序列是python中最基本的数据结构,序列中的每一个元素都分配一个数字-他的位置或索引,第一个索引是0,第二个索引是1,以此类推
最常见的序列是列表和元组
列表
是python中最常用的数据类型,可以作为一个方括号内的逗号分隔值出现,
list1 = ['Google', 'Runoob', 1997, 2000];
list2 = [1, 2, 3, 4, 5 ];
list3 = ["a", "b", "c", "d"];
列表(list)是一种有序集合,可任意扩展,随时添加/删除元素,使用索引访问元素,如取最后一个元素可以采用list[-1]
基本操作
创建列表
list=['a','b','c','d']
追加元素append()
list.append('e')
print(list)
输出
['a', 'b', 'c', 'd', 'e']
2、删除:pop,remove,del
pop():尾部删除,pop()里携带下标,就会删除下标所对应的元素
list.pop() #输出 'e'
remove()
list.remove('e')
#输出list
['a', 'b', 'c', 'd']
del
del list[4] #输出list ['a', 'b', 'c', 'd']
3、查找元素所在位置:index()
list.index('c')
#输出
2
4、统计元素的次数:count()
list.append('d')
list.count('d')
#输出
2
5、反转:reverse()
list.reverse() #输出list
['d', 'c', 'b', 'a']
6、清空:clear()
list.clear()
#输出list
[]
7、插入:insert()
list.insert(2,'r')
#输出list
['a', 'b', 'r', 'c', 'd']
8、排序:sort()按照ascii码来进行排序
list.insert(4,'&&')
#输出list
['a', 'b', 'd', '&&', ] list.sort()
#输出list
['&&', 'a', 'b', 'd']
9、拼接两个列表:extend()
place=[1,2,3] list.extend(place)
#输出
[ 'a', 'b', 'd',1,2,3]
10、对列表进行切片处理
#列出所有的元素 list[::]
#列出最后一个元素 list[-1]
11、复制:copy()
list.copy() #输出 ['a','b', 'c', 'd', 1, 2, 3]
12,输出元素个数
len(list)
13,返回最大值
max(list)
14,返回最小值
min(list)
15,将元组转换成列表
list(tep)
元组
元组与列表类似,不同的是元组不能修改,元组使用小括号,列表使用方括号
1,创建空元组
tup1=()
2,访问元组:元组可以使用下标索引来访问元组中的值
tup1[0]
3,元组是不允许修改的,不允许删除的
4,元组的内置函数
len(tuo1) --计算元祖元素个数 max(tup1)--返回元组中元素最大值 min(tup1)--返回最小值 tuple(sep)--将列表转换为元组
string字符串
1,字符串格式输出对齐
>>> str = "Python stRING"
>>> print str.center(20) #生成20个字符长度,str排中间
Python stRING
>>> print str.ljust(20) #生成20个字符长度,str左对齐
Python stRING
>>> print str.rjust(20) #生成20个字符长度,str右对齐
Python stRING
2,大小写转换
>>> str = "Python stRING" >>> str.upper() #转大写 'PYTHON STRING' >>> str.lower() #转小写 'python string' >>> str.capitalize() #字符串首为大写,其余小写 'Python string' >>> str.swapcase() #大小写对换 'pYTHON STring' >>> str.title() #以分隔符为标记,首字符为大写,其余为小写 'Python String
3.字符串条件判断
>>> str = '01234'
>>> str.isalnum() #是否全是字母和数字,并至少有一个字符
True
>>> str.isdigit() #是否全是数字,并至少有一个字符
True
>>> str = 'string'
>>> str.isalnum() #是否全是字母和数字,并至少有一个字符
True
>>> str.isalpha() #是否全是字母,并至少有一个字符
True
>>> str.islower() #是否全是小写,当全是小写和数字一起时候,也判断为True
True
>>> str = "01234abcd"
>>> str.islower() #是否全是小写,当全是小写和数字一起时候,也判断为True
True
>>> str.isalnum() #是否全是字母和数字,并至少有一个字符
True
>>> str = ' '
>>> str.isspace() #是否全是空白字符,并至少有一个字符
True
>>> str = 'ABC'
>>> str.isupper() #是否全是大写,当全是大写和数字一起时候,也判断为True
True
>>> str = 'Aaa Bbb'
>>> str.istitle() #所有单词字首都是大写,标题
True
>>> str = 'string learn'
>>> str.startswith('str') #判断字符串以'str'开头
True
>>> str.endswith('arn') #判读字符串以'arn'结尾
True
4.字符串搜索定位与替换
>>> str='string lEARn'
>>> str.find('z') #查找字符串,没有则返回-1,有则返回查到到第一个匹配的索引
-1
>>> str.find('n') #返回查到到第一个匹配的索引
4
>>> str.rfind('n') #返回的索引是最后一次匹配的
11
>>> str.index('a') #如果没有匹配则报错
Traceback (most recent call last):
File "<input>", line 1, in <module>
ValueError: substring not found
>>> str.index("n") #同find类似,返回第一次匹配的索引值
4
>>> str.rindex("n") #返回最后一次匹配的索引值
11
>>> str.count('a') #字符串中匹配的次数
0
>>> str.count('n') #同上
2
>>> str.replace('EAR','ear') #匹配替换
'string learn'
>>> str.replace('n','N')
'striNg lEARN'
>>> str.replace('n','N',1)
'striNg lEARn'
>>> str.strip('n') #删除字符串首尾匹配的字符,通常用于默认删除回车符
'string lEAR'
>>> str.lstrip('n') #左匹配
'string lEARn'
>>> str.rstrip('n') #右匹配
'string lEAR'
>>> str = " tab"
>>> str.expandtabs() #把制表符转为空格
' tab'
>>> str.expandtabs(2) #指定空格数
' tab'
5.字符串编码与解码
>>> str = "字符串学习"
>>> str
'\xe5\xad\x97\xe7\xac\xa6\xe4\xb8\xb2\xe5\xad\xa6\xe4\xb9\xa0'
>>> str.decode('utf-8') #解码过程,将utf-8解码为unicode
u'\u5b57\u7b26\u4e32\u5b66\u4e60'
>>> str.decode("utf-8").encode('gbk') #编码过程,将unicode编码为gbk
'\xd7\xd6\xb7\xfb\xb4\xae\xd1\xa7\xcf\xb0'
>>> str.decode('utf-8').encode('utf-8') #将unicode编码为utf-8
'\xe5\xad\x97\xe7\xac\xa6\xe4\xb8\xb2\xe5\xad\xa6\xe4\xb9\xa0'
6.字符串分割变换
>> str = "Learn string"
>>> '-'.join(str)
'L-e-a-r-n- -s-t-r-i-n-g'
>>> li = ['Learn','string']
>>> '-'.join(li)
'Learn-string'
>>> str.split('n')
['Lear', ' stri', 'g']
>>> str.split('n',1)
['Lear', ' string']
>>> str.rsplit('n')
['Lear', ' stri', 'g']
>>> str.rsplit('n',1)
['Learn stri', 'g']
>>> str.splitlines()
['Learn string']
>>> str.partition('n')
('Lear', 'n', ' string')
>>> str.rpartition('n')
('Learn stri', 'n', 'g')
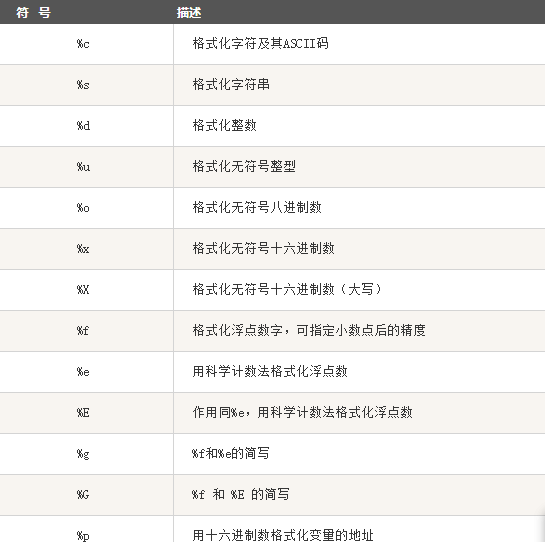
字符串格式化