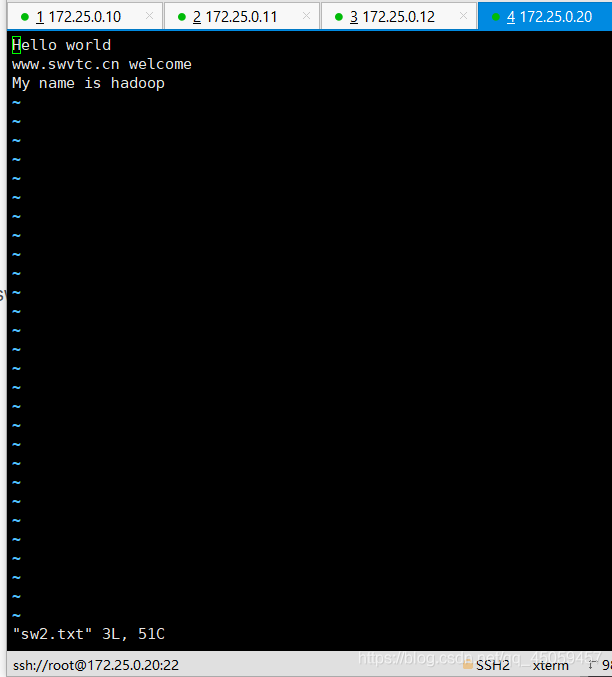
2.3 建立测试文档
测试文档的路径是/home/angel
vim.tiny sw1.txt

vim.tiny sw2.txt
2.4 建立测试文件夹并上传到集群
在集群中查看文件
hdfs dfs -ls /

在集群中建立test文件夹,作为测试文件夹
hdfs dfs -mkdir /test

将test文件夹上传到集群
hdfs dfs -put sw*.txt /test
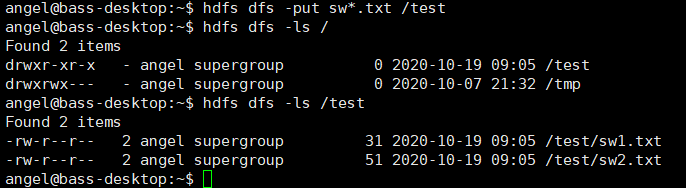
查看test文件夹有没有上传成功
hdfs dfs -ls /test

查看sw1.txt的内容
hdfs dfs -cat /test/sw1.txt

2.5 运行hadoop包里面的单词计数的程序对测试文件进行单词计数
2.5.1 找到相关的包
cd /app/hadoop-2.8.5/
2.5.2 运行hadoop包里面的类,进行单词计数
用hadoop命令运行hadoop-mapreduce-examples-2.8.5包里面的wordcount类,输入/test,输出out1。
hadoop jar hadoop-mapreduce-examples-2.8.5 jar wordcount /test /out1

2.5.3 在集群中查看输出文件


到此,完成在server最小化系统上建立haddop集群,运行MapReduce进行单词计数成功。
3.运行eclipse,编写单词计数程序
3.1 前期工作
本文主要讲解在MapReduce平台的应用
详细点击这里查看前期工作
注:
eclipse只能在desktop版本系统上运行,不能再提示符窗口运行。
3.2 开启eclipse


3.3建立项目和配置Hadoop安装目录
3.3.1 建立项目
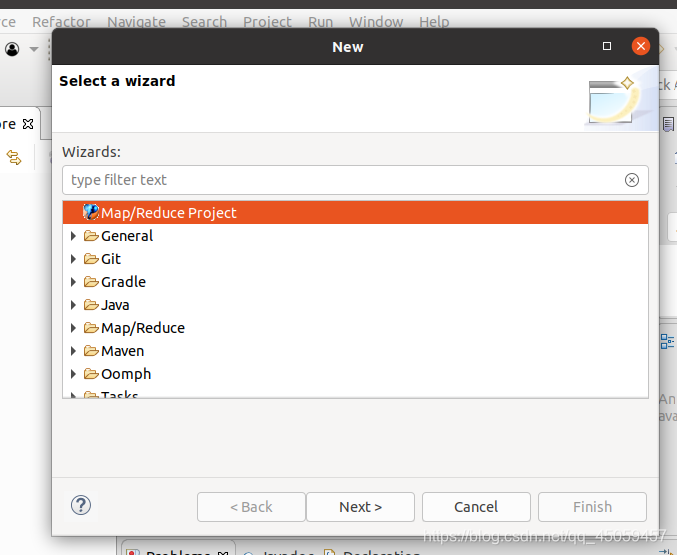
执行菜单栏中的“File”-“New”-“Other…”,选择“Map/Reduce Project”,如下图。
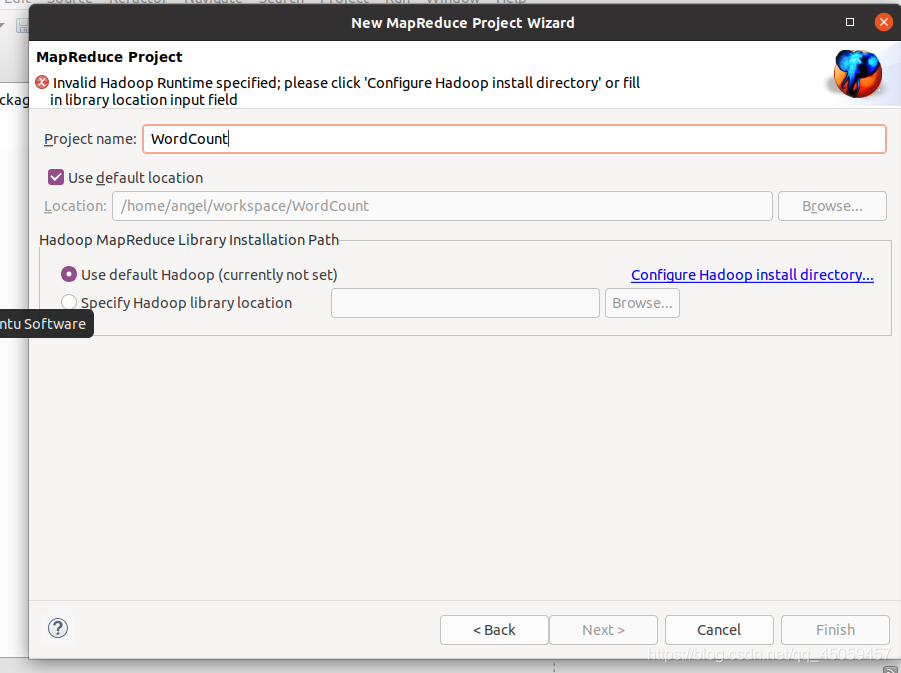
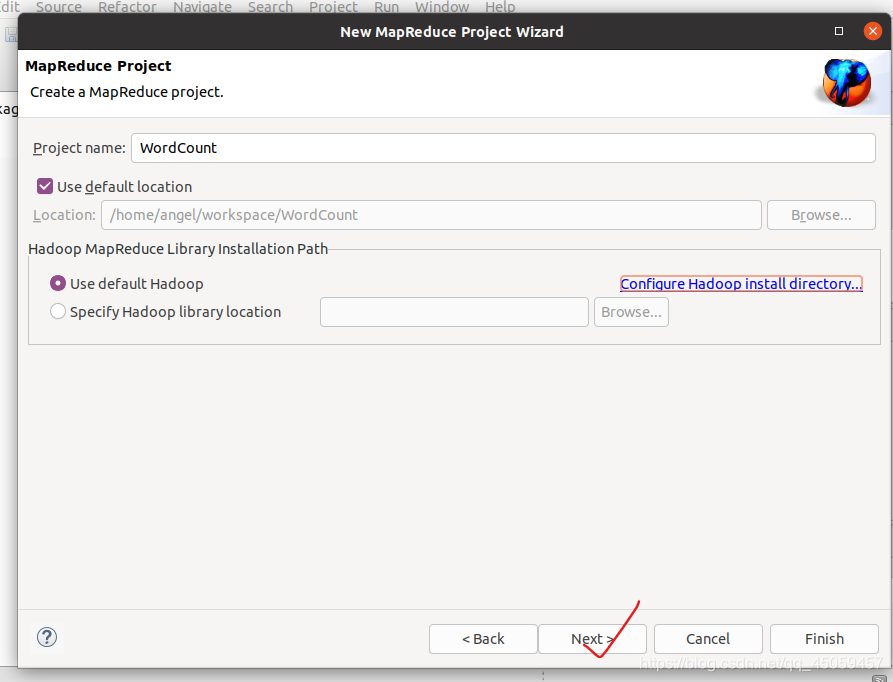
输入项目名称“WordCount”,选择"Configure Hadoop install directory…"
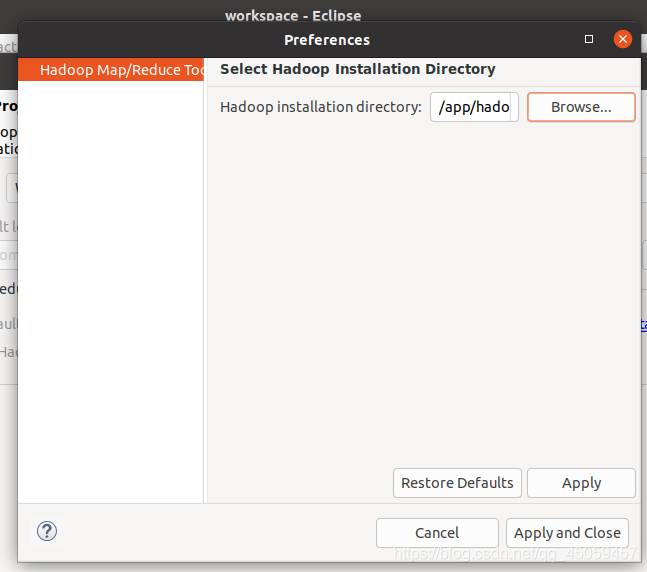
3.3.2 配置Hadoop安装目录
点击next。
选择项目。

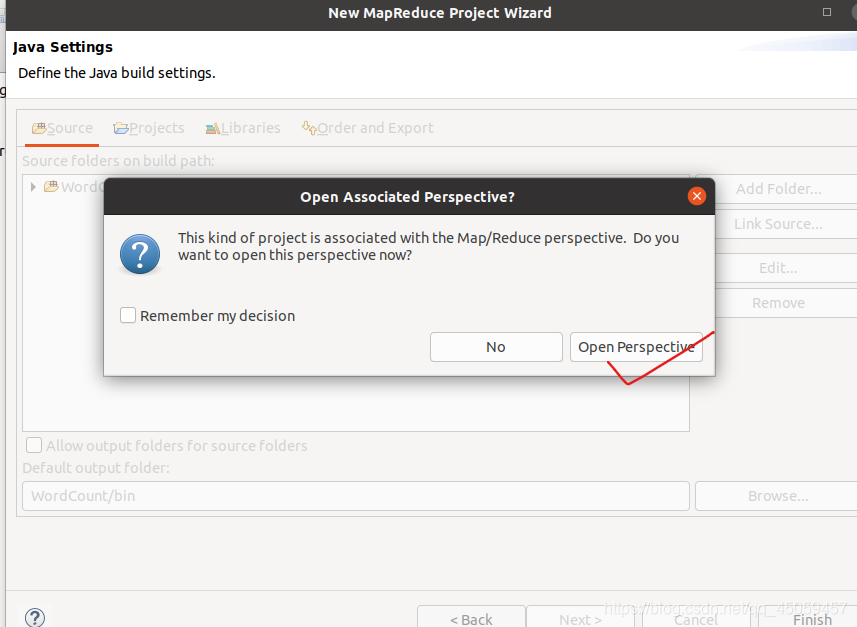
到此项目名创建和配置Hadoop安装目录完成。点击next。
3.4 新建 Hadoop地址
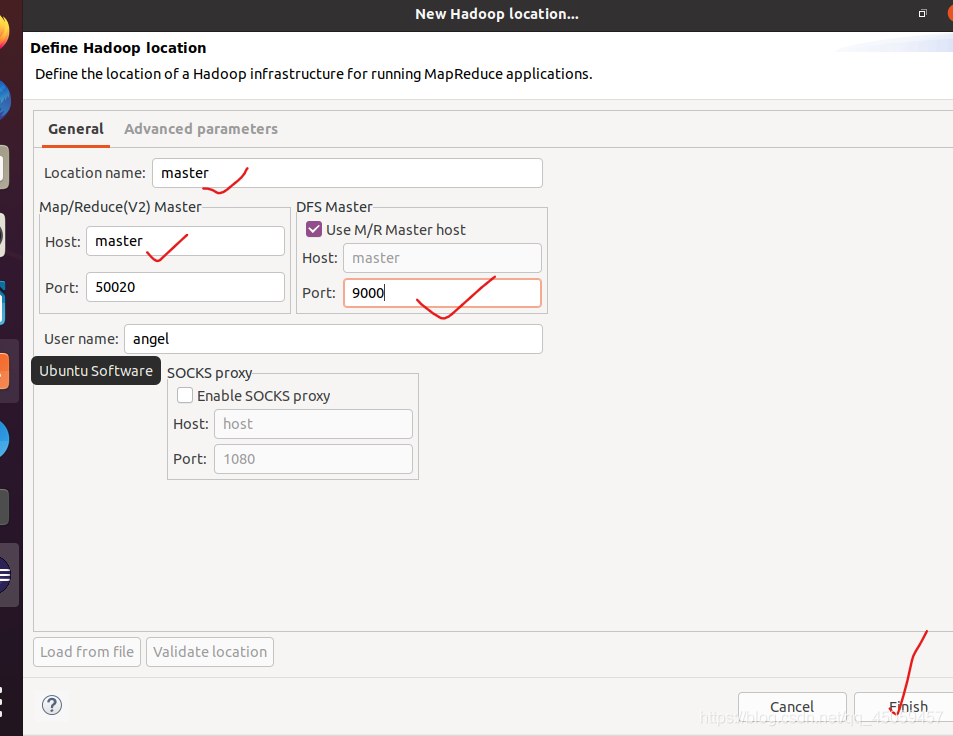
在“Location name”文本框输入“master”,“Map/Reduce(V2) Mater”的“Host”原来的“localhost”改为“master”,“DFS Master”的“Port”原来的“50040”改为“9000”,其他不变。
插入:
为什么是9000呢?
可以去配置文件看看。
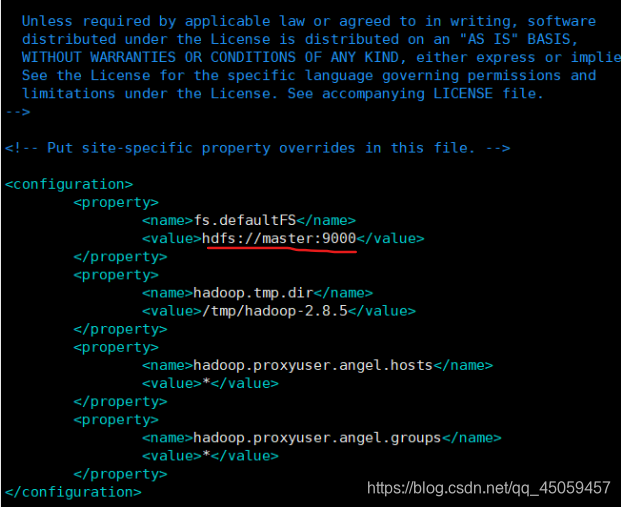
cat /app/hadoop-2.8.5/etc/hadoop/core-site.xml
查看右边蓝有没有出现master,有出现master,就证明新建 Hadoop地址成功。
3.5 建立编写单词计数的类
在“WordCount”-“src”,新建“WordCount”类。
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
3.6 运行类,之前需要添加程序参数和设置主类
“Run As”-“Run_Confilgurations”,双击“Java Application”

3.6.1 添加程序参数
双击“Java Application”,在Name文本框输入“WordCount”,
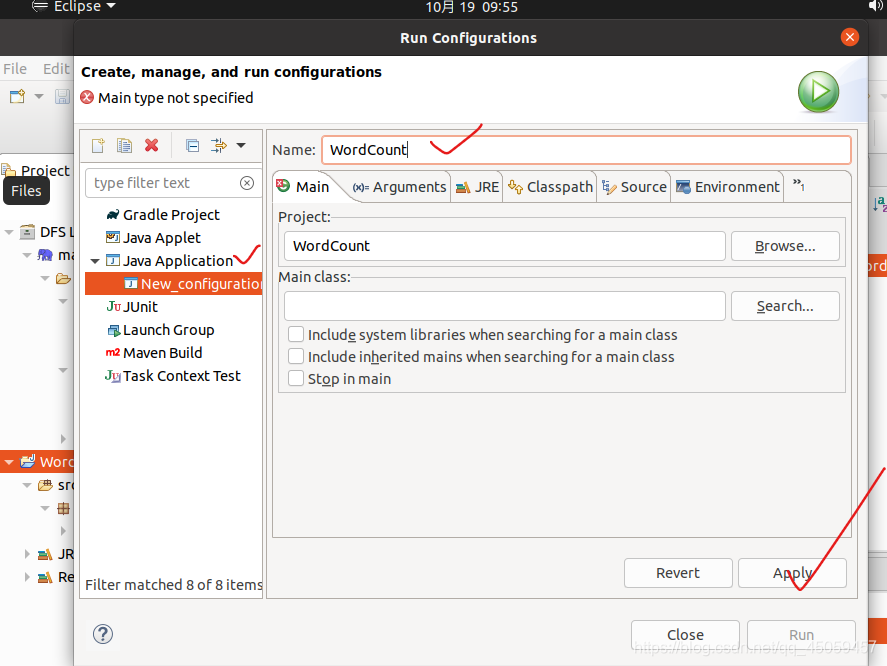
选择“Arguments”选项卡,在“Program arguments”文本框输入两行参数:“hdfs://master:9000/input”,“hdfs://master:9000/output”
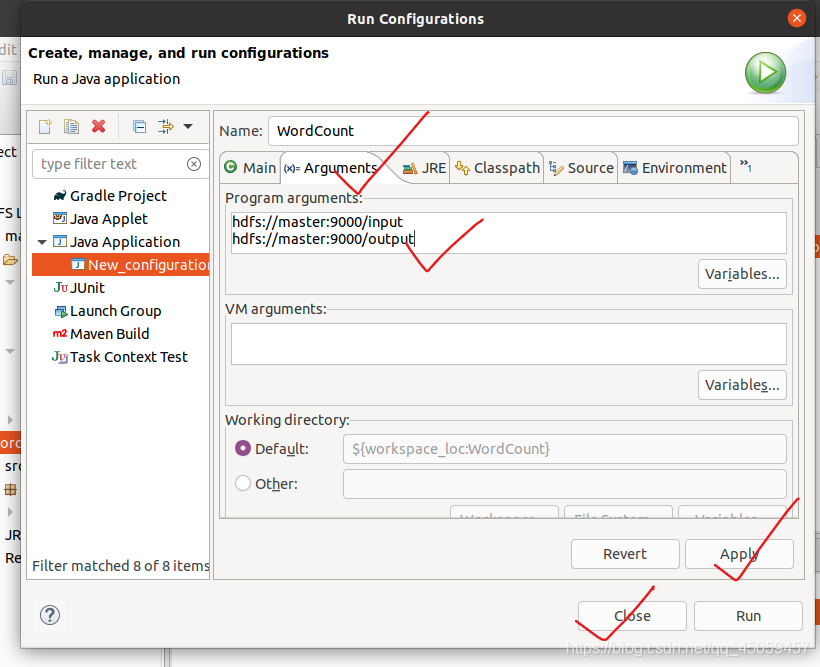
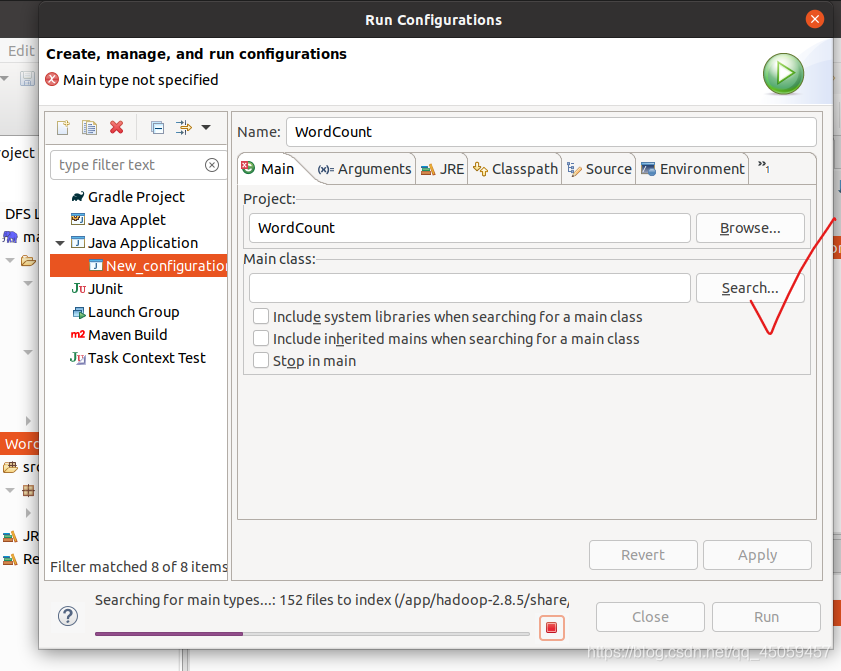
3.6.2 设置主类
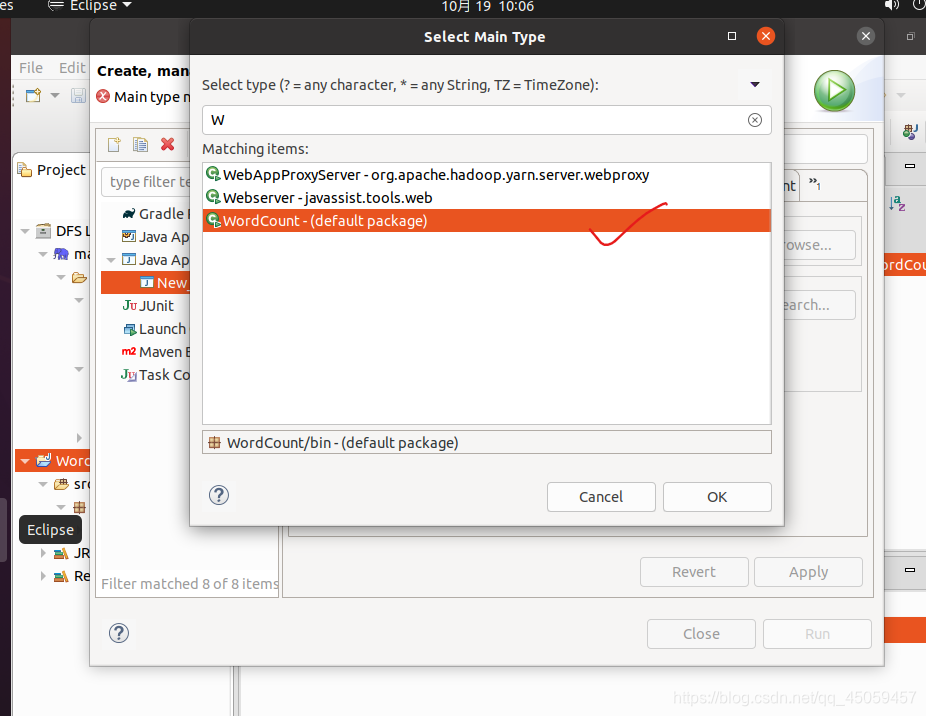
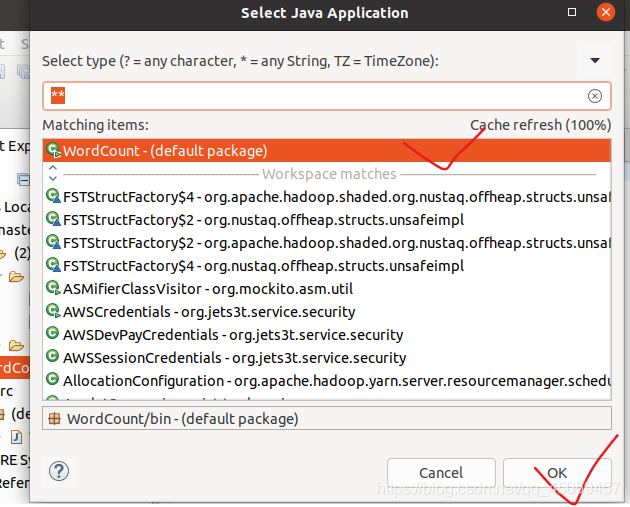
选择项目的主类,点击“Search”,
将“WordCount-(default package)”设置成主类。
3.7 清空之前的实验文件,防止干扰

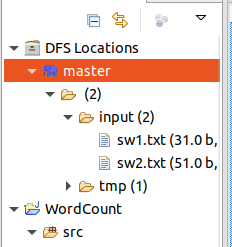
在集群建立测试文件/input

上传测试文件

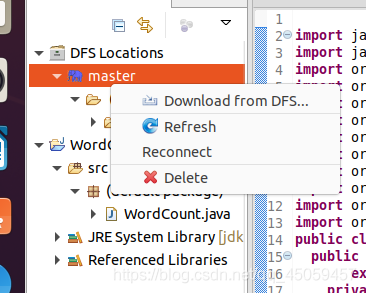
3.8 重新连接集群
3.9 运行Hadoop
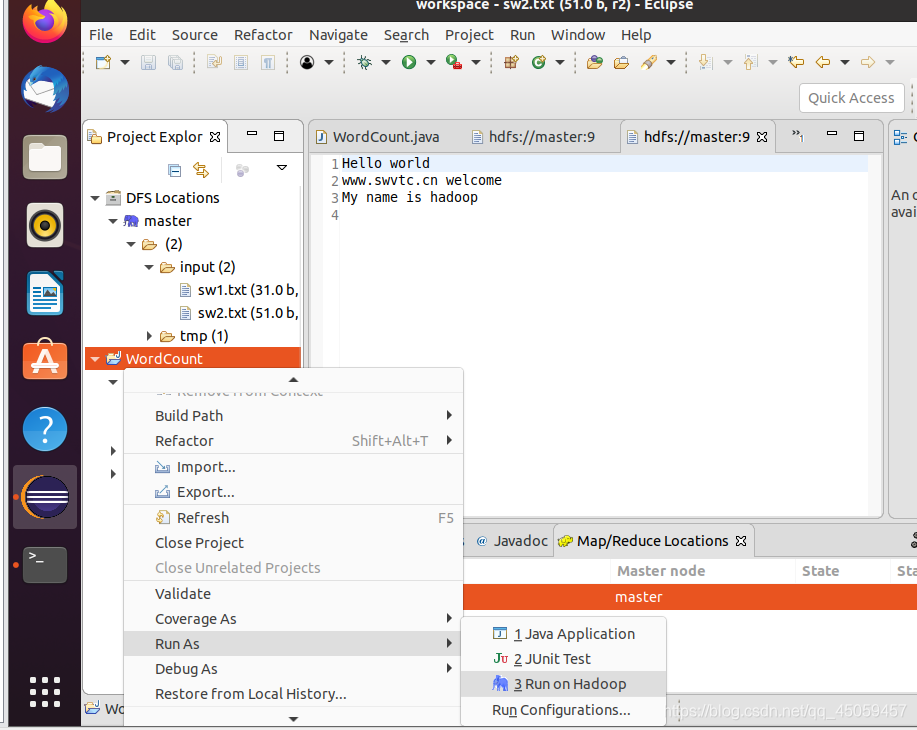
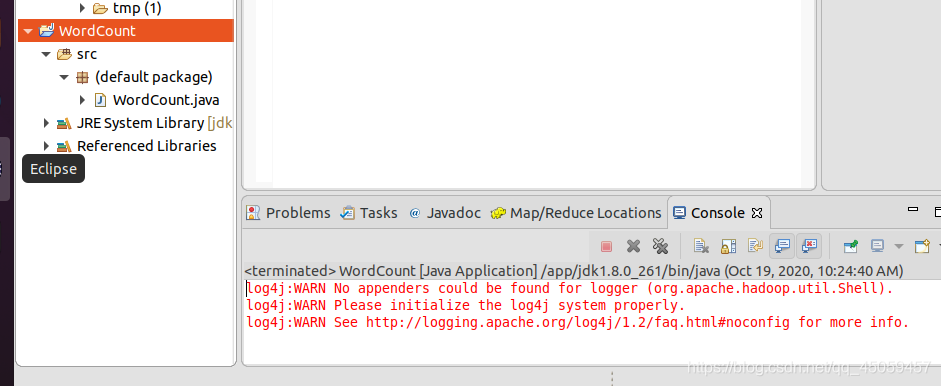
选择项目,
控制台没有报错,只有警告。
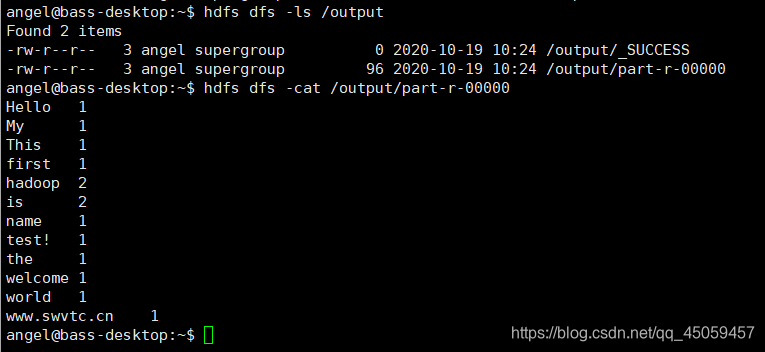
3.10 查看结果

在字符界面查看结果,与桌面端的窗口一致。
到此,在MapReduce平台 编写单词计数程序成功!!