
目录
5、用新值替换numpy.ndarray中满足条件的元素(数组本身已被修改)
6、用新值替换numpy.ndarray中满足条件的元素(数组本身不被修改)
12、两个numpy.ndarray去除另外一个中出现的元素
29、归一化numpy.ndarray使其值分布在0到1之间
30、求numpy.ndarray的softmax score
1、numpy导入、查看版本
import numpy as np#导入numpy
print(np.__version__)#查看numpy版本2、numpy创建1维数组
arr = np.arange(10)#创建0到1的1维数组
print(type(arr))
arr
3、numpy创建布尔型数组
#方法1
np.full((3, 3), True, dtype=bool)#创建3x3的布尔数组
#方法2
np.ones((3,3), dtype=bool)
4、取出numpy.ndarray中满足条件的元素
arr = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
arr[arr % 2 == 1]#被2整除余数为1的数组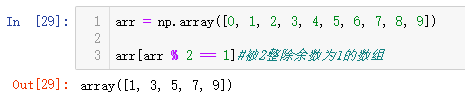
5、用新值替换numpy.ndarray中满足条件的元素(数组本身已被修改)
arr = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
print(arr)
arr[arr % 2 == 1] = -1#被2整除余数为1的元素替换为-1,此时arr本身被修改
arr
6、用新值替换numpy.ndarray中满足条件的元素(数组本身不被修改)
arr = np.arange(10)
out = np.where(arr % 2 == 1, -1, arr)
print(arr)#此时arr本身未被修改
out
7、numpy.ndarray从1维变换为2维
arr = np.arange(10)
arr.reshape(2, 5) # 第一个数字设置行数、第二个数字设置列数
8、垂直方向堆积两个numpy.ndarray
a = np.arange(10).reshape(2,-1)
b = np.repeat(1, 10).reshape(2,-1)
print('a numpy.ndarray:')
print(a)
print('b numpy.ndarray:')
print(b)
#方法1
np.concatenate([a, b], axis=0)
#方法2
np.vstack([a, b])
#方法3
np.r_[a, b]
9、水平方向堆积两个numpy.ndarray
a = np.arange(10).reshape(2,-1)
b = np.repeat(1, 10).reshape(2,-1)
print('a numpy.ndarray:')
print(a)
print('b numpy.ndarray:')
print(b)
#方法1
np.concatenate([a, b], axis=1)
#方法2
np.hstack([a, b])
#方法3
np.c_[a, b]
10、numpy函数输出指定数组
a = np.array([1,2,3])
np.r_[np.repeat(a, 3), np.tile(a, 3)]![]()
11、两个numpy.ndarray提取交集
a = np.array([1,2,3,2,3,4,3,4,5,6])
b = np.array([7,2,10,2,7,4,9,4,9,8])
np.intersect1d(a,b)![]()
12、两个numpy.ndarray去除另外一个中出现的元素
a = np.array([1,2,3,4,5])
b = np.array([5,6,7,8,9])
# 从 'a'去掉'b'中出现的元素
np.setdiff1d(a,b)![]()
13、提取两个numpy.ndarray相同元素的索引
a = np.array([1,2,3,2,3,4,3,4,5,6])
b = np.array([7,2,10,2,7,4,9,4,9,8])
np.where(a == b)![]()
14、提取numpy.ndarray中满足某个条件的元素
a = np.arange(15)
print(a)
#方法1
index = np.where((a >= 5) & (a <= 10))
a[index]
#方法2
index = np.where(np.logical_and(a>=5, a<=10))
a[index]
#方法3
a[(a >= 5) & (a <= 10)]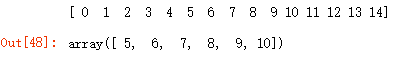
15、定义函数操作numpy.ndarray中元素
def maxx(x, y):
"""Get the maximum of two items"""
if x >= y:
return x
else:
return y
pair_max = np.vectorize(maxx, otypes=[float])
a = np.array([5, 7, 9, 8, 6, 4, 5])
b = np.array([6, 3, 4, 8, 9, 7, 1])
pair_max(a, b)![]()
16、改变numpy.ndarray中两列顺序
arr = np.arange(9).reshape(3,3)
print(arr)
arr[:, [1,0,2]]
17、改变numpy.ndarray中两行顺序
arr = np.arange(9).reshape(3,3)
print(arr)
arr[[1,0,2], :]
18、颠倒numpy.ndarray中各行顺序
import numpy as np
arr = np.arange(9).reshape(3,3)
print(arr)
arr[::-1]
19、颠倒numpy.ndarray中各列顺序
arr = np.arange(9).reshape(3,3)
print(arr)
arr[:, ::-1]
20、创建一个包含随机浮点数的numpy.ndarray
#方法1
rand_arr = np.random.randint(low=5, high=10, size=(5,3)) + np.random.random((5,3))
#方法2
rand_arr = np.random.uniform(5,10, size=(5,3))
print(rand_arr)
21、numpy.ndarray中所有元素保留三位小数
rand_arr = np.random.random([5,3])
np.set_printoptions(precision=3)
rand_arr[:4]
22、numpy.ndarray中所有元素使用科学计数法
np.random.seed(100)
rand_arr = np.random.random([3,3])/1e3
rand_arr

23、大numpy.ndarray省略部分元素
np.set_printoptions(threshold=6)
a = np.arange(15)
a![]()
24、大numpy.ndarray输出所有元素
import sys
np.set_printoptions(threshold=6)
a = np.arange(15)
np.set_printoptions(threshold=sys.maxsize)
a![]()
25、numpy.ndarray导入数据
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
iris = np.genfromtxt(url, delimiter=',', dtype='object')
iris[:3]
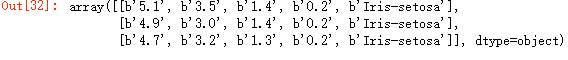
26、取出numpy.ndarray中某列
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
iris_1d = np.genfromtxt(url, delimiter=',', dtype=None)
print(iris_1d.shape)
# Solution:
species = np.array([row[4] for row in iris_1d])
species[:5]
27、一维numpy.ndarray转2维
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
iris_1d = np.genfromtxt(url, delimiter=',', dtype=None)
#方法1
iris_2d = np.array([row.tolist()[:4] for row in iris_1d])
iris_2d[:4]
#方法2
iris_2d = np.genfromtxt(url, delimiter=',', dtype='float', usecols=[0,1,2,3])
iris_2d[:4]
28、求numpy.ndarray的均值、中位数、标准差
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
iris = np.genfromtxt(url, delimiter=',', dtype='object')
sepallength = np.genfromtxt(url, delimiter=',', dtype='float', usecols=[0])
mu, med, sd = np.mean(sepallength), np.median(sepallength), np.std(sepallength)
print(mu, med, sd)![]()
29、归一化numpy.ndarray使其值分布在0到1之间
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
sepallength = np.genfromtxt(url, delimiter=',', dtype='float', usecols=[0])
#方法1
Smax, Smin = sepallength.max(), sepallength.min()
S = (sepallength - Smin)/(Smax - Smin)
#方法2
S = (sepallength - Smin)/sepallength.ptp()
S
30、求numpy.ndarray的softmax score
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
iris = np.genfromtxt(url, delimiter=',', dtype='object')
sepallength = np.array([float(row[0]) for row in iris])
def softmax(x):
"""Compute softmax values for each sets of scores in x.
https://stackoverflow.com/questions/34968722/how-to-implement-the-softmax-function-in-python"""
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum(axis=0)
print(softmax(sepallength))
31、求numpy.ndarray的分位数
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
sepallength = np.genfromtxt(url, delimiter=',', dtype='float', usecols=[0])
np.percentile(sepallength, q=[5, 95])![]()
32、numpy.ndarray的随机位置插入值
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
iris_2d = np.genfromtxt(url, delimiter=',', dtype='object')
#方法1
i, j = np.where(iris_2d)
np.random.seed(100)
iris_2d[np.random.choice((i), 20), np.random.choice((j), 20)] = np.nan
#方法2
np.random.seed(100)
iris_2d[np.random.randint(150, size=20), np.random.randint(4, size=20)] = np.nan
print(iris_2d[:10])
33、提取numpy.ndarray缺省值坐标
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
iris_2d = np.genfromtxt(url, delimiter=',', dtype='float', usecols=[0,1,2,3])
iris_2d[np.random.randint(150, size=20), np.random.randint(4, size=20)] = np.nan
print("Number of missing values: \n", np.isnan(iris_2d[:, 0]).sum())
print("Position of missing values: \n", np.where(np.isnan(iris_2d[:, 0])))
34、按多个条件过滤numpy.ndarray
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
iris_2d = np.genfromtxt(url, delimiter=',', dtype='float', usecols=[0,1,2,3])
condition = (iris_2d[:, 2] > 1.5) & (iris_2d[:, 0] < 5.0)
iris_2d[condition]
35、过滤numpy.ndarray中包含缺省值得行
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
iris_2d = np.genfromtxt(url, delimiter=',', dtype='float', usecols=[0,1,2,3])
iris_2d[np.random.randint(150, size=20), np.random.randint(4, size=20)] = np.nan
#方法1
any_nan_in_row = np.array([~np.any(np.isnan(row)) for row in iris_2d])
iris_2d[any_nan_in_row][:5]
#方法2
iris_2d[np.sum(np.isnan(iris_2d), axis = 1) == 0][:5]