查磁盘空间
查看磁盘剩余空间
查看磁盘剩余空间使用df -hl命令:
[root@localhost ~]# df -hl
文件系统 容量 已用 可用 已用% 挂载点
devtmpfs 678M 0 678M 0% /dev
tmpfs 695M 0 695M 0% /dev/shm
tmpfs 695M 28M 667M 4% /run
tmpfs 695M 0 695M 0% /sys/fs/cgroup
/dev/mapper/centos_aubin-root 27G 5.6G 22G 21% /
/dev/sda1 1014M 211M 804M 21% /boot
查看磁盘已使用空间
du -sh命令是查看磁盘已使用空间的情况,这里的“已使用的磁盘空间”意思是指定的文件下的整个文件层次结构所使用的空间,在没给定参数的情况下,du报告当前目录所使用的磁盘空间。其实就是显示文件或目录所占用的磁盘空间的情况 :
[root@localhost ~]# du -sh
64K
-
-h:输出文件系统分区使用的情况,例如:10KB,10MB,10GB等。 -
-s:显示文件或整个目录的大小,默认单位是KB。
du的详细信息可以通过man du查看。
查看磁盘读写情况
查看磁盘总体读写情况
通iostat查看磁盘总体的读写情况:
[root@localhost ~]# iostat
Linux 3.10.0-1062.el7.x86_64 (localhost.localdomain) 2020年05月02日 _x86_64_ (2 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.17 0.00 0.20 0.46 0.00 99.17
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 1.56 30.45 39.61 4659620 6060644
scd0 0.00 0.02 0.00 3102 0
dm-0 1.96 30.01 38.42 4591998 5878155
dm-1 0.09 0.09 0.30 13840 45328
-
tps:该设备每秒的传输次数。 -
kB_read/s:每秒从设备(drive expressed)读取的数据量; -
kB_wrtn/s:每秒向设备(drive expressed)写入的数据量; -
kB_read:读取的总数据量; -
kB_wrtn:写入的总数量数据量;
查看磁盘详细读写情况
通过iostat -x 1 3可以看到磁盘详细读写情况,没隔一秒输出一次一共输出3次,当看到I/O等待时间所占CPU时间的比重很高的时候,首先要检查的就是机器是否正在大量使用交换空间,同时关注iowait占比cpu的消耗是否很大,如果大说明磁盘存在大的瓶颈,同时关注await,表示磁盘的响应时间以便小于5ms:
[root@localhost ~]# iostat -x 1 3
Linux 3.10.0-1062.el7.x86_64 (localhost.localdomain) 2020年05月02日 _x86_64_ (2 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.17 0.00 0.20 0.46 0.00 99.16
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.01 0.49 0.63 0.95 30.59 39.78 89.58 0.34 214.23 49.16 323.48 8.55 1.34
scd0 0.00 0.00 0.00 0.00 0.02 0.00 98.48 0.00 1.21 1.21 0.00 0.95 0.00
dm-0 0.00 0.00 0.62 1.35 30.15 38.59 69.70 0.91 460.67 49.12 648.54 6.66 1.31
dm-1 0.00 0.00 0.02 0.07 0.09 0.30 8.52 0.04 442.74 95.43 521.17 6.91 0.06
avg-cpu表示总体cpu使用情况统计信息,对于多核cpu,这里为所有cpu的平均值:
-
%user:CPU处在用户模式下的时间百分比。 -
%nice:CPU处在带NICE值的用户模式下的时间百分比。 -
%system:CPU处在系统模式下的时间百分比。 -
%iowait:CPU等待输入输出完成时间的百分比,如果%iowait的值过高,表示硬盘存在I/O瓶颈 。 -
%steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。 -
%idle:CPU空闲时间百分比,如果%idle值高,表示CPU较空闲;如果%idle值高但系统响应慢时,可能是CPU等待分配内存,应加大内存容量;如果%idle值持续低于10,表明CPU处理能力相对较低,系统中最需要解决的资源是CPU。 。
Device表示设备信息:
-
rrqm/s:每秒对该设备的读请求被合并次数,文件系统会对读取同块(block)的请求进行合并 -
wrqm/s:每秒对该设备的写请求被合并次数 -
r/s:每秒完成的读次数 -
w/s:每秒完成的写次数 -
rkB/s:每秒读数据量(kB为单位) -
wkB/s:每秒写数据量(kB为单位) -
avgrq-sz:平均每次IO操作的数据量(扇区数为单位) -
avgqu-sz:平均等待处理的IO请求队列长度 -
await:平均每次IO请求等待时间(包括等待时间和处理时间,毫秒为单位) -
svctm:平均每次IO请求的处理时间(毫秒为单位) -
%util:一秒中有百分之多少的时间用于 I/O如果%util接近100%,说明产生的I/O请求太多,I/O系统已经满负荷。idle小于70% IO压力就较大了,一般读取速度有较多的wait。
iostat -xmd 1 3:新增m选项可以在输出是使用M为单位。
查看最耗IO的进程
一般先通过iostat查看是否存在io瓶颈,再使用iotop命令来定位那个进程最耗费IO:
[root@localhost ~]# iotop
Total DISK READ : 0.00 B/s | Total DISK WRITE : 0.00 B/s
Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
123931 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.02 % [kworker/1:30]
94208 be/4 xiaolyuh 0.00 B/s 0.00 B/s 0.00 % 0.00 % nautilus-desktop --force [gmain]
1 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % systemd --system --deserialize 62
2 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kthreadd]
94211 be/4 xiaolyuh 0.00 B/s 0.00 B/s 0.00 % 0.00 % gvfsd-trash --spawner :1.4 /org/gtk/gvfs/exec_spaw/0
4 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kworker/0:0H]
6 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [ksoftirqd/0]
7 rt/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [migration/0]
8 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [rcu_bh]
9 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [rcu_sched]
10 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [lru-add-drain]
...
我们可以通过iostat -d -k -x来进行分析
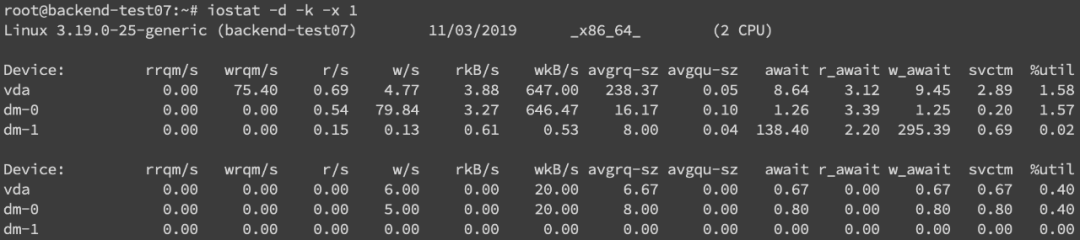
最后一列%util可以看到每块磁盘写入的程度,而rrqpm/s以及wrqm/s分别表示读写速度,一般就能帮助定位到具体哪块磁盘出现问题了。
另外我们还需要知道是哪个进程在进行读写,一般来说开发自己心里有数,或者用iotop命令来进行定位文件读写的来源。
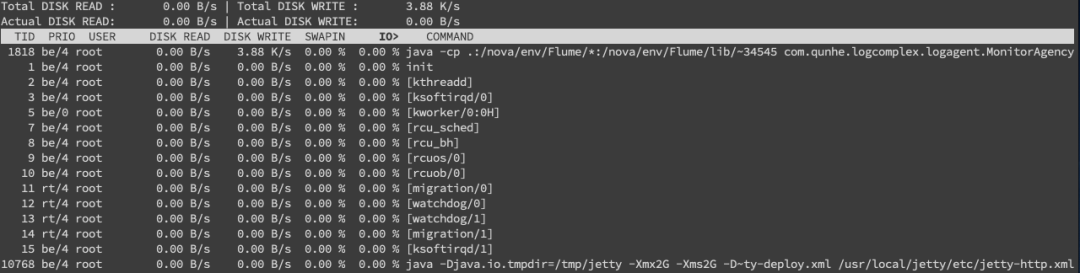
不过这边拿到的是tid,我们要转换成pid,可以通过readlink来找到pid,readlink -f /proc/*/task/tid/../..。

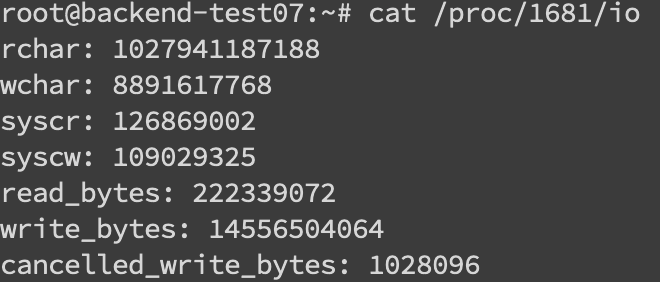
找到pid之后就可以看这个进程具体的读写情况cat /proc/pid/io
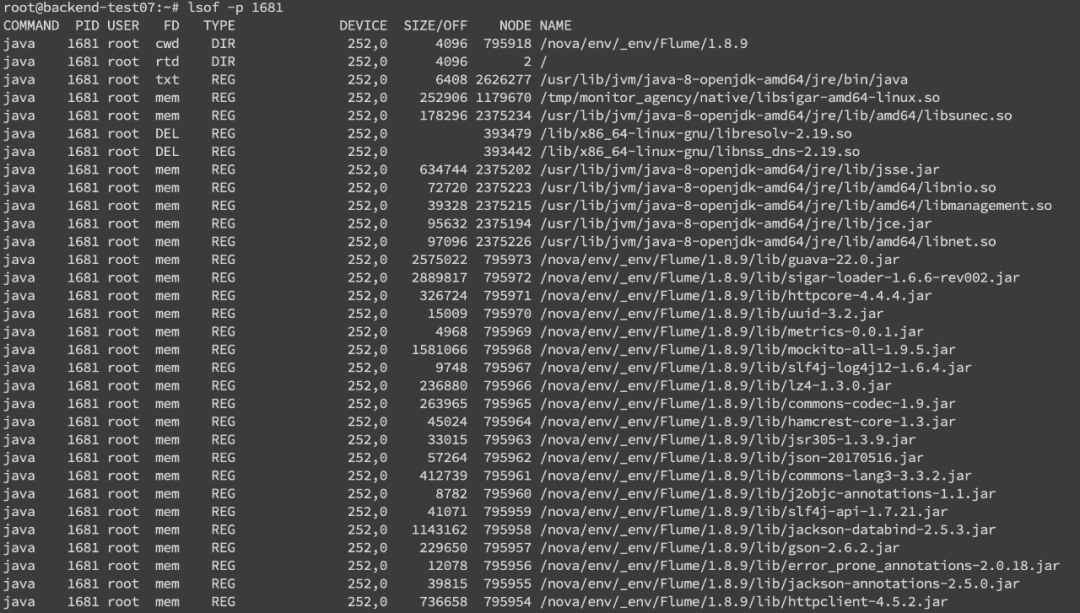
我们还可以通过lsof命令来确定具体的文件读写情况lsof -p pid
通过iotop -p pid可以查看单个进程的IO情况:
[root@localhost ~]# iotop -p 124146
Total DISK READ : 0.00 B/s | Total DISK WRITE : 0.00 B/s
Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
124146 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % java -jar arthas-demo.jar