个人认为编译原理对于一个程序员来说很重要,可能你认为编程的时候用的都是C++、C#、Java等高级语言,至于编译原理懂与不懂并无大碍。其实不然,所谓万变不离其宗,所有高级语言的诞生都是基于最根本的编译原理的。搞懂了编译原理,对于一个程序员的能力提升有着很大的帮助。因为它会让你对编程有更加深刻的理解,有助于你写出质量更高的代码。好废话不多说,切入正题!
本文主要说一下编译原理里的文法、正规式、有穷自动机和语法推导树。
文法
文法就是计算机语言的一个严格的规范,有点类似人类语言的语法。就像形容词修饰名词,副词修饰形容词跟动词类似,只不过计算机的文法的标准和规范更加的严格而已。
文法的表达式:G=(Vn,Vt,P,S) Vn是非终结符的集合,Vt是终结符的集合,P是推导式的一个集合,S是开始符。
文法中有三种符号和四种文法类型:
三种符号为:开始符——S;非终结符——A、B、C、AB等;终结符——a、b、c等。其实说白了开始符就是Start的缩写,非终结符就是大写字母或大写字母的组合(开始符S也是非终结符),终结符就是小写字母或小写字母的组合。
文法共分为四种,即0型文法——短语文法;1型文法——上下文有关文法;2型文法——上下文无关文法;3型文法——正规文法。
四个文法类的定义是逐渐增加限制的,即每一种正规文法都是上下文无关的,每一种上下文无关文法都是上下文有关的,而每一种上下文有关文法都是短语文法。称0型文法产生的语言为0型语言。上下文有关文法、上下文无关文法和正规文法产生的语言分别称为上下文有关语言、上下文无关语言和正规语言。
注意:除0型文法以外,每一种文法都必须符合上一种文法。
0型文法:
书中的定义:设G=(VN,VT,P,S),如果它的每个产生式α→β是这样一种结构:α∈( VN∪VT )*且至少含有一个非终结符,而β∈( VN∪VT )*,则G是一个0型文法。
通俗的解释:即产生式左边至少有一个大写字母,右边随意。
1型文法:
书中的定义:设G=(VN,VT,P,S),若P中的每一个产生式α→β均满足|β|≥|α| ,仅仅S→ε除外,则文法G是1型文法。
通俗的解释:即产生式右边的字母个数必须大于等于左边的字母个数。
2型文法:
书中的定义:设G=(VN,VT,P,S),若P中的每一个产生式α→β满足:α是一非终结符,β∈( VN∪VT )*则此文法称为2型文法。
通俗的解释:即产生式左边必须完全都是大写字母。
3型文法:
书中的定义:设G=(VN,VT,P,S),若P中的每一个产生式的形式都是A→aB或A→a,其中A和B都是非终结符,a是终结符,则G是3型文法。
通俗的解释:即所有产生式右边要么没有大写字母,如果有必须全部在小写字母右边或者全部在小写字母左边也就是要保持线性一致。
正规式
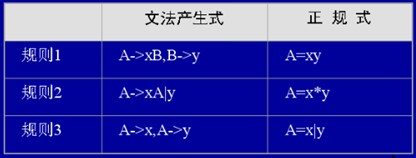
正规式是由正规文法转换而来,它们之间的转换规则共有三条:
规则1:正规文法(A—>xB,B->y ),正规式(A=xy)。这点很简单,用小学的数学知识就可以解决!如:A=xB,B=y,那么A=xy。
规则2:正规文法(A—>xA|y),正规式(A=x*y)。这是一个递归,它其实是——正规文法(A—>xA,A—>y),因为A—>xA,而右边的A又可以有A—>xA,所以就可以无限循环下去,最终还是要有结尾的,要不就没法表示了,所以有A=x*y,表明有无穷个x并以y结尾。
规则3:A—>x,A->y。那么A=x|y。这个就很简单了,不过多解释了。
其实上面说的那些话完全可以用下面一个表来代替,简单而又明了,哈哈!
有穷自动机跟语法推导树留到下一篇博客再为大家讲解吧!敬请期待!