
目录
43、numpy.ndarray按某个指标分类后求第二大的元素
46、输出numpy.ndarray中第一次大于给定元素的位置
47、使用给定值替换numpy.ndarray中满足条件的元素
48、获取numpy.ndarray中大小排前n的元素位置、元素
49、求numpy.ndarray的row wise counts
51、计算numpy.ndarray的one-hot encodings numpy.ndarray
52、create row numbers grouped by a categorical variable
53、create groud ids based on a given categorical variable
57、输出numpy.ndarray每行的最小值与最大值比值
66、numpy.ndarray数据格式从datetime64转换为datetime
36、求numpy.ndarray两列相关系数
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
iris = np.genfromtxt(url, delimiter=',', dtype='float', usecols=[0,1,2,3])
#方法1
np.corrcoef(iris[:, 0], iris[:, 2])[0, 1]
#方法2
from scipy.stats.stats import pearsonr
corr, p_value = pearsonr(iris[:, 0], iris[:, 2])
print(corr)37、判断numpy.ndarray中是否有null值
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
iris_2d = np.genfromtxt(url, delimiter=',', dtype='float', usecols=[0,1,2,3])
np.isnan(iris_2d).any() ![]()
38、使用指定值替代numpy.ndarray中的缺省值
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
iris_2d = np.genfromtxt(url, delimiter=',', dtype='float', usecols=[0,1,2,3])
iris_2d[np.random.randint(150, size=20), np.random.randint(4, size=20)] = np.nan
iris_2d[np.isnan(iris_2d)] = 0#使用0替代缺省值
iris_2d[:4]
39、计算numpy.ndarray元素频率
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
iris = np.genfromtxt(url, delimiter=',', dtype='object')
names = ('sepallength', 'sepalwidth', 'petallength', 'petalwidth', 'species')
species = np.array([row.tolist()[4] for row in iris])
# Get the unique values and the counts
np.unique(species, return_counts=True)![]()
40、将numpy.ndarray元素由数值型转换为分类型
'''
需求:
Less than 3 --> 'small'
3-5 --> 'medium'
'>=5 --> 'large'
'''
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
iris = np.genfromtxt(url, delimiter=',', dtype='object')
names = ('sepallength', 'sepalwidth', 'petallength', 'petalwidth', 'species')
# Bin petallength
petal_length_bin = np.digitize(iris[:, 2].astype('float'), [0, 3, 5, 10])
# Map it to respective category
label_map = {1: 'small', 2: 'medium', 3: 'large', 4: np.nan}
petal_length_cat = [label_map[x] for x in petal_length_bin]
# View
petal_length_cat[:4]![]()
41、由numpy.ndarray已知列得到新列
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
iris_2d = np.genfromtxt(url, delimiter=',', dtype='object')
#计算新列
sepallength = iris_2d[:, 0].astype('float')
petallength = iris_2d[:, 2].astype('float')
volume = (np.pi * petallength * (sepallength**2))/3
# 转换为iris_2d大小
volume = volume[:, np.newaxis]
#添加新列
out = np.hstack([iris_2d, volume])
out[:4]
42、numpy.ndarray概率抽样
#需求:抽样结果使得species中setose is twice the number of versicolor and virginica
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
iris = np.genfromtxt(url, delimiter=',', dtype='object')
# Get the species column
species = iris[:, 4]
#方法1
np.random.seed(100)
a = np.array(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'])
species_out = np.random.choice(a, 150, p=[0.5, 0.25, 0.25])
#方法2
np.random.seed(100)
probs = np.r_[np.linspace(0, 0.500, num=50), np.linspace(0.501, .750, num=50), np.linspace(.751, 1.0, num=50)]
index = np.searchsorted(probs, np.random.random(150))
species_out = species[index]
print(np.unique(species_out, return_counts=True))![]()
43、numpy.ndarray按某个指标分类后求第二大的元素
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
iris = np.genfromtxt(url, delimiter=',', dtype='object')
# Get the species and petal length columns
petal_len_setosa = iris[iris[:, 4] == b'Iris-setosa', [2]].astype('float')
# Get the second last value
np.unique(np.sort(petal_len_setosa))[-2]![]()
44、通过numpy.ndarray某一列排序
import numpy as np
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
iris = np.genfromtxt(url, delimiter=',', dtype='object')
names = ('sepallength', 'sepalwidth', 'petallength', 'petalwidth', 'species')
print(iris[iris[:,0].argsort()][:20])#按第一列排序
45、挑选numpy.ndarray中频数最高的元素
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
iris = np.genfromtxt(url, delimiter=',', dtype='object')
vals, counts = np.unique(iris[:, 2], return_counts=True)
print(vals[np.argmax(counts)])![]()
46、输出numpy.ndarray中第一次大于给定元素的位置
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
iris = np.genfromtxt(url, delimiter=',', dtype='object')
np.argwhere(iris[:, 3].astype(float) > 1.0)[0]![]()
47、使用给定值替换numpy.ndarray中满足条件的元素
#需求:numpy.ndarray中大于30的用30替换、小于10的用10替换
np.set_printoptions(precision=2)
np.random.seed(100)
a = np.random.uniform(1,50, 20)
#方法1
np.clip(a, a_min=10, a_max=30)
#方法2
print(np.where(a < 10, 10, np.where(a > 30, 30, a)))![]()
48、获取numpy.ndarray中大小排前n的元素位置、元素
np.random.seed(100)
a = np.random.uniform(1,50, 20)
##获取numpy.ndarray中大小排前5的元素位置
#方法1
print(a.argsort())
#方法2
np.argpartition(-a, 5)[:5]
##获取numpy.ndarray中大小排前5的元素
#方法1
a[a.argsort()][-5:]
#方法2
np.sort(a)[-5:]
#方法3
np.partition(a, kth=-5)[-5:]
#方法4
a[np.argpartition(-a, 5)][:5]
49、求numpy.ndarray的row wise counts
np.random.seed(100)
arr = np.random.randint(1,11,size=(6, 10))
print(arr)
def counts_of_all_values_rowwise(arr2d):
# Unique values and its counts row wise
num_counts_array = [np.unique(row, return_counts=True) for row in arr2d]
# Counts of all values row wise
return([[int(b[a==i]) if i in a else 0 for i in np.unique(arr2d)] for a, b in num_counts_array])
print(np.arange(1,11))
counts_of_all_values_rowwise(arr)
50、多个numpy.ndarray合成一个
arr1 = np.arange(3)
arr2 = np.arange(3,7)
arr3 = np.arange(7,10)
array_of_arrays = np.array([arr1, arr2, arr3])
print('array_of_arrays: ', array_of_arrays)
#方法
arr_2d = np.array([a for arr in array_of_arrays for a in arr])
#方法2
arr_2d = np.concatenate(array_of_arrays)
print(arr_2d)![]()
51、计算numpy.ndarray的one-hot encodings numpy.ndarray
np.random.seed(101)
arr = np.random.randint(1,4, size=6)
arr
print(arr)
# Solution:
def one_hot_encodings(arr):
uniqs = np.unique(arr)
out = np.zeros((arr.shape[0], uniqs.shape[0]))
for i, k in enumerate(arr):
out[i, k-1] = 1
return out
one_hot_encodings(arr)
52、create row numbers grouped by a categorical variable
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
species = np.genfromtxt(url, delimiter=',', dtype='str', usecols=4)
np.random.seed(100)
species_small = np.sort(np.random.choice(species, size=20))
print(species_small)
print([i for val in np.unique(species_small) for i, grp in enumerate(species_small[species_small==val])])
53、create groud ids based on a given categorical variable
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
species = np.genfromtxt(url, delimiter=',', dtype='str', usecols=4)
np.random.seed(100)
species_small = np.sort(np.random.choice(species, size=20))
print(species_small)
output = [np.argwhere(np.unique(species_small) == s).tolist()[0][0] for val in np.unique(species_small) for s in species_small[species_small==val]]
output

54、numpy.ndarray(一维)元素rank
np.random.seed(10)
a = np.random.randint(20, size=10)
print('Array: ', a)
print(a.argsort().argsort())![]()
55、numpy.ndarray(多维)元素rank
np.random.seed(10)
a = np.random.randint(20, size=[2,5])
print(a)
print(a.ravel().argsort().argsort().reshape(a.shape))
56、输出numpy.ndarray每行的最大元素
np.random.seed(100)
a = np.random.randint(1,10, [5,3])
print(a)
# 方法1
np.amax(a, axis=1)
#方法2
np.apply_along_axis(np.max, arr=a, axis=1)
57、输出numpy.ndarray每行的最小值与最大值比值
np.random.seed(100)
a = np.random.randint(1,10, [5,3])
print(a)
np.apply_along_axis(lambda x: np.min(x)/np.max(x), arr=a, axis=1)
58、判断numpy.ndarray中元素是否是第一次出现
np.random.seed(100)
a = np.random.randint(0, 5, 10)
# There is no direct function to do this as of 1.13.3
# Create an all True array
out = np.full(a.shape[0], True)
# Find the index positions of unique elements
unique_positions = np.unique(a, return_index=True)[1]
# Mark those positions as False
out[unique_positions] = False
print(out)![]()
59、求numpy.ndarray中每组元素的均值
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
iris = np.genfromtxt(url, delimiter=',', dtype='object')
names = ('sepallength', 'sepalwidth', 'petallength', 'petalwidth', 'species')
# No direct way to implement this. Just a version of a workaround.
numeric_column = iris[:, 1].astype('float') # sepalwidth
grouping_column = iris[:, 4] # species
# List comprehension version
[[group_val, numeric_column[grouping_column==group_val].mean()] for group_val in np.unique(grouping_column)]
# For Loop version
output = []
for group_val in np.unique(grouping_column):
output.append([group_val, numeric_column[grouping_column==group_val].mean()])
output
60、将PIL image转换为numpy.ndarray
from io import BytesIO
from PIL import Image
import PIL, requests
# Import image from URL
URL = 'https://upload.wikimedia.org/wikipedia/commons/8/8b/Denali_Mt_McKinley.jpg'
response = requests.get(URL)
# Read it as Image
I = Image.open(BytesIO(response.content))
# Optionally resize
I = I.resize([150,150])
# Convert to numpy array
arr = np.asarray(I)
# Optionaly Convert it back to an image and show
im = PIL.Image.fromarray(np.uint8(arr))
Image.Image.show(im)61、丢弃numpy.ndarray中所有缺省值
a = np.array([1,2,3,np.nan,5,6,7,np.nan])
print(a)
a[~np.isnan(a)]
62、计算两个numpy.ndarray的欧几里得距离
a = np.array([1,2,3,4,5])
b = np.array([4,5,6,7,8])
# Solution
dist = np.linalg.norm(a-b)
dist![]()
63、求numpy.ndarray的局部最大值位置
a = np.array([1, 3, 7, 1, 2, 6, 0, 1])
doublediff = np.diff(np.sign(np.diff(a)))
peak_locations = np.where(doublediff == -2)[0] + 1
peak_locations![]()
64、numpy.ndarray减法运算
#需求:Subtract the 1d array b_1d from the 2d array a_2d, such that each item of b_1d subtracts from respective row of a_2d.
a_2d = np.array([[3,3,3],[4,4,4],[5,5,5]])
b_1d = np.array([1,2,3])
print(a_2d - b_1d[:,None])
65、输出numpy.ndarray中元素第n次重复的位置
x = np.array([1, 2, 1, 1, 3, 4, 3, 1, 1, 2, 1, 1, 2])
print(x)
n = 5
#方法1:列表推导式
[i for i, v in enumerate(x) if v == 1][n-1]#输出元素1第5次重复的位置
#方法2
np.where(x == 1)[0][n-1]![]()
66、numpy.ndarray数据格式从datetime64转换为datetime
dt64 = np.datetime64('2018-02-25 22:10:10')
#方法1
from datetime import datetime
dt64.tolist()
#方法2
dt64.astype(datetime)![]()
67、计算numpy.ndarray数据窗口大小
def moving_average(a, n=3) :
ret = np.cumsum(a, dtype=float)
ret[n:] = ret[n:] - ret[:-n]
return ret[n - 1:] / n
np.random.seed(100)
Z = np.random.randint(10, size=10)
print('array: ', Z)
#方法1
moving_average(Z, n=3).round(2)
#方法2
np.convolve(Z, np.ones(3)/3, mode='valid') 
68、指定起始、终止、步长,构建numpy.ndarray
length = 10
start = 5
step = 3
def seq(start, length, step):
end = start + (step*length)
return np.arange(start, end, step)
seq(start, length, step)![]()
69、补齐非连续时间序列numpy.ndarray
dates = np.arange(np.datetime64('2018-02-01'), np.datetime64('2018-02-25'), 2)
print(dates)
#方法1
filled_in = np.array([
np.arange(date, (date + d)) for date, d in zip(dates, np.diff(dates))
]).reshape(-1)
output = np.hstack([filled_in, dates[-1]])
output
#方法2
out = []
for date, d in zip(dates, np.diff(dates)):
out.append(np.arange(date, (date + d)))
filled_in = np.array(out).reshape(-1)
output = np.hstack([filled_in, dates[-1]])
output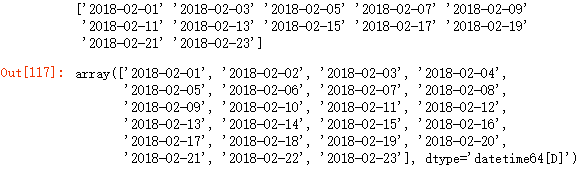
70、构建按指定步长滑窗的numpy.ndarray
import numpy as np
def gen_strides(a, stride_len=5, window_len=5):
n_strides = ((a.size - window_len) // stride_len) + 1
# return np.array([a[s:(s+window_len)] for s in np.arange(0, a.size, stride_len)[:n_strides]])
return np.array([
a[s:(s + window_len)]
for s in np.arange(0, n_strides * stride_len, stride_len)
])
print(gen_strides(np.arange(15), stride_len=2, window_len=4))