嵌入式算法移植优化学习笔记2——SIMD编程(单指令流和多数据流)
一、SIMD概念
Single Instruction Multiple Data,也就是单指令流和多数据流,对于多数据流进行相同的操作。Single instruction, multiple data (SIMD)是并行计算机的一类(按照Flynn分类法)。它描述了具有多个处理元素(multiple processing elements)的计算机,可以在多个数据点(data points)上同时(simultaneously)完成相同的操作。这种机器利用数据级并行(data level parallelism)(不是并发, concurrency): 在某一时刻,只有一个指令,但有多个同时发生的(simultaneous)计算(computations),也即并行计算。SIMD特别适用于一些常见的任务,例如:调整数字图像的对比度,或者调整数字音频的音量。大部分现代CPU设计都包含了SIMD指令,来提高多媒体使用的性能。不要把SIMD和SIMT搞混了,前者在data level工作,后者要利用线程。一个简单的例子就是向量的加减。
和MIMD的区别
SIMD拥有单个全局控制单元,而后者拥有多个控制单元+处理元素。
二、SIMD的应用
- 图像处理
- 音频
- 科学计算
- 基于数据的数据并行计算。
什么情况下适合应用SIMD
- 规律的数据访问模式:数据在内存中连续存储。
- 短数据类型
- 流式数据处理
……
三、使用SIMD的优缺点
优点
- 具有更大的并发度。
- 设计比较简单(应该是与MIMD对比,只需要重复功能单元即可)。
芯片尺寸更小。
缺点
- 程序员开发时必须显式接触硬件。
四、SIMD并行的问题
SIMD并行开发,可以把多次相同的算术运算简化为一个SIMD操作;多个取数/存结果的操作,可以变成一个对于更宽的内存的一次操作(前提是内存需要连续)。
五、SIMD编程的复杂性
低层编程要求:
- 数据必须对齐。
- 数据放在连续区域存储。
- 控制流问题可能会引入更高的复杂性。
六、SIMD发展
所谓的SIMD指令,指的是single instruction multiple data,即单指令多数据运算,其目的就在于帮助CPU实现数据并行,提高运算效率。
MMX
MMX是由57条指令组成的SIMD多媒体指令集,MMX将64位寄存当作2个32位或8个8位寄存器来用,只能处理整形计算,这样的64位寄存器有8组,分别命名为MM0~MM7.这些寄存器不是为MMX单独设置的,而是借用的FPU的寄存器,占用浮点寄存器进行运算(64位MMX寄存器实际上就是浮点数寄存器的别名),以至于MMX指令和浮点数操作不能同时工作。为了减少在MMX和浮点数模式切换之间所消耗的时间,程序员们尽可能减少模式切换的次数,也就是说,这两种操作在应用上是互斥的。
SSE
SSE全称是Streaming SIMD Extensions,是一种在MMX基础上发展出来的SIMD指令集,其不再占用浮点寄存器,而是使用单独的128位XMM寄存器。在此基础上又发展除了SSE2/SSE3/SSE4指令集。SSE2则进一步支持双精度浮点数,由于寄存器长度没有变长,所以只能支持2个双精度浮点计算或是4个单精度浮点计算,另外,它在这组寄存器上实现了整型计算,从而代替了MMX。SSE3支持一些更加复杂的算术计算。SSE4增加了更多指令,并且在数据搬移上下了一番工夫,支持不对齐的数据搬移,增加了super shuffle引擎等。
AVX
在SSE指令集的基础上将128位的XMM寄存器扩展为长度为256位的YMM寄存器,使其支持256位的矢量计算,并且AVX全面兼容SSE/SSE2/SSE3/SSE4,也就是YMM寄存器的低128位就是XMM寄存器。
3DNow!
3DNow!是对于Intel MMX寄存器的逻辑拓展,MMX仅提供了并行的整数操作,3DNow!实现了并行浮点操作。3DNow!在现有MMX指令集基础上拓展可以做到混合操作整数代码和浮点代码,同时不需要MMX必须的上下文转换。
七、相关代码示例
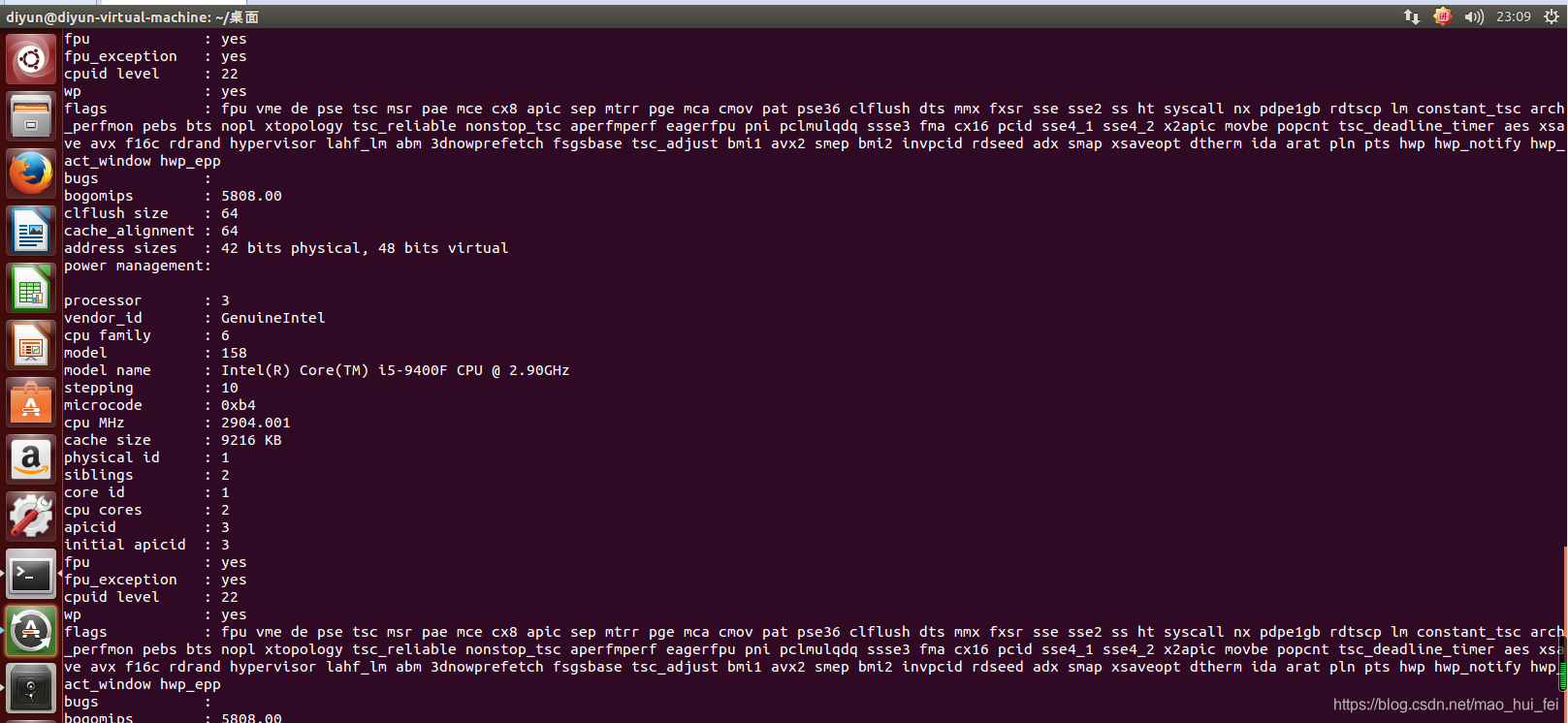
查看CPU支持的SIMD指令集
cat /proc/cpuinfo
可以看到编译器支持的SIMD指令集
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts nopl xtopology tsc_reliable nonstop_tsc aperfmperf eagerfpu pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch fsgsbase tsc_adjust bmi1 avx2 smep bmi2 invpcid rdseed adx smap xsaveopt dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp
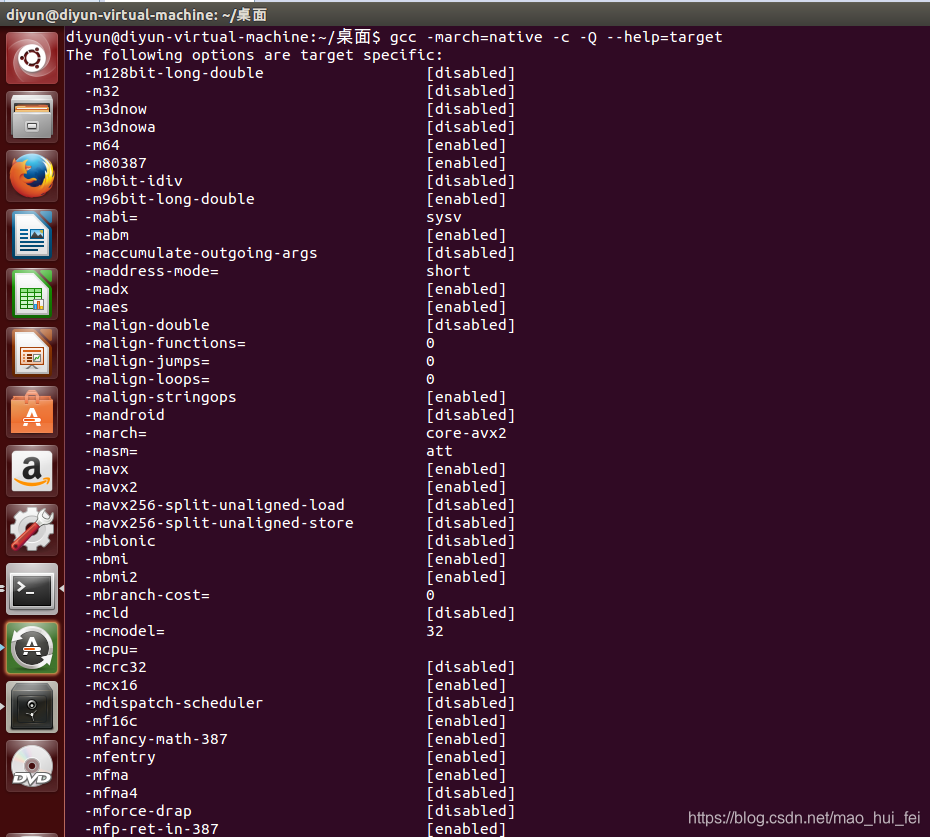
查看GCC处理器支持的SIMD指令集
gcc -march=native -c -Q --help=target
可以看到支持和不支持的SIMD指令集:
diyun@diyun-virtual-machine:~/桌面$ gcc -march=native -c -Q --help=target
The following options are target specific:
-m128bit-long-double [disabled]
-m32 [disabled]
-m3dnow [disabled]
-m3dnowa [disabled]
-m64 [enabled]
-m80387 [enabled]
-m8bit-idiv [disabled]
-m96bit-long-double [enabled]
-mabi= sysv
-mabm [enabled]
-maccumulate-outgoing-args [disabled]
-maddress-mode= short
-madx [enabled]
-maes [enabled]
-malign-double [disabled]
-malign-functions= 0
-malign-jumps= 0
-malign-loops= 0
-malign-stringops [enabled]
-mandroid [disabled]
-march= core-avx2
-masm= att
-mavx [enabled]
-mavx2 [enabled]
-mavx256-split-unaligned-load [disabled]
-mavx256-split-unaligned-store [disabled]
-mbionic [disabled]
-mbmi [enabled]
-mbmi2 [enabled]
-mbranch-cost= 0
-mcld [disabled]
-mcmodel= 32
-mcpu=
-mcrc32 [disabled]
-mcx16 [enabled]
-mdispatch-scheduler [disabled]
-mf16c [enabled]
-mfancy-math-387 [enabled]
-mfentry [enabled]
-mfma [enabled]
-mfma4 [disabled]
-mforce-drap [disabled]
-mfp-ret-in-387 [enabled]
-mfpmath= 387
-mfsgsbase [enabled]
-mfunction-return= keep
-mfused-madd
-mfxsr [enabled]
-mglibc [enabled]
-mhard-float [enabled]
-mhle [disabled]
-mieee-fp [enabled]
-mincoming-stack-boundary= 0
-mindirect-branch-register [disabled]
-mindirect-branch= keep
-minline-all-stringops [disabled]
-minline-stringops-dynamically [disabled]
-mintel-syntax
-mlarge-data-threshold= 0x10000
-mlong-double-64 [disabled]
-mlong-double-80 [enabled]
-mlwp [disabled]
-mlzcnt [enabled]
-mmmx [disabled]
-mmovbe [enabled]
-mms-bitfields [disabled]
-mno-align-stringops [disabled]
-mno-fancy-math-387 [disabled]
-mno-push-args [disabled]
-mno-red-zone [disabled]
-mno-sse4 [disabled]
-momit-leaf-frame-pointer [disabled]
-mpc32 [disabled]
-mpc64 [disabled]
-mpc80 [disabled]
-mpclmul [enabled]
-mpopcnt [enabled]
-mprefer-avx128 [disabled]
-mpreferred-stack-boundary= 0
-mprfchw [enabled]
-mpush-args [enabled]
-mrdrnd [enabled]
-mrdseed [enabled]
-mrecip [disabled]
-mrecip=
-mred-zone [enabled]
-mregparm= 0
-mrtd [disabled]
-mrtm [disabled]
-msahf [enabled]
-msoft-float [disabled]
-msse [enabled]
-msse2 [enabled]
-msse2avx [disabled]
-msse3 [enabled]
-msse4 [enabled]
-msse4.1 [enabled]
-msse4.2 [enabled]
-msse4a [disabled]
-msse5
-msseregparm [disabled]
-mssse3 [enabled]
-mstack-arg-probe [disabled]
-mstackrealign [enabled]
-mstringop-strategy= [default]
-mtbm [disabled]
-mtls-dialect= gnu
-mtls-direct-seg-refs [enabled]
-mtune= generic
-muclibc [disabled]
-mveclibabi= [default]
-mvect8-ret-in-mem [disabled]
-mvzeroupper [disabled]
-mx32 [disabled]
-mxop [disabled]
-mxsave [enabled]
-mxsaveopt [enabled]
Known assembler dialects (for use with the -masm-dialect= option):
att intel
Known ABIs (for use with the -mabi= option):
ms sysv
Known code models (for use with the -mcmodel= option):
32 kernel large medium small
Valid arguments to -mfpmath=:
387 387+sse 387,sse both sse sse+387 sse,387
Known indirect branch choices (for use with the -mindirect-branch=/-mfunction-return= options):
keep thunk thunk-extern thunk-inline
Known vectorization library ABIs (for use with the -mveclibabi= option):
acml svml
Known address mode (for use with the -maddress-mode= option):
long short
Valid arguments to -mstringop-strategy=:
byte_loop libcall loop rep_4byte rep_8byte rep_byte unrolled_loop
Known TLS dialects (for use with the -mtls-dialect= option):
gnu gnu2
SIMD指令使用举例
简单浮点数矩阵乘法(编译器优化)
float_matrix_mutiply.c:
#include <stdio.h>
#include <stdio.h>
void printf_matrix(int x,int y,double a[x][y])
{
for(int i=0;i<x;i++){
for(int j=0;j<y;j++){
printf("%lf ",a[i][j]);
}
printf("\n");
}
}
int main()
{
int M=2,N=3,P=4;
double matrix1[M][N];
double matrix2[N][P];
FILE *fp1,*fp2;
fp1 = fopen("./matrix1","r");
fp2 = fopen("./matrix2","r");
int i = 0;
while(!feof(fp1)){
fscanf(fp1,"%lf %lf %lf",&matrix1[i][0],&matrix1[i][1],&matrix1[i][2]);
i++;
}
printf("The first matrix is:\n");
printf_matrix(M,N,matrix1);
int j = 0;
while(!feof(fp2)){
fscanf(fp2,"%lf %lf %lf %lf",&matrix2[j][0],&matrix2[j][1],&matrix2[j][2],&matrix2[j][3]);
j++;
}
printf("The second matrix is:\n");
printf_matrix(N,P,matrix2);
double result[M][P];
for(int i=0;i<M;i++){
for(int k=0;k<P;k++){
for(int j=0;j<N;j++){
result[i][k] += matrix1[i][j]*matrix2[j][k];
}
}
}
printf("The matrix mutilpy result is:\n");
printf_matrix(M,P,result);
}
编译:
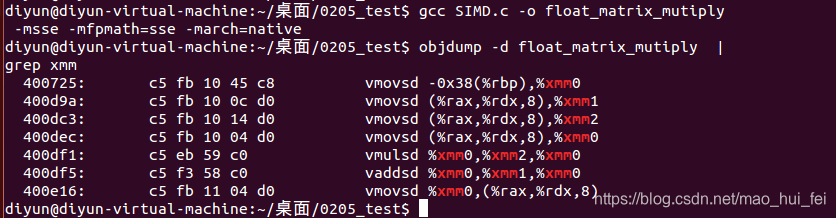
gcc float_matrix_mutiply.c -o float_matrix_mutiply -msse -mfpmath=sse -march=native
反编译可以看到使用了xmm寄存器以及movsd这样的SIMD指令:
diyun@diyun-virtual-machine:~/桌面/0205_test$ objdump -d float_matrix_mutiply |grep xmm
400725: c5 fb 10 45 c8 vmovsd -0x38(%rbp),%xmm0
400d9a: c5 fb 10 0c d0 vmovsd (%rax,%rdx,8),%xmm1
400dc3: c5 fb 10 14 d0 vmovsd (%rax,%rdx,8),%xmm2
400dec: c5 fb 10 04 d0 vmovsd (%rax,%rdx,8),%xmm0
400df1: c5 eb 59 c0 vmulsd %xmm0,%xmm2,%xmm0
400df5: c5 f3 58 c0 vaddsd %xmm0,%xmm1,%xmm0
400e16: c5 fb 11 04 d0 vmovsd %xmm0,(%rax,%rdx,8)
3、https://zhuanlan.zhihu.com/p/71266408
4、https://www.cnblogs.com/xidian-wws/p/11023762.html
5、https://blog.csdn.net/weixin_42826139/article/details/86313717