参考:
1、https://www.oschina.net/p/openmp?hmsr=aladdin1e1
嵌入式算法移植优化学习笔记1——openmp
1、openmp简介
openmp概述
OpenMP是由OpenMP Architecture Review Board牵头提出的,并已被广泛接受,用于共享内存并行系统的多处理器程序设计的一套指导性编译处理方案(Compiler Directive) 。OpenMP支持的编程语言包括C、C++和Fortran;而支持OpenMp的编译器包括Sun Compiler,GNU Compiler和Intel Compiler等。OpenMp提供了对并行算法的高层的抽象描述,程序员通过在源代码中加入专用的pragma来指明自己的意图,由此编译器可以自动将程序进行并行化,并在必要之处加入同步互斥以及通信。当选择忽略这些pragma,或者编译器不支持OpenMp时,程序又可退化为通常的程序(一般为串行),代码仍然可以正常运作,只是不能利用多线程来加速程序执行。
OpenMP提供的这种对于并行描述的高层抽象降低了并行编程的难度和复杂度,这样程序员可以把更多的精力投入到并行算法本 身,而非其具体实现细节。对基于数据分集的多线程程序设计,OpenMP是一个很好的选择。同时,使用OpenMP也提供了更强的灵活性,可以较容易的适 应不同的并行系统配置。线程粒度和负载平衡等是传统多线程程序设计中的难题,但在OpenMP中,OpenMP库从程序员手中接管了部分这两方面的工作。
但是,作为高层抽象,OpenMP并不适合需要复杂的线程间同步和互斥的场合。
OpenMP的另一个缺点是不能在非共享内存系统(如计算机集群)上使用。在这样的系统上,MPI使用较多。
openMP执行模式
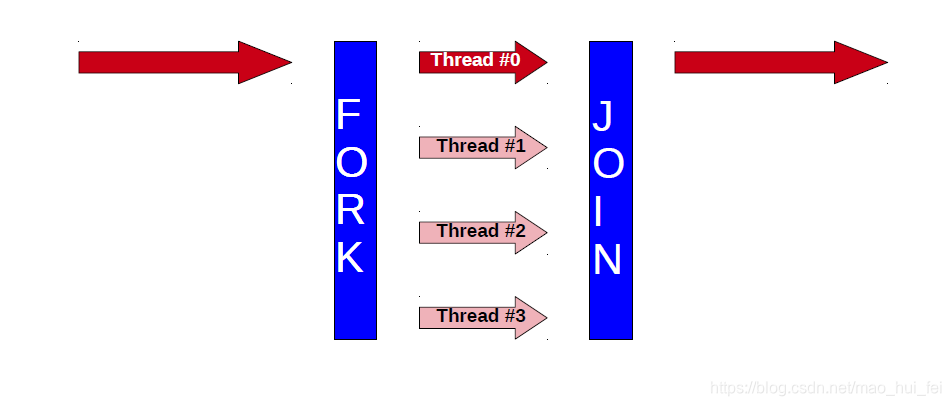
OpenMP采用fork-join的执行模式。开始的时候只存在一个主线程,当需要进行并行计算的时候,派生出若干个分支线程来执行并行任务。当并行代码执行完成之后,分支线程会合,并把控制流程交给单独的主线程。
一个典型的fork-join执行模型的示意图如下:
OpenMP线程与内核
- 线程是独立的程序代码执行序列
- 代码块只有一个入口和一个出口
- 与核心/CPU无关
- OpenMP的线程们都映射到物理核心们上
- 可以在一个核心上映射多个线程
- 实际上,线程和核心最好是一对一的映射。
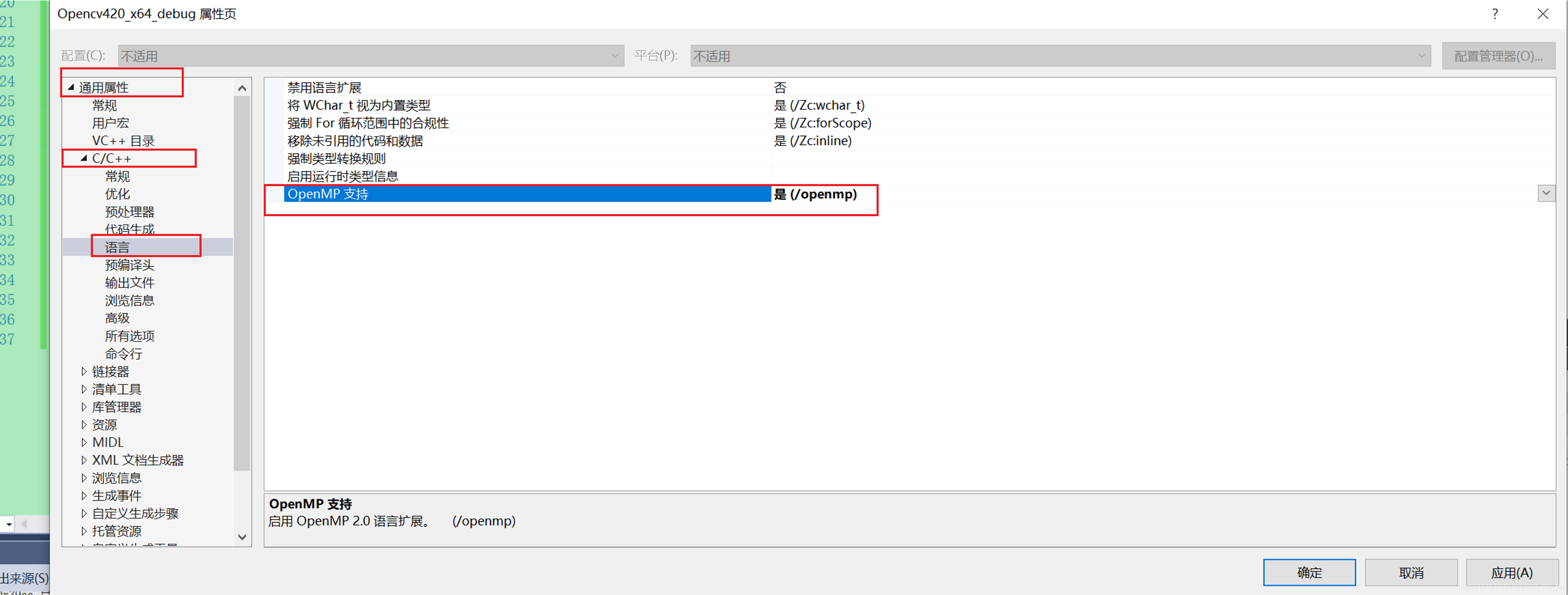
2、vs2015如何打开openmp功能
3、代码示例
3.1未使用openmp
#include <omp.h>
#include <stdio.h>
#include <stdlib.h>
#include <windows.h>
#include <time.h>
void Test(int n)
{
for (int i = 0; i < 100000000; ++i)
{
//do nothing, just waste time
i++;
}
printf("%d, ", n);
}
int main(int argc, char *argv[])
{
int i;
clock_t begin = clock();
//#pragma omp parallel for
for (i = 0; i < 100; ++i)
{
Test(i);
}
clock_t end = clock();
double time_consumption = (double)(end - begin) / CLOCKS_PER_SEC;
printf("\n ");
printf("耗时:%f", time_consumption);
printf("\n ");
system("pause");
return 1;
}
耗时:14.57s
3.2使用了openmp
加入:
#pragma omp parallel for
即可。
#include <omp.h>
#include <stdio.h>
#include <stdlib.h>
#include <windows.h>
#include <time.h>
void Test(int n)
{
for (int i = 0; i < 100000000; ++i)
{
//do nothing, just waste time
i++;
}
printf("%d, ", n);
}
int main(int argc, char *argv[])
{
int i;
clock_t begin = clock();
#pragma omp parallel for
for (i = 0; i < 100; ++i)
Test(i);
clock_t end = clock();
double time_consumption = (double)(end - begin) / CLOCKS_PER_SEC;
printf("\n ");
printf("耗时:%f", time_consumption);
printf("\n ");
system("pause");
return 1;
}
耗时:3.495s
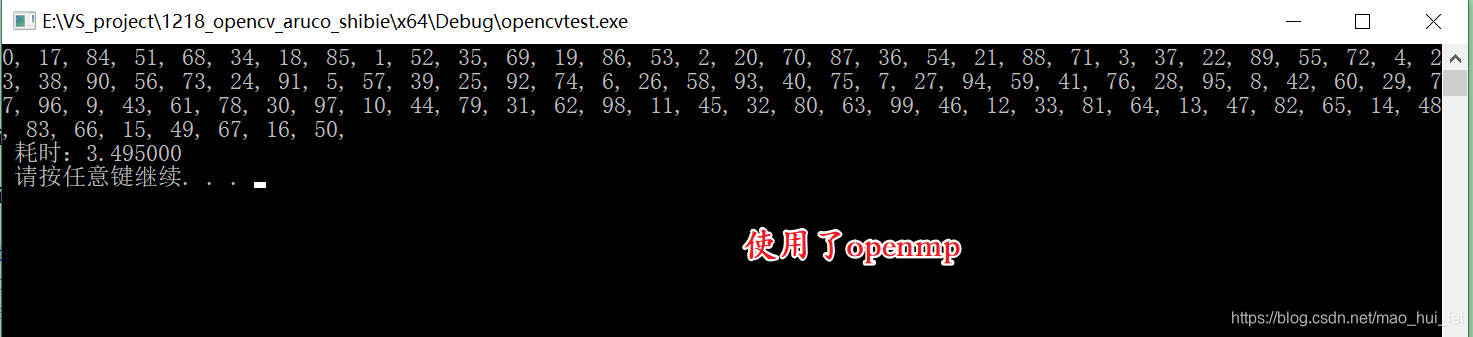
注意:在linux环境中,只需要将在gcc后面加入 -fopenmp选项即可。
4、openmp语法基础
需要使用openmp就需要引入omp.h库文件。然后在编译时添加参数 -fopenmp即可。 在具体需要进行并行运算的部分,使用 #pragma omp 指令[子句] 来告诉编译器如何并行执行对应的语句。 常用的指令如下:
| 指令 | 含义 |
|---|---|
| parallel | 即#pragma omp parallel 后面需要有一个代码片段,使用{}括起来,表示会被并行执行。 |
| parallel for | 这里后面跟for语句即可,不需要有额外的代码块。 |
| sections | |
| parallel sections | |
| single | 表示只能单线程执行 |
| critical | 临界区,表示每次只能有一个openmp线程进入 |
| barrier | 用于并行域内代码的线程同步,线程执行到barrier时停下来 ,直到所有线程都执行到barrier时才继续。 |
常用的子句如下:
| 指令 | 含义 |
|---|---|
| num_threads | 指定并行域内线程的数目 |
| shared | 指定一个或者多个变量为多个线程的共享变量 |
| private | 指定一个变量或者多个变量在每个线程中都有它的副本 |
另外,openmp还提供了一些列的api函数来获取并行线程的状态或控制并行线程的行为,常用api如下:
| 指令 | 含义 |
|---|---|
| num_threads | 指定并行域内线程的数目 |
| shared | 指定一个或者多个变量为多个线程的共享变量 |
| private | 指定一个变量或者多个变量在每个线程中都有它的副本 |
| omp_in_parallel | 判断当前是否在并行域中 |
| omp_get_thread_num | 获取线程号 |
| omp_set_num_threads | 设置并行域中线程格式 |
| omp_get_num_threads | 设置并行域中线程格式 |
| omp_get_dynamic | 判断是否支持动态改变线程数目 |
| omp_get_max_threads | 获取并行域中可用的最大的并行线程数目 |
| omp_get_num_procs | 返回系统中处理器的个数 |
4.1 示例
使用num_threads(3)限制并行线程数为3
#pragma omp parallel num_threads(3)
4.2 不同线程数下运行效率
我的电脑是6个线程的
#include <iostream>
#include <windows.h>
#include <omp.h>
using namespace std;
void test()
{
int j = 0;
for (int i = 0; i < 100000; i++)
{
// do something to kill time...
j++;
}
};
int main()
{
double startTime;
double endTime;
// 不使用openMp
startTime = omp_get_wtime();
for (int i = 0; i < 100000; i++)
{
test();
}
endTime = omp_get_wtime();
cout << "single thread cost time: " << endTime - startTime << endl;
// 2个线程
startTime = omp_get_wtime();
#pragma omp parallel for num_threads(2)
for (int i = 0; i < 100000; i++)
{
test();
}
endTime = omp_get_wtime();
cout << "2 threads cost time: " << endTime - startTime << endl;
// 4个线程
startTime = omp_get_wtime();
#pragma omp parallel for num_threads(4)
for (int i = 0; i < 100000; i++)
{
test();
}
endTime = omp_get_wtime();
cout << "4 threads cost time: " << endTime - startTime << endl;
// 6个线程
startTime = omp_get_wtime();
#pragma omp parallel for num_threads(6)
for (int i = 0; i < 100000; i++)
{
test();
}
endTime = omp_get_wtime();
cout << "6 threads cost time: " << endTime - startTime << endl;
// 8个线程
startTime = omp_get_wtime();
#pragma omp parallel for num_threads(8)
for (int i = 0; i < 100000; i++)
{
test();
}
endTime = omp_get_wtime();
cout << "8 threads cost time: " << endTime - startTime << endl;
// 10个线程
startTime = omp_get_wtime();
#pragma omp parallel for num_threads(10)
for (int i = 0; i < 100000; i++)
{
test();
}
endTime = omp_get_wtime();
cout << "10 threads cost time: " << endTime - startTime << endl;
// 12个线程
startTime = omp_get_wtime();
#pragma omp parallel for num_threads(12)
for (int i = 0; i < 100000; i++)
{
test();
}
endTime = omp_get_wtime();
cout << "12 threads cost time: " << endTime - startTime << endl;
system("pause");
return 0;
}
效果图
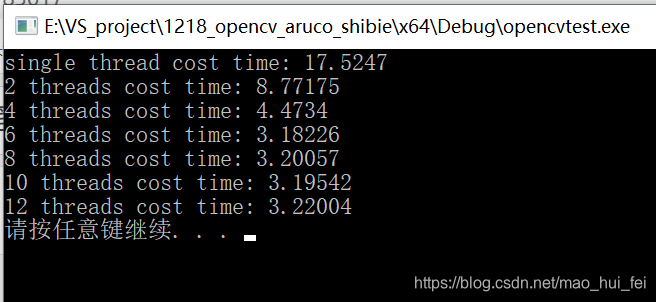
说明:
我们可以看到,单线程(不使用openMP)时消耗时间最长,2线程约为单线程的一半,4个线程(本电脑为4个逻辑内核)约为1/3时间,6个线程的时候时间稍微短一些,8、10、12、个线程在时间上也没有明显额减少,甚至略有增加,所以,线程数的制定可以根据电脑的核心数来做出选择。
4.3 变量申请
在并行区域内声明了一个变量private_a,那么在多线程执行时,每个线程都会创建这么一个private_a变量。
最终输出结果为668/668/669/669,说明2个线程加了两次,2个线程加了3次
/* 在并行区域内声明了一个变量private_a,那么在多线程执行时,每个线程都会创建这么一个private_a变量。
最终输出结果为668/668/669/669,说明2个线程加了两次,2个线程加了3次。*/
#pragma omp parallel
{
int private_a = 666;
#pragma omp for
for (int i = 0; i < 10; i++)
{
test(i);
private_a++;
}
cout << private_a << endl;
}
在并行区域之外定义的变量是共享的,即使下面有多个线程并行执行for循环,但是不会为每个线程创建share_a变量,所以最终每个线程访问的都是同一个内存,输出的结果为4个676
/*在并行区域之外定义的变量是共享的,即使下面有多个线程并行执行for循环,
但是不会为每个线程创建share_a变量,所以最终每个线程访问的都是同一个内存,
输出的结果为4个676*/
int share_a = 666;
#pragma omp parallel
{
#pragma omp for
for (int i = 0; i < 10; i++)
{
test(i);
share_a++;
}
cout << share_a << endl;
}
4.4 线程同步之atomic
对某一块代码操作进行保护,以保证同时只能有一个线程执行该段代码。
示例代码:
/*下面的两个例子中一个使用了原子操作,一个没有使用原子操作。
使用原子操作的最后结果正确且稳定,而没有使用原子操作最终的结果是不稳定的。*/
int sum = 0;
cout << "Before: " << sum << endl;
#pragma omp parallel for
for (int i = 0; i < 20000; i++)
{
#pragma omp atomic
sum++;
}
cout << "Atomic-After: " << sum << endl;
// int sum = 0;
sum = 0;
#pragma omp parallel for
for (int i = 0; i < 20000; i++)
{
sum++;
}
cout << "None-atomic-After: " << sum << endl;

4.5 OpenMP 线程同步之critical (临界区)
多核/多线程编程中肯定会用到同步互斥操作。除了互斥变量以为,就是临界区。临界区是指在用一时刻只允许一个线程执行的一段用{…},包围的代码段。
在OpenMP中临界区声明方法如下:
#pragma omp critical [(name)] //[]表示名字可选
{
//需要同一时刻只能有一个线程访问的代码
}
示例代码:
/* 线程同步之critical
使用critical得到的结果是稳定的,而不使用critical得到的结果是不稳定的。
值得注意的是:critical与atomic的区别在于 - atomic仅仅使用自增(++、--等)或者简化(+=、-=等)两种方式,
并且只能表示下一句,而critical却没有限制,且可以通过{}代码块来表示多句同时只能有一个线程来访问。*/
int sum = 0;
cout << "Before: " << sum << endl;
#pragma omp parallel for
for (int i = 0; i < 100; i++)
{
#pragma omp critical(a)
{
sum = sum + i;
sum = sum + i * 2;
}
}
cout << "After: " << sum << endl;
效果图:
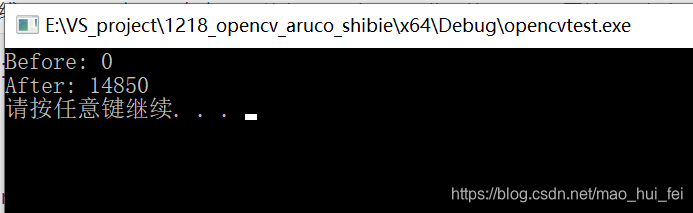
注意:
使用critical得到的结果是稳定的,而不使用critical得到的结果是不稳定的。值得注意的是:critical与atomic的区别在于 atomic仅仅使用自增(++、–等)或者简化(+=、-=等)两种方式,并且只能表示下一句,而critical却没有限制,且可以通过{}代码块来表示多句同时只能有一个线程来访问。
4.6 #pragma omp for nowait——取消栅障
barrier为隐式栅障,即并行区域中所有线程执行完毕之后,主线程才继续执行。而nowait的声明即可取消栅障,这样,即使并行区域内即使所有的线程还没有执行完, 但是执行完了的线程也不必等待所有线程执行结束,而可自动向下执行。
#if 0
/* 同时运行下面的两个程序,可以发现有些许不同。
这个程序中的第一个for循环会多线程执行,并且如果一个线程执行完,如果有的线程没有执行完,
那么就会等到所有线程执行完了再继续向下执行。所以结果中 - 和 + 区分清晰。*/
#pragma omp parallel
{
#pragma omp for
for (int j = 666; j < 1000; j++)
{
cout << "-" << endl;
}
#pragma omp for nowait
for (int i = 0; i < 100; i++)
{
cout << "+" << endl;
}
}
#endif
/*这个程序中的第一个for循环同样会有多个线程同时执行,只是其中某个线程最先执行完了之后,
不会等其他的线程,而是直接进入了下一个for循环,所以结果中的 - 和 + 在中间部分是混杂的。*/
#pragma omp parallel
{
#pragma omp for nowait
for (int i = 0; i < 100; i++)
{
cout << "+" ;
}
#pragma omp for
for (int j = 666; j < 1000; j++)
{
cout << "-" ;
}
}
4.7 #pragma omp barrier——隐式栅障
/*这个程序中的第一个for循环同样会有多个线程同时执行,只是其中某个线程最先执行完了之后,
不会等其他的线程,而是直接进入了下一个for循环,所以结果中的 - 和 + 在中间部分是混杂的。*/
#pragma omp parallel
{
#pragma omp for nowait
for (int i = 0; i < 100; i++)
{
cout << "+" ;
}
#pragma omp for
for (int j = 666; j < 1000; j++)
{
cout << "-" ;
}
}
/*可知,barrier为隐式栅障,即并行区域中所有线程执行完毕之后,主线程才继续执行。
而nowait的声明即可取消栅障,这样,即使并行区域内即使所有的线程还没有执行完,
但是执行完了的线程也不必等待所有线程执行结束,而可自动向下执行。*/
printf("\n\n\n");
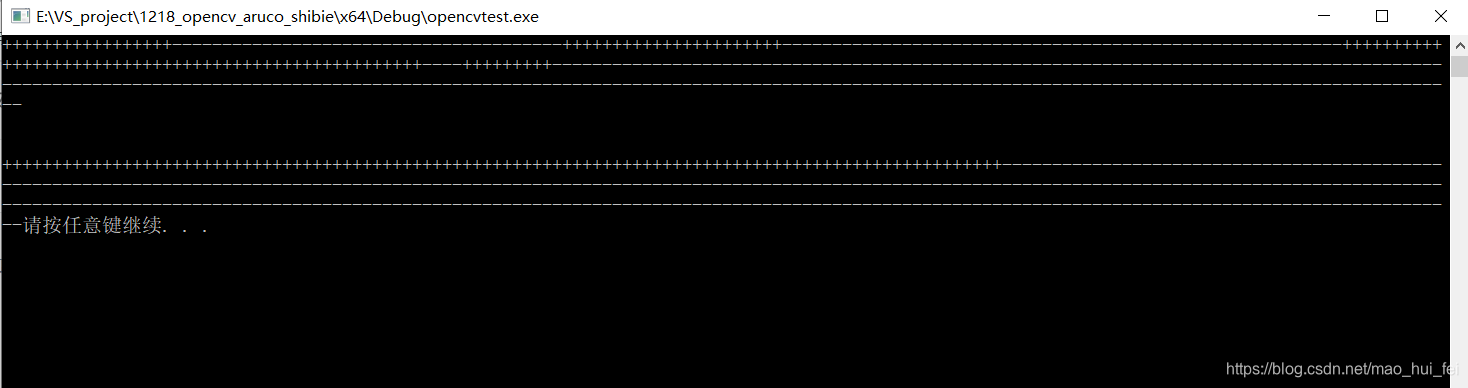
/* 如下所示正常来说应该是第一个for循环中的一个线程执行完之后nowait进入下一个for循环,
但是我们通过 #pragma omp barrier 来作为显示同步栅障,即让这个先执行完的线程等待所有线程执行完毕再进行下面的运算*/
#pragma omp parallel
{
#pragma omp for nowait
for (int i = 0; i < 100; i++)
{
cout << "+" ;
}
#pragma omp barrier//等待for循环中所有线程运行结束,再运行下面的
#pragma omp for
for (int j = 666; j < 1000; j++)
{
cout << "-" ;
}
}
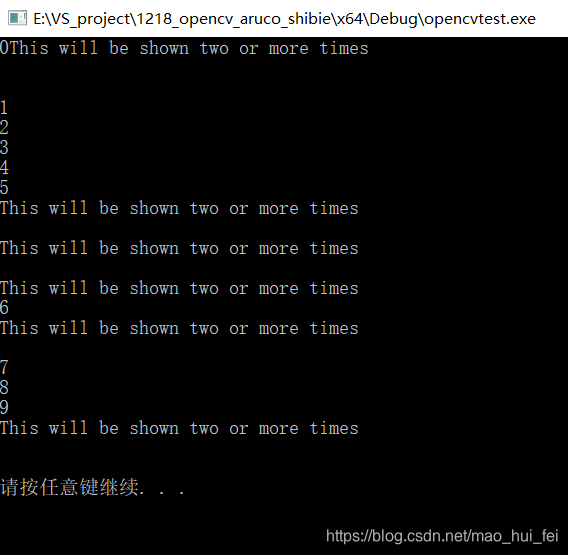
4.8 #pragma omp master——主线程执行for循环
/*这里我们通过#pragma omp master来让主线程执行for循环,然后其他的线程执行后面的cout语句,
所以,cout的内容会出现在for循环多次(这取决于你电脑的性能),最后,主线程执行完for语句后,也会执行一次cout*/
#pragma omp parallel
{
#pragma omp master/**/
{
for (int i = 0; i < 10; i++)
{
cout << i << endl;
}
}
cout << "This will be shown two or more times\n" << endl;
}
4.9 #pragma omp parallel sections——指定部分的代码运行在特定线程
使用section可以指定不同的线程来执行不同的部分,如下所示,通过#pragma omp parallel sections来指定不同的section由不同的线程执行最后得到的结果是多个for循环是混杂在一起的。
/*使用section可以指定不同的线程来执行不同的部分
如下所示,通过#pragma omp parallel sections来指定不同的section由不同的线程执行
最后得到的结果是多个for循环是混杂在一起的*/
#pragma omp parallel sections
{
#pragma omp section
for (int i = 0; i < 10; i++)
{
cout << "+";
}
#pragma omp section
for (int j = 0; j < 10; j++)
{
cout << "-";
}
#pragma omp section
for (int k = 0; k < 10; k++)
{
cout << "*";
}
}