HTTP协议
在搞清楚HTTP服务器之前我们必须搞清楚,HTTP是什么,这是一个请求协议.一个简简单单人为规定的协议.所以搭建一个http服务器只是一个遵守传输协议的服务器.其本质就是一个TCP服务器
那么现在我们显然可以仿造一下制作一个HTTP服务器.
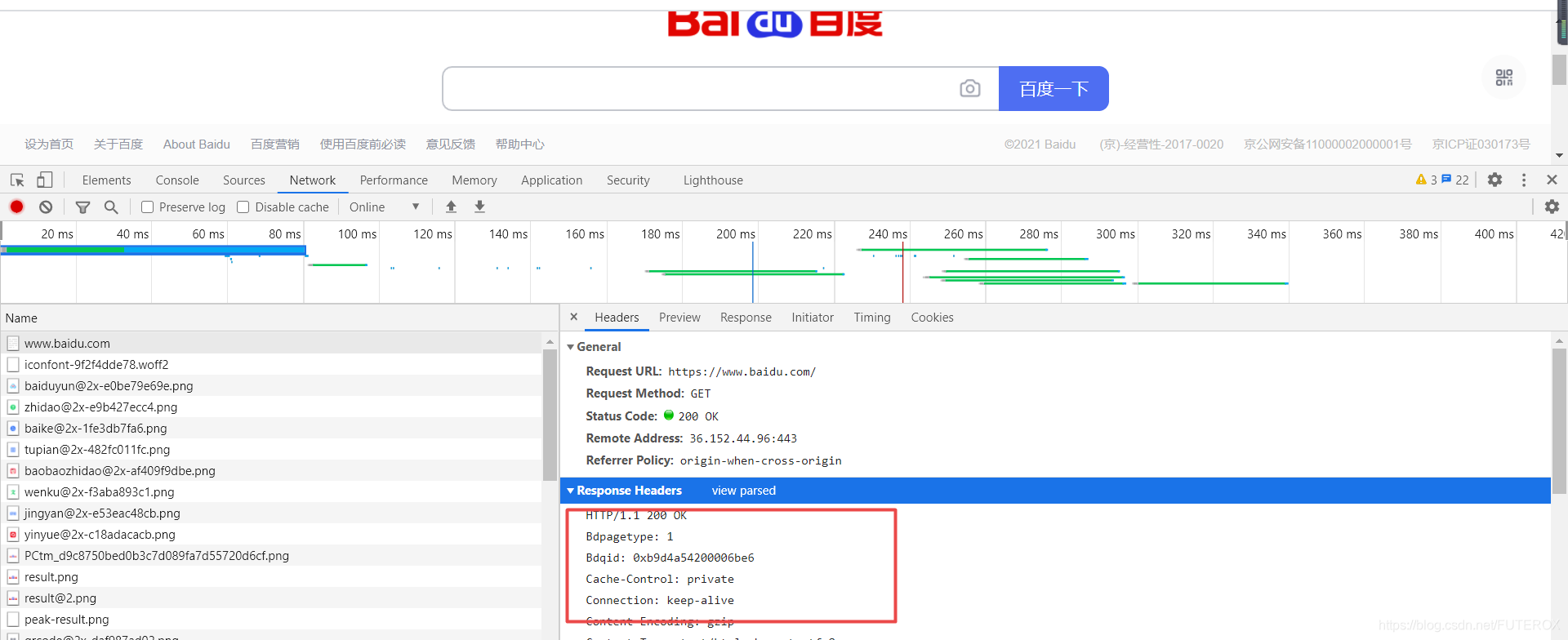
如何仿造其实很简单,打开任何一个网站我们发现除了网站内容被发送过来,还有一个响应头,这个响应头显然是给浏览器看的,除此之外还有一个请求头,玩过爬虫的都知道这个是个服务器看的,那么服务器会怎么对这个请求头进行处理呢.下面可以找到答案.
先看看这个最简单的案例,我们现在看到了这个返回,现在我们试着测试一波
看下面代码
s = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
id = socket.gethostbyname(socket.gethostname()).split(':')[0]
print(id)
s.bind((id,9090))
s.listen(128)
print("准备接收")
while True:
client= s.accept()[0]
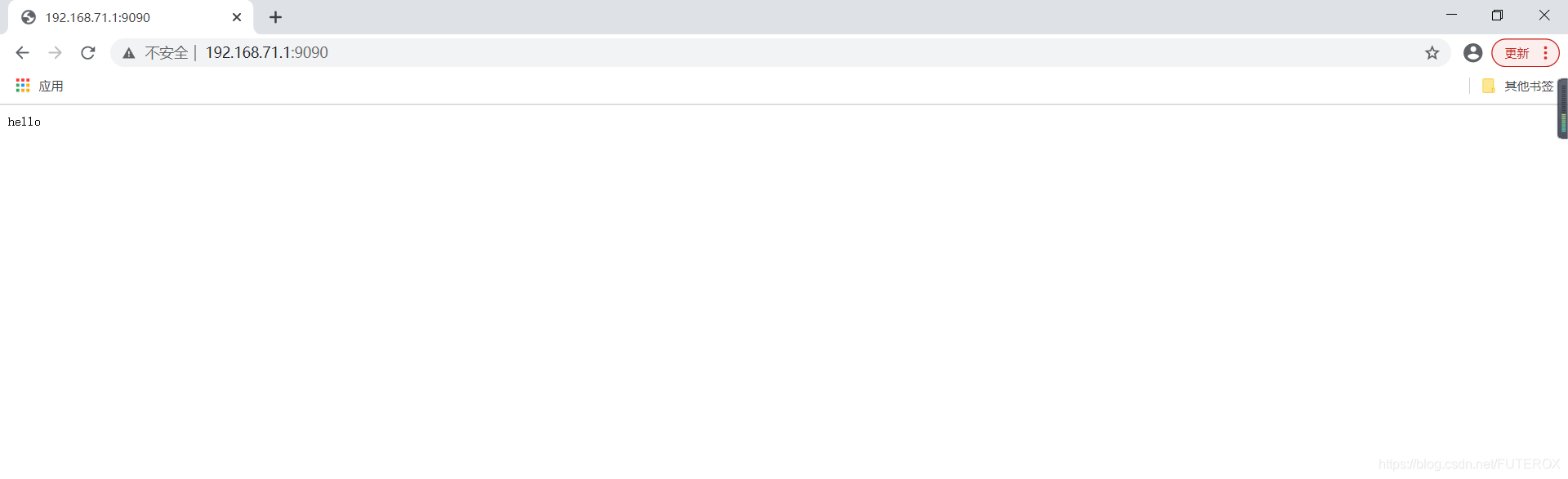
data = client.recv(1024).decode('utf-8')
client.send("HTTP/1.1 200 OK\n".encode("utf-8"))
client.send("\n".encode("utf-8"))
client.send("hello".encode('utf-8'))
print(data)
这里我发送了一个最基本的 HTTP/1.1 200 OK\n,记住每一个返回都要换行,最后换行结尾发送信息.

服务器逻辑处理
现在我们已经看到,此时浏览器其实会向我们的服务器先发送刚刚显示的一个请求头,
在这个请求头里面包含了一个最基本的请求路径(第一行,主页的话是没有的)
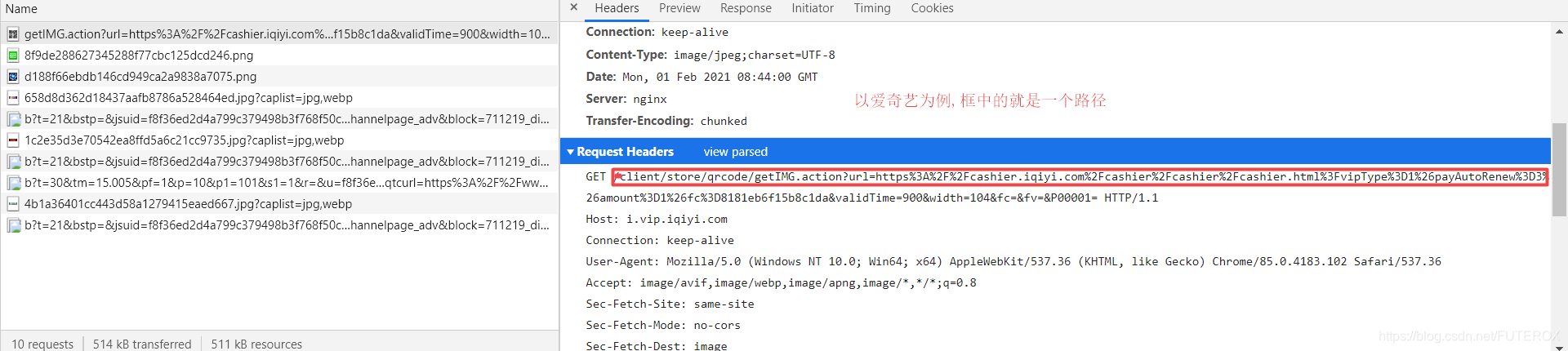
那么这里我们先做的可一事先对这个网站请求路径进行一个处理
具体做法显然也简单,我们只需要做一个简单的切割就好了.
HTTP服务器的页面传输
首先使用tcp传输文件我都会.那么我们一般情况下都是写好一个HTML页面文件的,那么我们要做的显然就是把这个文件的内容发过去.
那么这个时候就不得不说一下HTML,这个东西是专门给浏览器解析的
我们先来看一段待会测试使用的HTML代码
<!DOCTYPE html>
<html lang="en" >
<head>
<meta charset="UTF-8">
<title>测试访问页面</title>
<link rel="stylesheet" href="css/style.css">
</head>
<body>
<canvas></canvas>
<script src="js/index.js"></script>
</body>
</html>
这里有一个link标签,学过HTML的应该知道,除了这个标签以外还有iframe,媒体标签等,这些东西都会加载我们的资源,那么如何加载,其实就是此时浏览器读到这段代码时会向我们的服务器再发送一个请求,发送的内容里面就包含了文件的路径例如link标签里面写的css/style.css
它发过来的第一行就是
GET css/style.css HTTP/1.1
超简易的服务器实例
这里我们先弄到了一个页面
这个的话无所谓,自己搞一个也行
效果是:雪花飞舞

下面上代码:
import socket,os
class HTTP_sever(object):
def __init__(self,port,code_asll,Request_header_do=0):
'''this a simple http sever and this wirte by Mr H.L.Y'''
self.Socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
self.id = socket.gethostbyname(socket.gethostname()).split(":")[0]
self.Socket.bind((self.id,port))
self.Socket.listen(128)
self.code_asll =code_asll
self.respose = "HTTP/1.1 200 OK\n"+'Author:Huterox\n'+'Content-Type: text/html; charset=UTF-8\n\n'
self.Message = ""
if Request_header_do==0:
pass
else:
self.Request_header_do = HTTP_sever.Request_header_do
def Set_response(self,response):
self.respose = "HTTP/1.1 200 OK\n"
for key in response.keys():
response_line = key+':'+response[key]+'\n'
self.respose+=response_line
self.respose+='\n'
def get_info(self,info):
if os.path.isfile(info):
with open(info,'rb') as f:
Message =f.read()
f.close()
elif isinstance(info,str):
Message = info.encode(self.code_asll)
if Message:
return Message
def Identify_path(self,path):
if self.request:
req_path = self.request.splitlines()[0].split(" ")[1]
return True
else:
return False
def Accept(self):
Accept= self.Socket.accept()
self.client = Accept[0]
self.request=self.client.recv(1024).decode('utf-8')
self.client_IP_Port = Accept[1]
def Send_Http(self,Message="你好呀"):
self.client.send(self.respose.encode('utf-8'))
if Message =="你好呀":
self.client.send(Message.encode("utf-8"))
else:
self.client.send(Message)
def Request_header_do(self):
pass
if __name__=="__main__":
server = HTTP_sever(9090,"utf-8")
# server.Request_header_do()
print(server.id)
print("服务已开启,欢迎使用")
while True:
server.Accept()
# print(server.request)
Message = server.get_info("index.html")
server.Send_Http(Message)
print("接收到{}的访问".format(server.client_IP_Port[0]))
server.Accept()
# print(server.request)
if server.Identify_path("/css/style.css"):
Message=server.get_info("style.css")
server.Send_Http(Message)
server.Accept()
# print(server.request)
if server.Identify_path("/js/index.js"):
Message = server.get_info("index.js")
server.Send_Http(Message)
print("此次访问结束")
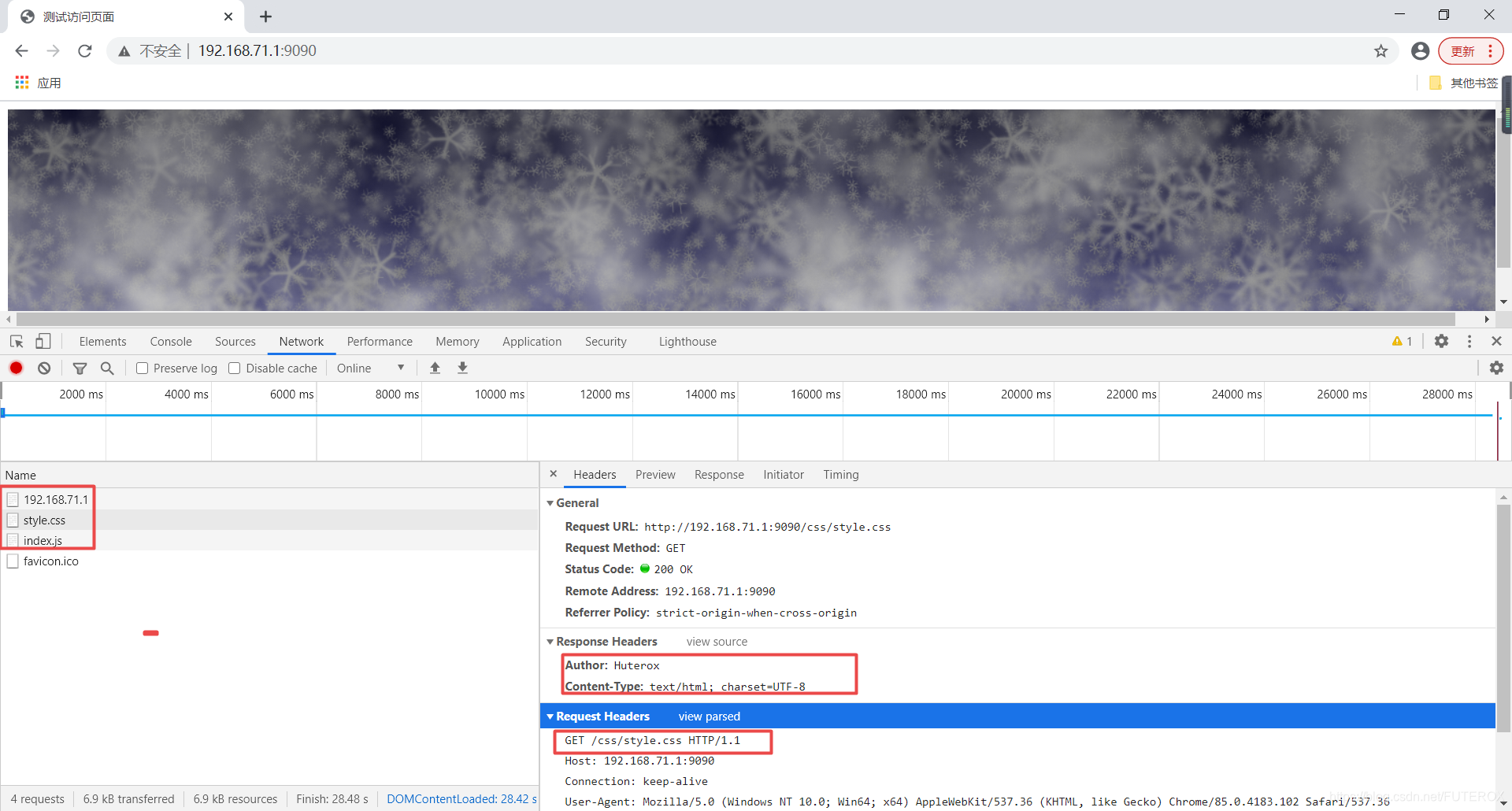
代码嘛很简单,我连注释都没写.所以这里还是有很多问题的,最突出的一点就是我们在做实现多个用户连接的时候应该使用进程加线程的方式实现对用户的一个简单的区分连接,使用池去管理线程,进程这样一来实现服务器的简单的并发性,和高可靠性.
浅谈请求库
现在通过这个示例我们其实可以发现,HTTP这个就是一个协议,只不过这个协议比较规则,服务器与浏览器都会遵守.那么显然这个时候我们完全可以基于tcp连接写一个爬虫的请求库.
只是在这里我们需要明白的是,我们需要对域名进行处理.
下面看一张图

这个就是一个简单的过程,此外我们还可以设置cookie,或者使用代理什么的
这些东西其实都很简单,但是要想把它做好的难度还是很大的.