目录

CSU 1683: Cryptographer’s Conundrum
UVA 11988 Broken Keyboard (Beiju Text)
CSU 1029 Palindrome(回文串)
题目:
Description
A palindrome is a symmetrical string, that is, a string read the same from left to right as from right to left. You are asked to write a program which, given a string, determines whether it is a palindrome or not.
Input
The first line contain a single integer T, indicates the number of test cases.
T lines follow, each line contain a string which you should judge. The length of the string is at most 1000.
Output
Print one line for each string, if it is a palindrome, output “YES”, else “NO”.
Sample Input
2abaabSample Output
YESNO判断是否为回文串
代码:
#include<iostream>
#include<string.h>
using namespace std;
int main()
{
int t;
cin >> t;
char c[1002];
cin.getline(c, 1002, '\n');
while (t--)
{
cin.getline(c,1002,'\n');
int l = strlen(c);
bool flag = true;
for (int i = 0; i + i < l; i++)
{
if (c[i] != c[l - 1 - i])
{
flag = false;
break;
}
}
if (flag)cout << "YES";
else cout << "NO";
cout << endl;
}
return 0;
}CSU 1041: 单词统计
题目:
给出要统计的单词及一个单词列表,统计这个单词在列表里出现的次数。
多组测试数据,每组数据第一行为一个单词,第二行为词汇列表的词汇个数n(0 < n < 1000),接下来n行每行一个仅由英文字母组成的单词。每个单词字母个数不超过20。
输出要统计的单词在词汇列表出现次数。
good
5
good
yes
NO
good
good
3代码:
#include<iostream>
#include<string>
using namespace std;
int main()
{
string s1, s2;
int n;
while (cin >> s1 >> n)
{
int ans = 0;
while (n--)
{
cin >> s2;
if (s1 == s2)ans++;
}
cout << ans << endl;
}
return 0;
}CSU 1067 1 VS 1
题目:
Description
Alice and Bob are playing the game SanguoSha 1VS1.If Alice take a card or use a card (it may be slash,missed,peach,duel,sabotage or theft and so on) or discard (sometimes he does not need to throw any card) we will write down an uppercase 'A', if Bob does this, of course, we will write down the letter 'B'. Tell me the length of the longest operation combo performed by either player.
Input
There are several test cases, each test case contains only a string composed of uppercaser 'A' and 'B'.The input will finish with the end of file.The length of the string is no more than 1000.
Output
For each the case, output an integer indicate for the length.
Sample Input
AAABBAAAAA
AABBBBAA
AAAAAAAASample Output
5
4
8
求最长的连续相同字母有多长
代码:
#include<iostream>
#include<string.h>
#include<stdio.h>
using namespace std;
int main()
{
string s;
while (cin>>s)
{
int l = s.length();
int max = 0;
int a = 0;
int i = 0;
while (i < l)
{
while (i < l && s[i] == 'A')
{
a++;
i++;
}
if (a>max)max = a;
a = 0;
while (i < l && s[i] == 'B')
{
a++;
i++;
}
if (a>max)max = a;
a = 0;
}
printf("%d\n",max);
}
return 0;
}CSU 1100: 一二三
题目:
Description
你弟弟刚刚学会写英语的一(one)、二(two)和三(three)。他在纸上写了好些一二三,可惜有些字母写错了。已知每个单词最多有一个字母写错了(单词长度肯定不会错),你能认出他写的啥吗?
Input
第一行为单词的个数(不超过10)。以下每行为一个单词,单词长度正确,且最多有一个字母写错。所有字母都是小写的。
Output
对于每组测试数据,输出一行,即该单词的阿拉伯数字。输入保证只有一种理解方式。
Sample Input
3
owe
too
theee
Sample Output
1
2
3有个类似的题目:https://blog.csdn.net/nameofcsdn/article/details/52014149 POJ 1035 Spell checker(字典),不过要复杂多了
这个题目其实也差不多,只不过因为字典是固定的,而且只有3个单词,所以可以用特殊的方法来写。
代码:
#include<iostream>
#include<string>
using namespace std;
int main()
{
string s;
int n;
cin >> n;
for(int i = 0; i < n; i++)
{
cin >> s;
if(s.length() == 5)cout << 3 ;
else if (s[0] == 'o')
{
if(s[1] == 'w'&& s[2] == 'o')cout << 2;
elsecout << 1;
}
else
{
if(s[1] == 'n'&& s[2] == 'e')cout << 1;
else cout << 2;
}
cout << endl;
}
return 0;
}CSU 1158 取字符串
题目:
Description
有个长度为1000000以内的字符串C,提供整数a,b,d,e,计算ans=a*b%d,然后取C从第e(e的取值从0开始)号位置的字符开始长度为ans的那子串并输出。(1<=a,b<=5000)数据保证子串不超过C的字符串范围。
Input
有多组测试数据,对于每组数据,第一行为4个整数,a,b,d,e,第二行为给定的字符串C。
Output
对于每组测试数据,输出所求的子字符串。
Sample Input
3 4 5 1
abcdefghijk
Sample Output
bc
代码:
#include<iostream>
#include<string.h>
using namespace std;
int main()
{
char c[1000000];
int a, b, d, e;
while (cin >> a >> b >> d >> e)
{
cin.getline(c, 1000000, '\n');
int ans = a*b % d;
cin.getline(c, 1000000, '\n');
for (int i = e; i < ans + e; i++)printf("%c",c[i]);
cout << endl;
}
return 0;
}CSU 1178 BMW
题目:
Description
做广告啦。
感谢大家参加CSU_BMW正式组队纪念赛,这个BMW来自动画片《机器人瓦力》(《机器人总动员》||《Wall-E》),三个可爱的机器人Wall-E,M-O,Burn-E。
没看过的朋友~推荐一下。
这道题的任务很简单,给一个字符串,从中拿出一些字符,问最多能组成多少个bmw。每个字符只计一次。
Input
每组数据一行长度不超过1,000,000的字符串。
Output
每组数据对应输出一行一个数字,表示从这个字符串中拿出一些字符,最多能组成多少个bmw。每个字符只计一次。
Sample Input
bmw
mwBm
mwBmwWbbSample Output
1
1
2
代码:
#include<iostream>
using namespace std;
int main()
{
string s;
while(cin>>s)
{
int b=0,m=0,w=0;
int l=s.length();
for(int i=0;i<l;i++)
{
if (s[i]=='b'||s[i]=='B')b++;
else if (s[i]=='m'||s[i]=='M')m++;
else if (s[i]=='w'||s[i]=='W')w++;
}
int r=b;
if(m<r)r=m;
if(w<r)r=w;
printf("%d\n",r);
}
return 0;
}CSU 1214 三个数字
题目:
Description
1、2、3三个数字组成的序列,要求把所有的2放在前面,所有的3放在后面,输出结果。
Input
每组数据1、2、3组成的一行字符串,长度不超过10 ^ 5。
Output
把原串的2放在前面,3放在后面,输出。
Sample Input
12321 223311
Sample Output
22113 221133
计数
代码:
#include<iostream>
#include<string.h>
#include<stdio.h>
using namespace std;
int main()
{
string s;
while(cin>>s)
{
int a=0,b=0;
int len=s.length();
for(int i=0;i<len;i++)
{
if(s[i]=='1')a++;
else if(s[i]=='2')b++;
}
for(int i=0;i<b;i++)printf("%d",2);
for(int i=0;i<a;i++)printf("%d",1);
for(int i=0;i<len-a-b;i++)printf("%d",3);
cout<<endl;
}
return 0;
}
CSU 1260: 回文串问题
题目:
Description
“回文串”是一个正读和反读都一样的字符串,字符串由数字和小写字母组成,比如“level”或者“abcdcba”等等就是回文串。请写一个程序判断读入的字符串是否是“回文”。
Input
输入包含多个测试实例,每一行对应一个字符串,串长最多100字母。
Output
对每个字符串,输出它是第几个,如第一个输出为"case1:";如果一个字符串是回文串,则输出"yes",否则输出"no",在yes/no之前用一个空格。
Sample Input
level abcde noon haha
Sample Output
case1: yes case2: no case3: yes case4: no
代码:
#include<iostream>
#include<string.h>
using namespace std;
int main()
{
int ca = 0, i, j;
char ch[101];
while (cin >> ch)
{
for (i = 0, j = strlen(ch) - 1; i <= j; i++, j--)if (ch[i] != ch[j])break;
cout << "case" << ++ca << ": ";
if (i > j)cout << "yes\n";
else cout << "no\n";
}
return 0;
}CSU 1505: 酷酷的单词
题目:
Description
输入一些仅由小写字母组成的单词。你的任务是统计有多少个单词是“酷”的,即每种字母出现的次数都不同。
比如ada是酷的,因为a出现2次,d出现1次,而1和2不同。再比如,banana也是酷的,因为a出现3次,n出现2次,b出现1次。但是,bbacccd不是酷的,因为a和d出现的次数相同(均为1次)。
Input
输入包含不超过30组数据。每组数据第一行为单词个数n (1<=n<=10000)。以下n行各包含一个单词,字母个数为1~30。
Output
对于每组数据,输出测试点编号和酷单词的个数。
Sample Input
2 ada bbacccd 2 illness a
Sample Output
Case 1: 1 Case 2: 0
代码:
#include<iostream>
#include<string.h>
using namespace std;
int main()
{
int ca = 0, n, num[26];
char s[10005];
while (cin >> n)
{
int ans = 0;
while (n--)
{
cin >> s;
int len = strlen(s);
if (len == 1)continue;
for (int i = 0; i < 26; i++)num[i] = 0;
for (int i = 0; i < len; i++)num[s[i] - 'a']++;
bool flag = true;
for (int i = 0; i < 26; i++)
{
if (num[i] == 0)continue;
for (int j = 0; j < 26; j++)if (i!=j && num[i] == num[j])flag = false;
}
ans += flag;
}
printf("Case %d: %d\n", ++ca, ans);
}
return 0;
}CSU 1573: 最多的数字
题目:
Description
数字的每一位都由0~9组成,现在给出一个数,问你它所有位数中使用哪个数字最多。
Input
输入包含多个测试实例,每行为一个数字(所有数据小于10的1000次方)。
Output
每一行对应一个要求的答案。(答案为0~9之间的一个数,如果有一样多的情况,输出最小的数字)
Sample Input
1234567891 1122 1111111111111111111111111111111111111111111111111111111
Sample Output
1 1 1
代码:
#include<iostream>
#include<string.h>
using namespace std;
int main()
{
int num[10];
char s[1005];
while (cin >> s)
{
int len = strlen(s);
for (int i = 0; i < 10; i++)num[i] = 0;
for (int i = 0; i < len; i++)num[s[i] - '0']++;
int max = 0;
for (int i = 0; i < 10; i++)if (max < num[i])max = num[i];
for (int i = 0; i < 10; i++)if (max == num[i])
{
cout << i << endl;
break;
}
}
return 0;
}CSU 1590: 我们都爱alpc
题目:
Description
hc是alpc的一员,他最喜欢的单词就是alpc了。(如果你还不知道alpc是什么意思,可以去问hc,乐于助人的hc一定会给你解释的)。现在hc有若干字符串,每个字符串只包含小写字母且不含符号、空格等。hc想知道每一个字符串中包含了多少个“alpc”的单词。
Input
第一行输入一个T(T<=20),代表共有T个字符串。
接下来的T行,每行会有一个合法的字符串,字符串的长度小于100。
Output
输出T行,每行输出一个整数代表这个字符串中有多少个“alpc”。
Sample Input
2 aalplllalpcuidjjsalpcalalalpcpcpc xcvbnnmfghjtyuifghapcghaplcalpcalpc
Sample Output
3 2
代码:
#include<iostream>
#include<string.h>
using namespace std;
int main()
{
int t;
cin >> t;
char s[105];
while (t--)
{
cin >> s;
int ans = 0;
for (int i = 0; i < strlen(s) - 3; i++)
if (s[i] == 'a'&&s[i + 1] == 'l'&&s[i + 2] == 'p'&&s[i + 3] == 'c')ans++;
cout << ans << endl;
}
return 0;
}CSU 1610: Binary Subtraction
题目:
Description
Zuosige always has bad luck. Recently, he is in hospital because of pneumonia. While he is taking his injection, he feels extremely bored. However, clever Zuosige comes up with a new game.
Zuosige writes two binary number on a paper, which are labelled as A and B. It is guaranteed that A is greater than B and A xor B = 2n+1-1 (n is the length of A), where xor means bitwise exclusive-or. Now he wants to know the value of A - B in binary.
Input
The first line contains one integer T, indicating the number of test cases.
In one test case, there are two lines.
In the first line, there are two integers n, m (0<=m < n/2, 1<=n<=1000000), indicating the length of the numbers and the number of 1s in B.
In the second line, there m integers indicating the positions where B is 1. Positions starting from 1, which is the lowest bit. It is guaranteed that A is greater than B.
Output
For each test case, output a line indicating the answer in binary without leading zero.
Sample Input
2 9 3 2 5 6 8 5 1 2 3 5 6
Sample Output
110011011 10010001
代码:
#include<iostream>
using namespace std;
char ans[1000001];
int main()
{
int t, n, m, a;
scanf("%d", &t);
while (t--)
{
scanf("%d%d", &n, &m);
for (int i = 0; i < n; i++)ans[i] = '1';
while (m--)
{
scanf("%d", &a);
ans[a] = '0';
}
int key = n - 1;
while (ans[key] == '0')key--;
for (int i = key; i >= 0; i--)printf("%c", ans[i]);
cout << endl;
}
return 0;
}CSU 1683: Cryptographer’s Conundrum
题目:

Input

Output
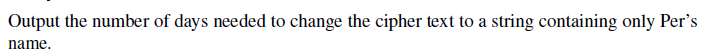
Sample Input
SECRET
Sample Output
4
代码:
#include<iostream>
using namespace std;
int main()
{
char a, b, c;
int ans = 0;
while (cin >> a >> b >> c)ans += (a != 'P') + (b != 'E') + (c != 'R');
cout << ans;
return 0;
}CSU 1898: 复盘拉火车
题目:
Description
小GJ和小XS没事做用扑克牌玩起了小时候的拉火车游戏。规则如下,GJ和XS交替依次把手中的牌放到桌面上,由于GJ年长,所以他总是先放。桌面上会构成一个新的序列,当这个序列中新放入的点数与以前存在的某个点数重复的时候,这两张重复的牌和中间的牌就依次全部放回所放牌一方的序列尾部。 例如桌面上有牌A 10 2 3 5此时GJ放下一张2则桌面上剩下A 10而2 3 5 2这个序列放到GJ原本手中牌序列的尾部。
Input
有T(T<=20)组数据。 每组第一行给出GJ目前手中牌的数量N1(N1<=100)和这个手牌序列的点数各是多少 (点数可能为 A 2 3 4 5 6 7 8 9 10 J Q K) 第二行给出XS目前手中牌的数量N2(N2<=100)和这个手牌序列的点数各是多少 第三行给出一个数字K,问进行K(K<=2xN1 且 K<=2xN2)次放牌后,桌面上的序列和两个人的手牌序列是怎样的。
Output
每组数据给出3行输出,桌面上的扑克序列,小GJ的手牌序列和小XS的手牌序列。具体格式见样例。 每组数据后加空行间隔。
Sample Input
2 10 A 2 3 4 5 6 7 8 9 10 5 2 2 3 4 5 5 5 2 2 2 2 5 5 A 3 4 J K 10
Sample Output
Deck: A 2 3 GJ: 4 5 6 7 8 9 10 2 2 XS: 3 4 5 Deck: 3 J 5 K GJ: 2 A 2 2 4 2 XS:
可以用队列也可以用数组,数组的话大小300就够了
代码:
#include<iostream>
using namespace std;
char c0[500],c1[500],c2[500],c;
int low0,high0,low1,high1,low2,high2;
void out()
{
cout<<"Deck:";
for(int i=low0;i<=high0;i++)
{
cout<<" "<<c0[i];
if(c0[i]=='1')cout<<0;
}
cout<<"\nGJ:";
for(int i=low1;i<=high1;i++)
{
cout<<" "<<c1[i];
if(c1[i]=='1')cout<<0;
}
cout<<"\nXS:";
for(int i=low2;i<=high2;i++)
{
cout<<" "<<c2[i];
if(c2[i]=='1')cout<<0;
}
cout<<endl;
}
void f(int kkk)
{
if(kkk%2)
{
c0[++high0]=c1[low1++];
for(int i=low0;i<high0;i++)if(c0[i]==c0[high0])
{
int temp=i-1;
for(int j=i;j<=high0;j++)c1[++high1]=c0[j];
high0=temp;
}
}
else
{
c0[++high0]=c2[low2++];
for(int i=low0;i<high0;i++)if(c0[i]==c0[high0])
{
int temp=i-1;
for(int j=i;j<=high0;j++)c2[++high2]=c0[j];
high0=temp;
}
}
}
int main()
{
int t,n1,n2;
cin>>t;
while(t--)
{
cin>>n1;
for(int i=0;i<n1;i++)
{
cin>>c1[i];
if(c1[i]=='1')cin>>c;
}
cin>>n2;
for(int i=0;i<n2;i++)
{
cin>>c2[i];
if(c2[i]=='1')cin>>c;
}
low0=low1=low2=0;
high0=-1,high1=n1-1,high2=n2-1;
int k,kk;
cin>>k;
kk=k;
while(k--)f(kk-k);
out();
cout<<endl;
}
return 0;
}CSU 2050: 英文单词
题目:
Description
编写程序,读入一行文本,文本是一个长度不超过255的英文句子,单词之间有一个或一个以上的空格,输出:
①统计单词的个数;
②一个对应的英文句子,其中原句中的所有小写字母均转换成大写字母,大写字母转换成小写字母;
③删除所有空格符后对应的句子。
Input
只有一行,就是一个英文句子
Output
有三行,第一行单词的个数,第二行,转换了大小写的英文句子,第三行删除空格的句子。
Sample Input
Who are you?
Sample Output
3 wHO ARE YOU? Whoareyou?
代码:
#include<iostream>
using namespace std;
int main()
{
char s[256];
cin.get(s, 256);
int r = 0;
for (int i = 0; s[i]; i++)if (s[i] == ' '&&(s[i+1]>='a'&&s[i+1]<='z'||s[i+1]>='A'&&s[i+1]<='Z'))r++;
cout << r + (s[0]!=' ') << endl;
for (int i = 0; s[i]; i++)
{
if (s[i] >= 'a' && s[i] <= 'z')cout << char(s[i] - 32);
else if (s[i] >= 'A' && s[i] <= 'Z')cout << char(s[i] + 32);
else cout << s[i];
}
cout << endl;
for (int i = 0; s[i]; i++)if (s[i] != ' ')cout << s[i];
cout << endl;
return 0;
}HDU 5842 Lweb and String
题目:


这个题目是说,任选一个从26个字母的集合到整数的集合的映射,然后求每一行的字符数组对应的数列的最长递增子序列的长度的最大值。
如果你以为我要说的是动态规划,那你就傻了。
因为映射可以任选,所以这个题目的意思是,输入一个字符串(只有小写字母),输出它有多少个不同的小写字母。
对,没错,就是这样,没了。
代码:
#include<iostream>
#include<cstring>
using namespace std;
char c[100001];
int l[26];
int main()
{
int t;
scanf("%d", &t);
for (int cas = 1; cas <= t; cas++)
{
scanf("%s", c);
int len = strlen(c);
for (int i = 0; i < 26; i++)l[i] = 0;
for (int i = 0; i < len; i++)l[c[i] - 'a']++;
int sum = 0;
for (int i = 0; i < 26; i++)sum += (l[i]>0);
printf("Case #%d: %d\n", cas, sum);
}
return 0;
}
POJ 1035 Spell checker(字典)
题目:
Description
You, as a member of a development team for a new spell checking program, are to write a module that will check the correctness of given words using a known dictionary of all correct words in all their forms.
If the word is absent in the dictionary then it can be replaced by correct words (from the dictionary) that can be obtained by one of the following operations:
?deleting of one letter from the word;
?replacing of one letter in the word with an arbitrary letter;
?inserting of one arbitrary letter into the word.
Your task is to write the program that will find all possible replacements from the dictionary for every given word.
Input
The first part of the input file contains all words from the dictionary. Each word occupies its own line. This part is finished by the single character '#' on a separate line. All words are different. There will be at most 10000 words in the dictionary.
The next part of the file contains all words that are to be checked. Each word occupies its own line. This part is also finished by the single character '#' on a separate line. There will be at most 50 words that are to be checked.
All words in the input file (words from the dictionary and words to be checked) consist only of small alphabetic characters and each one contains 15 characters at most.
Output
Write to the output file exactly one line for every checked word in the order of their appearance in the second part of the input file. If the word is correct (i.e. it exists in the dictionary) write the message: " is correct". If the word is not correct then write this word first, then write the character ':' (colon), and after a single space write all its possible replacements, separated by spaces. The replacements should be written in the order of their appearance in the dictionary (in the first part of the input file). If there are no replacements for this word then the line feed should immediately follow the colon.
Sample Input
i is has have be my more contest me too if award # me aware m contest hav oo or i fi mre #
Sample Output
me is correct aware: award m: i my me contest is correct hav: has have oo: too or: i is correct fi: i mre: more me
这个题目就是把10000个字符串和50个字符串一一比较。
因为在不是correct的情况下,比较得到一个相似的就直接输出,不用保存下来,所以在这之前先要判断到底是不是correct的情况。
直接从头到尾遍历一遍看有没有相同的字符串就可以了。这个过程完全不会影响算法的复杂度。
然后在比较2个字符串是不是相似(只隔了一个字母)的时候,先统计长度。
因为在循环里面是必须用到长度的,而且根据长度的情况分4类,分别处理,是非常方便的。
如果把字符串s2去掉任意一个字母,再和s1去比较,因为去掉的字母的位置是任意的,所以会有大量的重复工作。
虽然说一个单词最多只有15个字母,但是字符串去掉一个字母也需要时间,所以这样的方法时间代价还是比较高的。
所以我用的是一个个字符的比较。
其中有个很容易错的地方
if (l1 - l2 == -1)
{
for (int i = 0, j = 0; i < l1; i++, j++)
{
if (s1[i] != s2[j])
{
i--;
if ((j - i)>1)return false;
}
}
return true;
}第7行是 i-- 而不是 j++,否则的话,就会误判 "abcdefg" 和 "abchiefg" 为相似字符串,因为会跳过d和i的比较。
代码:
#include<iostream>
#include<string>
using namespace std;
bool ok(string s1, string s2)
{
int l1 = s1.length();
int l2 = s2.length();
if (l1 - l2 == -1)
{
for (int i = 0, j = 0; i < l1; i++, j++)
{
if (s1[i] != s2[j])
{
i--;
if ((j - i)>1)return false;
}
}
return true;
}
if (l1 - l2 == 0)
{
int t = 0;
for (int i = 0, j = 0; i < l1; i++, j++)
{
if (s1[i] != s2[j])
{
if (t)return false;
t++;
}
}
return true;
}
if (l1 - l2 == 1)
{
for (int i = 0, j = 0; j < l2; i++, j++)
{
if (s1[i] != s2[j])
{
j--;
if ((i - j)>1)return false;
}
}
return true;
}
return false;
}
int main()
{
string s1[10001];
string s2[51];
int l1, l2;
for (l1 = 0;; l1++)
{
getline(cin, s1[l1]);
if (s1[l1] == "#")break;
}
for (l2 = 0;; l2++)
{
getline(cin, s2[l2]);
if (s2[l2] == "#")break;
}
for (int i = 0; i < 51; i++)
{
if (s2[i] == "#")break;
bool flag = false;
for (int j = 0; j < 10000; j++)
{
if (s1[j] == "#")break;
if (s1[j] == s2[i])
{
flag = true;
break;
}
}
cout << s2[i];
if (flag)cout << " is correct";
else
{
cout << ":";
for (int j = 0; j < 10000; j++)
{
if (s1[j] == "#")break;
if (ok(s1[j], s2[i]))cout << " " << s1[j];
}
}
cout << endl;
}
return 0;
}UVA 11988 Broken Keyboard (Beiju Text)
题目:

首先,括号对前面的字符串的输出是无法分割的。
也就是说,括号右边的字符只能输出到前面这个字符串的2边。
这个和算术表达式里面的小括号是很像的,小括号是封闭的,括号外面的内容无法影响里面的内容。
所以,这个题目可以模拟算术表达式,找到唯一的核心分割点,比如a*b-c+d中的+,又比如a*b-c*d中的-
找到之后,递归即可。
代码:
#include<iostream>
#include<string>
#include<string.h>
#include<stack>
using namespace std;
stack<int>s;
char c[100005];
void f(int high)
{
if (s.empty())
{
for (int i = 0; i <= high; i++)printf("%c", c[i]);
return;
}
int key = s.top();
s.pop();
if (c[key] == ']')
{
f(key - 1);
for (int i = key + 1; i <= high; i++)printf("%c", c[i]);
}
else
{
for (int i = key + 1; i <= high; i++)printf("%c", c[i]);
f(key - 1);
}
}
int main()
{
string str;
int l;
while (scanf("%s", c) != EOF)
{
l = strlen(c);
while (!s.empty())s.pop();
for (int i = 0; i < l; i++)if (c[i] == '[' || c[i] == ']')s.push(i);
f(l-1);
cout << endl;
}
return 0;
}