cpu异常往往还是比较好定位的。原因包括业务逻辑问题(死循环)、频繁gc以及上下文切换过多。而最常见的往往是业务逻辑(或者框架逻辑)导致的
查看机器cpu核数
CPU总核数 = 物理CPU个数 * 每颗物理CPU的核数
总逻辑CPU数 = 物理CPU个数 * 每颗物理CPU的核数 * 超线程数
查看CPU信息(型号)
[1014154@cc69dd4c5-4tdb5 ~]$ cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
32 Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz
查看物理CPU个数
[1014154@cc69dd4c5-4tdb5 ~]$ cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
16
查看每个物理CPU中core的个数(即核数)
[1014154@cc69dd4c5-4tdb5 ~]$ cat /proc/cpuinfo| grep "cpu cores"| uniq
cpu cores : 2
查看逻辑CPU的个数
[1014154@cc69dd4c5-4tdb5 ~]$ cat /proc/cpuinfo| grep "processor"| wc -l
32- 使用jstack分析cpu问题
top
在Linux内核的操作系统中,进程是根据虚拟运行时间(由进程优先级、nice值加上实际占用的CPU时间进行动态计算得出)进行动态调度的。在执行进程时,需要从用户态转换到内核态,用户空间不能直接操作内核空间的函数。通常要利用系统调用来完成进程调度,而用户空间到内核空间的转换通常是通过软中断来完成的。例如要进行磁盘操作,用户态需要通过系统调用内核的磁盘操作指令,所以CPU消耗的时间被切分成用户态CPU消耗、系统(内核) CPU 消耗,以及磁盘操作 CPU 消耗。执行进程时,需要经过一系列的操作,进程首先在用户态执行,在执行过程中会进行进程优先级的调整(nice),通过系统调用到内核,再通过内核调用,硬中断、软中断,让硬件执行任务。执行完成之后,再从内核态返回给系统调用,最后系统调用将结果返回给用户态的进程。
top可以查看CPU总体消耗,包括分项消耗,如User,System,Idle,nice等。Shift + H显示java线程;Shift + M按照内存使用排序;Shift + P按照CPU使用时间(使用率)排序;Shift + T按照CPU累积使用时间排序;多核CPU,进入top视图1,可以看到各各CPU的负载情况。
top - 15:24:11 up 8 days, 7:52, 1 user, load average: 5.73, 6.85, 7.33
Tasks: 17 total, 1 running, 16 sleeping, 0 stopped, 0 zombie
%Cpu(s): 13.9 us, 9.2 sy, 0.0 ni, 76.1 id, 0.1 wa, 0.0 hi, 0.1 si, 0.7 st
KiB Mem : 11962365+total, 50086832 free, 38312808 used, 31224016 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 75402760 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
300 ymmapp 20 0 17.242g 1.234g 14732 S 2.3 1.1 9:40.38 java
1 root 20 0 15376 1988 1392 S 0.0 0.0 0:00.06 sh
11 root 20 0 120660 11416 1132 S 0.0 0.0 0:04.94 python
54 root 20 0 85328 2240 1652 S 0.0 0.0 0:00.00 su
55 ymmapp 20 0 17432 1808 1232 S 0.0 0.0 0:00.00 bash
56 ymmapp 20 0 17556 2156 1460 S 0.0 0.0 0:00.03 control.sh
57 ymmapp 20 0 11880 740 576 S 0.0 0.0 0:00.00 tee
115 ymmapp 20 0 17556 2112 1464 S 0.0 0.0 0:00.02 control_new_war
133 root 20 0 106032 4240 3160 S 0.0 0.0 0:00.03 sshd
134 ymmapp 20 0 17080 6872 3180 S 0.0 0.0 0:01.82 ops-updater
147 ymmapp 20 0 17956 2636 1544 S 0.0 0.0 0:00.07 control.sh
6538 ymmapp 20 0 115656 10532 3408 S 0.0 0.0 0:00.46 beidou-agent
6785 ymmapp 20 0 2572996 22512 2788 S 0.0 0.0 0:03.44 gatherinfo4dock
29241 root 20 0 142148 5712 4340 S 0.0 0.0 0:00.04 sshd
29243 1014154 20 0 142148 2296 924 S 0.0 0.0 0:00.00 sshd
29244 1014154 20 0 15208 2020 1640 S 0.0 0.0 0:00.00 bash
32641 1014154 20 0 57364 2020 1480 R 0.0 0.0 0:00.00 top
第一行:15:24:11 up 8 days, 7:52, 1 user, load average: 5.73, 6.85, 7.33:15:24:11 系统时间,up 8 days 运行时间,1 user 当前登录用户数,load average 负载均衡情况,分别表示1分钟,5分钟,15分钟负载情况。
第二行:Tasks: 17 total, 1 running, 16 sleeping, 0 stopped, 0 zombie:总进程数17,运行数1,休眠 16,停止0,僵尸进程0。
第三行:%Cpu(s): 13.9 us, 9.2 sy, 0.0 ni, 76.1 id, 0.1 wa, 0.0 hi, 0.1 si, 0.7 st:用户空间CPU占比13.9% ,内核空间CPU占比9.2%,改变过优先级的进程CPU占比0%,空闲CPU占比76.1 ,IO等待占用CPU占比0.1% ,硬中断占用CPU占比0%,软中断占用CPU占比0.1%,当前VM中的cpu 时钟被虚拟化偷走的比例0.7%。
第四和第五行表示内存和swap区域的使用情况。
第七行表示:
-
PID: 进程id -
USER:进程所有者 -
PR:进程优先级 -
NI:nice值。负值表示高优先级,正值表示低优先级 -
VIRT:虚拟内存,进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES -
RES:常驻内存,进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA -
SHR:共享内存,共享内存大小,单位kb -
S:进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程 -
%CPU:上次更新到现在的CPU时间占用百分比 -
%MEM:进程使用的物理内存百分比 -
TIME+:进程使用的CPU时间总计,单位1/100秒 -
COMMAND:进程名称(命令名/命令行)
计算在cpu load里面的uninterruptedsleep的任务数量
top -b -n 1 | awk '{if (NR<=7)print;else if($8=="D")
{print;count++}}END{print "Total status D:"count}'
[root@localhost ~]# top -b -n 1 | awk '{if (NR<=7)print;else if($8=="D"){print;count++}}END{print "Total status D:"count}'
top - 15:35:05 up 1 day, 26 min, 3 users, load average: 0.00, 0.01, 0.05
Tasks: 225 total, 1 running, 224 sleeping, 0 stopped, 0 zombie
%Cpu(s): 2.5 us, 10.0 sy, 0.0 ni, 87.5 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 1421760 total, 104516 free, 777344 used, 539900 buff/cache
KiB Swap: 2097148 total, 2071152 free, 25996 used. 456028 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
Total status D:
sar
通过sar -u 3可以查看CUP总体消耗占比:
[root@localhost ~]# sar -u 3
Linux 3.10.0-1062.el7.x86_64 (localhost.localdomain) 2020年05月01日 _x86_64_ (2 CPU)
15时18分03秒 CPU %user %nice %system %iowait %steal %idle
15时18分06秒 all 0.00 0.00 0.17 0.00 0.00 99.83
15时18分09秒 all 0.00 0.00 0.17 0.00 0.00 99.83
15时18分12秒 all 0.17 0.00 0.17 0.00 0.00 99.66
15时18分15秒 all 0.00 0.00 0.00 0.00 0.00 100.00
15时18分18秒 all 0.00 0.00 0.00 0.00 0.00 100.00
-
%user:用户空间的CPU使用。 -
%nice:改变过优先级的进程的CPU使用率。 -
%system:内核空间的CPU使用率。 -
%iowait:CPU等待IO的百分比 。 -
%steal:虚拟机的虚拟机CPU使用的CPU。 -
%idle:空闲的CPU。
在以上的显示当中,主要看%iowait和%idle:
-
若
%iowait的值过高,表示硬盘存在I/O瓶颈; -
若
%idle的值高但系统响应慢时,有可能是 CPU 等待分配内存,此时应加大内存容量; -
若
%idle的值持续低于 10,则系统的 CPU 处理能力相对较低,表明系统中最需要解决的资源是 CPU;
定位线上最耗CPU的线程
准备工作
启动一个程序。arthas-demo是一个简单的程序,每隔一秒生成一个随机数,再执行质因数分解,并打印出分解结果。
curl -O https://alibaba.github.io/arthas/arthas-demo.jar
java -jar arthas-demo.jar
[root@localhost ~]# curl -O https://alibaba.github.io/arthas/arthas-demo.jar
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 3743 100 3743 0 0 3022 0 0:00:01 0:00:01 --:--:-- 3023
[root@localhost ~]# java -jar arthas-demo.jar
1813=7*7*37
illegalArgumentCount: 1, number is: -180005, need >= 2
illegalArgumentCount: 2, number is: -111175, need >= 2
18505=5*3701
166691=7*23813
105787=11*59*163
60148=2*2*11*1367
196983=3*3*43*509
illegalArgumentCount: 3, number is: -173479, need >= 2
illegalArgumentCount: 4, number is: -112840, need >= 2
39502=2*19751
....
通过top命令找到最耗时的进程
[root@localhost ~]# top
top - 11:11:05 up 20:02, 3 users, load average: 0.09, 0.07, 0.05
Tasks: 225 total, 1 running, 224 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.7 sy, 0.0 ni, 99.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 1421760 total, 135868 free, 758508 used, 527384 buff/cache
KiB Swap: 2097148 total, 2070640 free, 26508 used. 475852 avail Mem
Change delay from 3.0 to
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
98344 root 20 0 2422552 23508 12108 S 0.7 1.7 0:00.32 java
1 root 20 0 194100 6244 3184 S 0.0 0.4 0:20.41 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.12 kthreadd
4 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
6 root 20 0 0 0 0 S 0.0 0.0 0:20.25 ksoftirqd/0
找到进程号是98344。
找到进程中最耗CUP的线程
可以使用ps -Lfp pid cu或者ps -mp pid -o THREAD, tid, time或者top -Hp pid,我这里用第一个,查看某个进程中的线程CPU消耗排序:
[root@localhost ~]# ps -Lp 98344 cu
USER PID LWP %CPU NLWP %MEM VSZ RSS TTY STAT START TIME COMMAND
root 98344 98344 0.0 10 4.1 2422552 59060 pts/0 Sl+ 11:09 0:00 java
root 98344 98345 0.0 10 4.1 2422552 59060 pts/0 Sl+ 11:09 0:04 java
root 98344 98346 0.0 10 4.1 2422552 59060 pts/0 Sl+ 11:09 0:01 VM Thread
root 98344 98347 0.0 10 4.1 2422552 59060 pts/0 Sl+ 11:09 0:00 Reference Handl
root 98344 98348 0.0 10 4.1 2422552 59060 pts/0 Sl+ 11:09 0:00 Finalizer
root 98344 98349 0.0 10 4.1 2422552 59060 pts/0 Sl+ 11:09 0:00 Signal Dispatch
root 98344 98350 0.0 10 4.1 2422552 59060 pts/0 Sl+ 11:09 0:05 C2 CompilerThre
root 98344 98351 0.0 10 4.1 2422552 59060 pts/0 Sl+ 11:09 0:00 C1 CompilerThre
root 98344 98352 0.0 10 4.1 2422552 59060 pts/0 Sl+ 11:09 0:00 Service Thread
root 98344 98353 0.1 10 4.1 2422552 59060 pts/0 Sl+ 11:09 0:19 VM Periodic Tas
看TIME列可以看出那个线程耗费CUP多,根据LWP列可以看到线程的ID号,但是需要转换成16进制才可以查询线程堆栈信息。
获取线程id的十六进制码
使用printf '%x\n' 98345命令做进制转换:
[root@localhost ~]# printf '%x\n' 98345
18029
查看线程堆栈信息
使用jstack获取堆栈信息jstack 98344 | grep -A 10 18029:
[root@localhost ~]# jstack 98344 | grep -A 10 18029
"main" #1 prio=5 os_prio=0 tid=0x00007fb88404b800 nid=0x18029 waiting on condition [0x00007fb88caab000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at java.lang.Thread.sleep(Thread.java:340)
at java.util.concurrent.TimeUnit.sleep(TimeUnit.java:386)
at demo.MathGame.main(MathGame.java:17)
"VM Thread" os_prio=0 tid=0x00007fb8840f2800 nid=0x1802a runnable
"VM Periodic Task Thread" os_prio=0 tid=0x00007fb884154000 nid=0x18031 waiting on condition
通过命令我们可以看到这个线程的对应的耗时代码是在
demo.MathGame.main(MathGame.java:17)
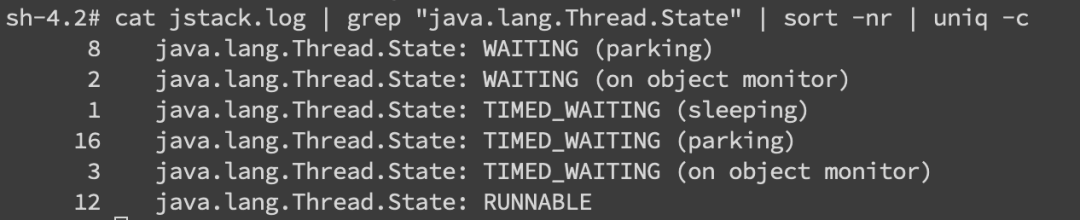
当然更常见的是我们对整个jstack文件进行分析,通常我们会比较关注WAITING和TIMED_WAITING的部分,BLOCKED就不用说了。我们可以使用命令cat jstack.log | grep "java.lang.Thread.State" | sort -nr | uniq -c来对jstack的状态有一个整体的把握,如果WAITING之类的特别多,那么多半是有问题啦。
- 频繁gc
当然我们还是会使用jstack来分析问题,但有时候我们可以先确定下gc是不是太频繁,使用jstat -gc pid 1000命令来对gc分代变化情况进行观察,1000表示采样间隔(ms),S0C/S1C、S0U/S1U、EC/EU、OC/OU、MC/MU分别代表两个Survivor区、Eden区、老年代、元数据区的容量和使用量。YGC/YGT、FGC/FGCT、GCT则代表YoungGc、FullGc的耗时和次数以及总耗时。如果看到gc比较频繁,再针对gc方面做进一步分析,具体可以参考一下gc章节的描述。

- 上下文切换
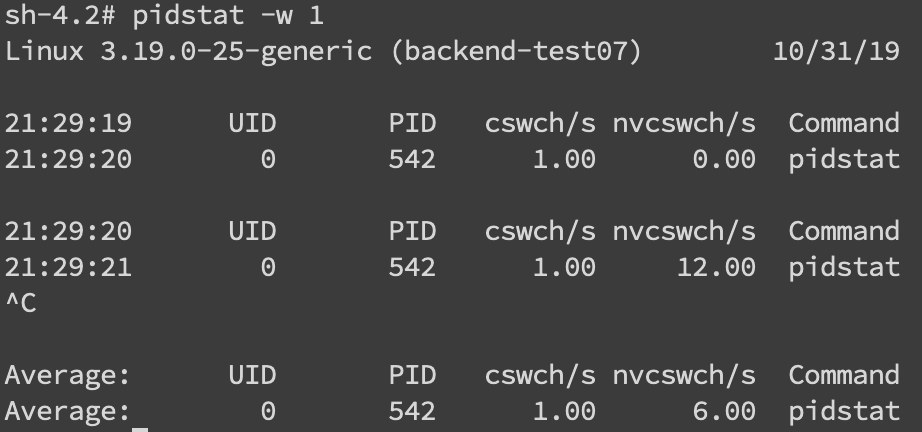
针对频繁上下文问题,我们可以使用vmstat命令来进行查看

cs(context switch)一列则代表了上下文切换的次数。
如果我们希望对特定的pid进行监控那么可以使用 pidstat -w pid命令,cswch和nvcswch表示自愿及非自愿切换。