Take a NAP: Non-Autoregressive Prediction for Pedestrian Trajectories
Take a NAP:行人轨迹的非自回归预测
作者:Hao Xue, Du. Q. Huynh, Mark Reynolds
论文地址:rXiv:2004.09760v1 [cs.CV]
发表时间: 21 Apr 2020
摘要
行人轨迹预测是一项具有挑战性的任务,因为需要解决人类运动行为的三个属性,即来自其他行人的社会影响,场景约束以及预测的多模式(多路线)性质。尽管现有方法已经探索了这些关键属性,但是这些方法的预测过程是自回归的。这意味着他们只能顺序预测未来的位置。在本文中,我们提出了NAP,一种用于轨迹预测的非自回归方法。我们的方法包括专门设计的特征编码器和潜在变量生成器,以处理上述三个属性。它还具有与时间无关的上下文生成器和用于非自回归预测的特定于时间的上下文生成器。通过将NAP与几种最新方法进行比较的大量实验,我们表明NAP具有最先进的轨迹预测性能。
1 引言
行人轨迹预测是诸如社交机器人和自动驾驶汽车等一系列应用中的重要组成部分,并且在理解人类运动行为方面起着关键作用。
由于行人轨迹预测的三个关键属性,此任务并不容易:
(i)社会互动:人们并不总是在公共场所独自行走。行人经常与他人进行社交互动,以避免发生碰撞,与朋友同行或与陌生人保持一定距离。
(ii)环境场景限制:除了社交互动之外,行人的路线还需要遵守场景限制,例如障碍物和建筑物布局;
(iii)未来预测的多模式性质:人们可以遵循不同的路线,只要这些路线在社会和环境上都是可以接受的。例如,一个人可以选择向右转或向左转以绕过障碍物。
最近,研究人员在将这些特性纳入轨迹预测过程中取得了进展。例如,Social LSTM模型[Alahi et al,2016]是一种可以捕获每个行人周围的社区影响力信息的方法之一。基于生成模型GAN [Goodfellow等,2014],Gupta等提出了SGAN模型。 [Gupta et al, 2018]可以在预测过程中处理多模式,同时还可以捕获场景中其他行人的社会影响。为了处理场景约束,通常使用卷积神经网络(CNN)来提取轨迹预测网络中的场景信息,例如SS-LSTM [Xue et al,2018],SoPhie [Sadeghian et al,2019],和SocialBiGA T [Kosaraju等人,2019]。
而其他方法如[Su et al,2017; V emula等,2018; Hasan等人,2018; Zou等,2018; Xue等,2019;李,2019; Zhang等人,2019]忽略了一个或两个上述关键特性,
SoPhie [Sadeghian等人,2019],
Liang et al. [Liang等人,2019]和
Social-BiGA T [Kosaraju等人,2019]是三篇典型的论文,其中考虑了这三种特性。
但是,这些方法会反复预测未来的位置。使用自回归来生成轨迹预测有两个主要限制:
(i)自回归预测过程以递归方式工作,因此从先前时间步累积的预测误差将传递给下一时间步的预测;
(ii)该过程不能并行化,即,即使可能只希望生成行人的最终目的地而不是整个轨迹的兴趣,也必须顺序生成预测。
为了克服上述局限性,并受到非自回归解码器在机器翻译等其他领域的应用的启发[Gu et al,2018; Guo et al。,2019]和时间序列预测[Wen et al。,2017],我们提出了一种新颖的轨迹预测方法,该方法可以非自回归地预测未来轨迹。我们将方法命名为NAP(非自回归预测的缩写)。
我们的研究贡献包括三个方面:
(i)据我们所知,我们是第一个探索非自回归轨迹预测的人。
NAP的网络体系结构包括可训练的上下文生成器,以确保上下文向量可用于非自回归解码器以预测良好的质量预测。通过广泛的实验和消融研究证明了NAP的最新性能。
(ii)NAP通过特殊设计的特征编码器来处理社交和场景影响。通过LSTM传播的社会图特征捕获了社会影响;场景影响力由CNN建模。这些编码器的有效性从NAP的性能得到了证实。
(iii)与文献中先前的工作不同,NAP通过训练潜变量生成器以学习每个行人轨迹的采样分布的潜变量来解决多模态预测。该生成器在多模态预测中显示出NAP的最高性能。
2 Background
2.1 Problem Definition(问题定义)
行人轨迹预测的定义是,根据给定的观察轨迹预测人的未来轨迹。
我们假设已经以坐标的时间序列格式获得了轨迹(即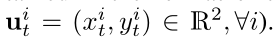 )。
)。
观测轨迹和预测轨迹的长度由To和Tp表示。
因此,考虑到观察到的轨迹 Xi = {ui t | t = 1,···,To},我们的目标是生成预测ˆYi =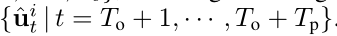
2.2 Autoregressive and Non-Autoregressive
Predictions(自回归和非自回归预测)
在数学上,为了从给定的观测轨迹 生成预测轨迹
生成预测轨迹 ,自回归预测器的参数为θ的条件概
,自回归预测器的参数为θ的条件概
率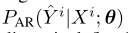 定义为:
定义为:
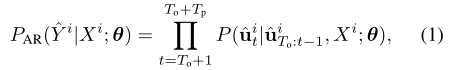
其中生成时间步长t的预测需要预测阶段中所有先前的时间步长的预测。此递归预测过程无法并行化。
与自回归预测过程不同的是,将所有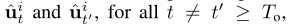
分别处理为独立,非自回归预测中上述条件概率变为
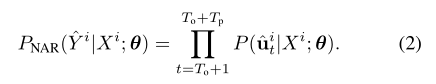
与基于自回归的预测相比,在时间步t的预测取决于在时间步t-1的信息,基于非自回归的预测变量不需要顺序生成预测。但是,在基于非自回归的方法中删除此顺序依赖性意味着在预测模型中时间意识能力受到损害,从而导致较差的预测性能。为了补偿失去时间意识的能力,我们设计了上下文生成器(context generators)(在3.2节中有详细介绍),这些生成器在训练轨迹上进行了训练。这允许在预测阶段的测试阶段从观察到的轨迹生成上下文向量。由于可以在预测阶段开始之前计算这些上下文向量,因此可以并行预测不同时间步长的预测。
3 3 Proposed Method(方法)
我们提出的NAP包括四个主要部分(图1):
(i)特征编码器,用于编码输入信息,例如观察到的轨迹和场景图像(第3.1节);
(ii)上下文生成器,以产生用于预测的上下文向量(第3.2节);
(iii)多模式潜变量生成器(第3.3节);
(iv)用于预测未来轨迹的非自回归解码器(第3.4节)。以下各小节将介绍这些部分的详细信息。
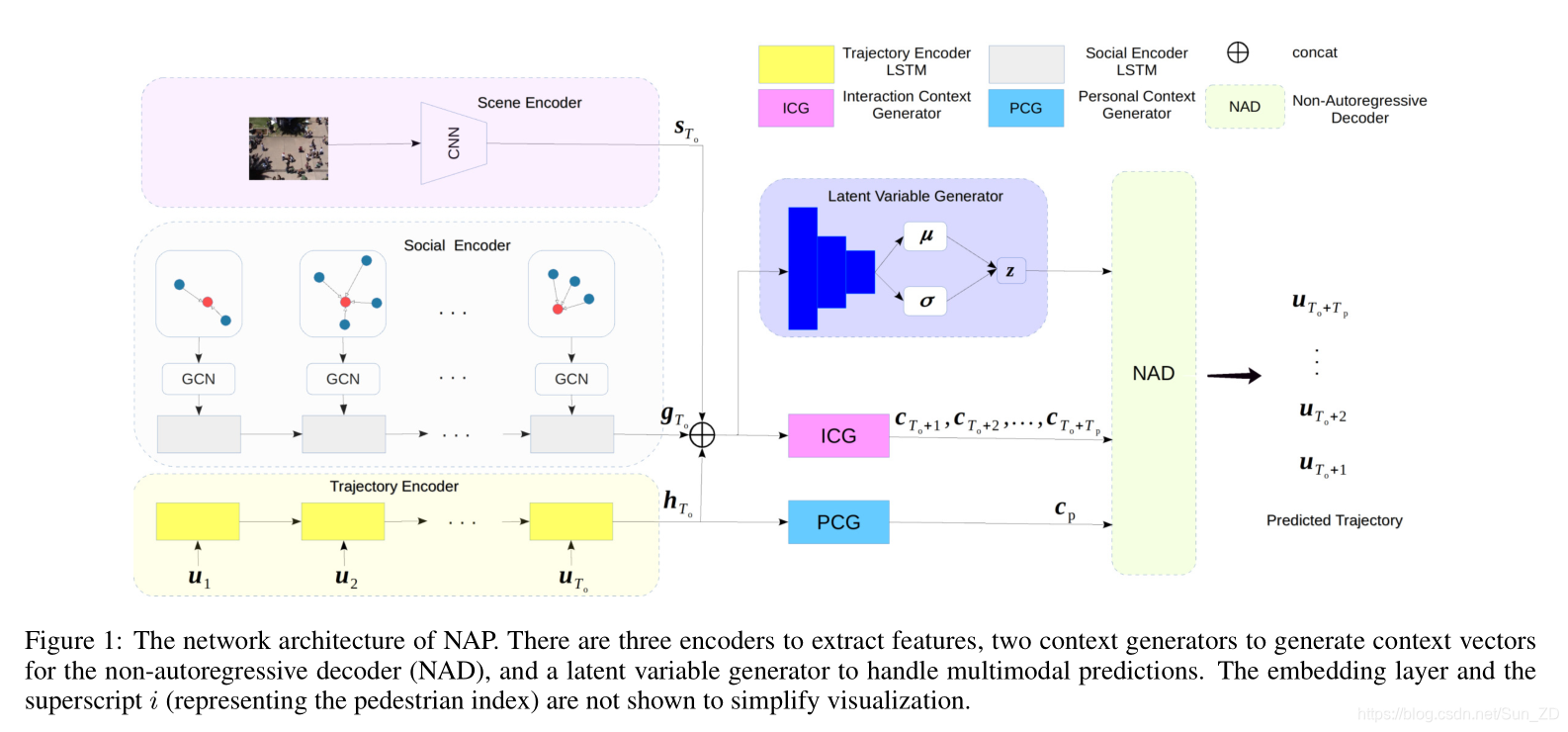
3.1 Feature Encoders(特征编码器)
在NAP中,有三个特征编码器:
轨迹编码器,用于学习每个行人观察到的历史运动的表示;
社会编码器,以学习其他行人的影响力的表示;
场景编码器,以学习场景特征的表示。
(1)Trajectory Encoder.
第一个行人在观察阶段的坐标(t = 1,…,To)首先通过嵌入层φ(·) 嵌入到高维空间中。 然后,在不同的时间步长上,将嵌入的特征用作LSTM层(由LSTM ENC(·)表示)的输入,以获取编码的隐藏状态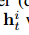 ,该状态捕获的路径信息。 该轨迹编码由下式给出:
,该状态捕获的路径信息。 该轨迹编码由下式给出:
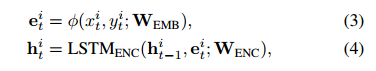
其中W EMB和W ENC是相应层的可训练权重。
(2)Social Encoder.
在每个时间步t,NAP通过图形Gti =(Vti; Eti)捕获对第i个行人的社会影响。 第i个行人和所有其他行人Nt(i)在同一时间步被认为是集合Vti中的节点。 连接第i个行人和Nt(i)中的行人的边形成边集Eti。
然后,我们使用图卷积网络(GCN)处理这些图。 在第l个图卷积层中,行人i的节点特征汇总如下:
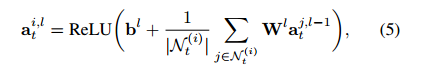
其中Wl和Bl是权重矩阵和偏差项。 在第一层,我们初始化节点特征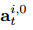 作为第i个行人的位置坐标,即
作为第i个行人的位置坐标,即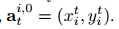
社交图特征gti(等式(6))被设计为在每个时间步t对行人i的周围(或社交)信息进行建模。 为了计算该特征,用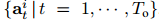 表示的节点特征; 在观察阶段的所有时间步中,从最终GCN层开始,穿过具有可训练权重WSG的LSTM层,即
表示的节点特征; 在观察阶段的所有时间步中,从最终GCN层开始,穿过具有可训练权重WSG的LSTM层,即
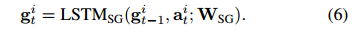
(3)Scene Encoder与在观察阶段处理每个图像帧与其他方法(例如[Xue等人,2018; Sadeghian等人,2019])不同,NAP的场景编码器仅将图像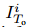 作为输入,因为场景编码器 专注于静态信息,例如场景布局和障碍物。 这不仅节省了计算时间,而且在预测开始于t = To + 1之前,还提供了最新和足够的场景上下文。我们使用CNN对场景特征
作为输入,因为场景编码器 专注于静态信息,例如场景布局和障碍物。 这不仅节省了计算时间,而且在预测开始于t = To + 1之前,还提供了最新和足够的场景上下文。我们使用CNN对场景特征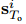 进行建模,如下所示:
进行建模,如下所示:
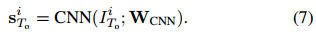
我们采用了DeepLabv3 +的优点[Chen et al,2018],它是一种先进的语义分割架构,并将WCNN的初始值设置为DeepLabv3 +中的权重矩阵,该矩阵预先在Cityscapes数据集上进行了训练[Cordts 2016]。
3.2 Context Generators(上下文生成器)
上下文生成器的作用是聚合特征编码器的输出,以供下游解码器用于轨迹预测。 我们在NAP中使用了两个上下文生成器:
(i)与时间无关的个人上下文生成器,因为其输入是仅根据第i个行人自己的轨迹计算出的隐藏状态命中值;
(ii)特定于时间的交互上下文生成器,因为其输入同时包含社交图和场景交互功能(social graph and scene
interaction features)。
(1)Personal Context Generator (PCG).(个人上下文生成器(PCG))
我们使用多层感知器(MLP)对上下文生成器建模。 输出上下文向量c计算为
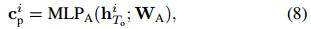
其中WA是相应的权重矩阵。 上下文cip捕获“个人线索(cues),例如在观察阶段忽略行人周围环境的行人首选的行走速度和方向。 这种情况是与时间无关的,因为在不考虑社交和场景影响的情况下,这样的个人提示(personal cues)在整个轨迹上都可以保持不变,例如,行人在撞到障碍物 或其他行人时可以继续以直线或快速的速度行走而不会受到任何惩罚,因为等式中没有社交图和场景特征。
(2)Interaction Context Generator (ICG).(交互上下文生成器(ICG))
该上下文生成器结合了社交图和场景特征。这两种类型的影响使上下文生成器具有时间特定性,例如,当行人可以在其轨迹的初始部分快速行走时,他/ 她需要在轨迹的后半部分减速或绕行,以避免其他行人或场景障碍。 与PCG相似,我们使用MLP对ICG进行建模,但是其输
入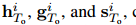 包含更丰富的信息。 ICG的输出包括针对预测阶段中不同时间步长的不同上下文向量,如下所示:
包含更丰富的信息。 ICG的输出包括针对预测阶段中不同时间步长的不同上下文向量,如下所示:
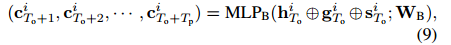
WB是对应的权重向量。
3.3 Latent Variable Generator(潜在变量生成器)
对于多峰预测,NAP被设计为通过潜在变量µ和σ生成多个轨迹(见图1)。 尽管[Lee et al。,2017; Gupta等人,2018年; Li,2019; Huang等,2019]也使用潜变量来处理多模态,这些方法中的潜变量要么直接从正态分布中采样,要么以观察到的轨迹为条件的多元正态分布。
为了使我们的潜在变量更了解社会和场景线索,我们设计了NAP,以从观察到的轨迹,社会影响力和场景影响特征中学习采样分布的参数(μi和σi)。 为此,将连接特
征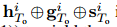 传递给两个不同的MLP(公式(10)-(11)),以产生均值矢量µi和方差σi,最后生成zi用于下游非自回归解码器:
传递给两个不同的MLP(公式(10)-(11)),以产生均值矢量µi和方差σi,最后生成zi用于下游非自回归解码器:
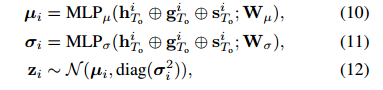
其中Wµ和Wσ是MLPµ(·)和MLPσ(·)的可训练权重。 重新参数化技巧[Kingma and Welling,2013]被应用于对潜在变量zi进行采样。
3.4 Non-Autoregressive Decoder (NAD)非自回归解码器(NAD)
在[Gu et al,2018]的工作中,作者在他们的模型中引入了一个组件,该组件增强了传递给解码器以解决其机器翻译问题的输入。 这样做的目的是帮助模型学习句子中的内部依赖关系(在其非自回归翻译器中不存在)。
在[Guo et al,2019]的工作中,作者使用位置模块来提高解码器执行本地重新排序的能力。 NAP中的上下文生成器与这两种方法起着相似的作用。 在测试阶段,训练有素的PCG和ICG能够为新的(unseen)生成上下文向量
观察轨迹,以帮助解码器改善其对轨迹预测的时间意识。 虽然ICG可以生成特定时间上下
文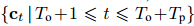 ,但它显然比PCG更重要,但还需要时间不可知的PCG,以帮助NAD与特定轨迹保持联系。
,但它显然比PCG更重要,但还需要时间不可知的PCG,以帮助NAD与特定轨迹保持联系。
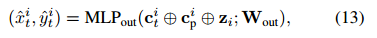
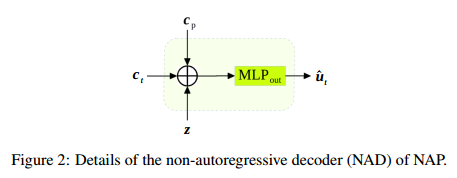
其中MLPout(·)是用于预测位置坐标的MLP。 在预测阶段的所有时间步中共享其参数Wout。 注意,由于ci t取决于t,因此在预测阶段的每个时间步t传递到图2中的NAD的输入都是不同的。 我们可以认为上下
文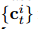 的功能类似于LSTM解码器中的隐藏状态,只是它们不是递归定义的。
的功能类似于LSTM解码器中的隐藏状态,只是它们不是递归定义的。
3.5 Implementation Details(实现细节)
式中的嵌入层φ公式(3)被建模为单层感知器,输出用于输入位置坐标的32维嵌入向量。 轨迹编码器和社交编码器的LSTM层的隐藏状态的维度均为32。社交编码器中的GCN是单图卷积层(即等式(5)中的 l = 1)。 对于ICG,MLPB是具有ReLU激活的三层MLP。 所有其他MLP在公式(8),(10),(11)和(13)都是单层MLP。除了在4.4节中我们探讨了不同预测长度的预测性能外,观察到的输入轨迹长度为8个时间步长(To = 8 ),对于所有其他实验,预测长度为12个时间步长(Tp = 12)。
我们使用Python中的PyTorch框架实现了NAP及其变体(第4.3节)。 Adam优化器用于将学习率设置为0.001来训练我们的模型最小批量为128。
4 实验
4.1 Datasets and Metrics(数据集和指标)
我们使用流行的ETH [Pellegrini,2009]和UCY [Lerner,2007]数据集,它们总共包括5个场景:ETH,HOTEL,UNIV,ZARA1和ZARA2。 类似于[Sadeghian et al,2019; Zhang et al,2019],我们将每个行人的坐标标准化,并通过旋转轨迹来扩充训练数据。 由于原始场景图像用作提取场景特征的输入,因此,当旋转输入轨迹时,我们也会旋转输入图像。 与文献[Alahi et al,2016; Gupta,2018; Sadeghian,2019; Huang et al,2019],采用留任策略进行训练和测试。 所有方法均基于两个标准指标进行评估:平均位移误差(ADE)和最终位移误差(FDE)。 较小的误差表示较好的预测性能。
4.2 Comparison with Other Methods比较其他方法
我们将NAP与以下最新的轨迹预测方法进行了比较:
Social-LSTM [Alahi,2016],
SGAN [Gupta,2018],
MX-LSTM [Hasan,2018] ,
Nikhil&Morris [Nikhil and Morris,2018],
Liang [Liang,2019],
MATF [Zhao,2019],
SRLSTM [Zhang,2019],
SoPhie [Sadeghian,2019],
IDL [Li,2019],
STGAT [Huang ,2019)和
SocialBiGAT [Kosaraju,2019]
在表1中,所有比较的方法根据对每个输入的观察轨迹是只生成一个预测(表的上半部分)还是生成多个预测(下半部并在#列下的刻度表示)而分为两组。 考虑的多峰预测数量为20。所报告的ADE和FDE是从20的最佳预测中计算得出的。有五种方法同时记录了单峰和多峰预测结果,因此它们出现在表的两半中:SGAN,MATF,STGAT, Liang et al和NAP。
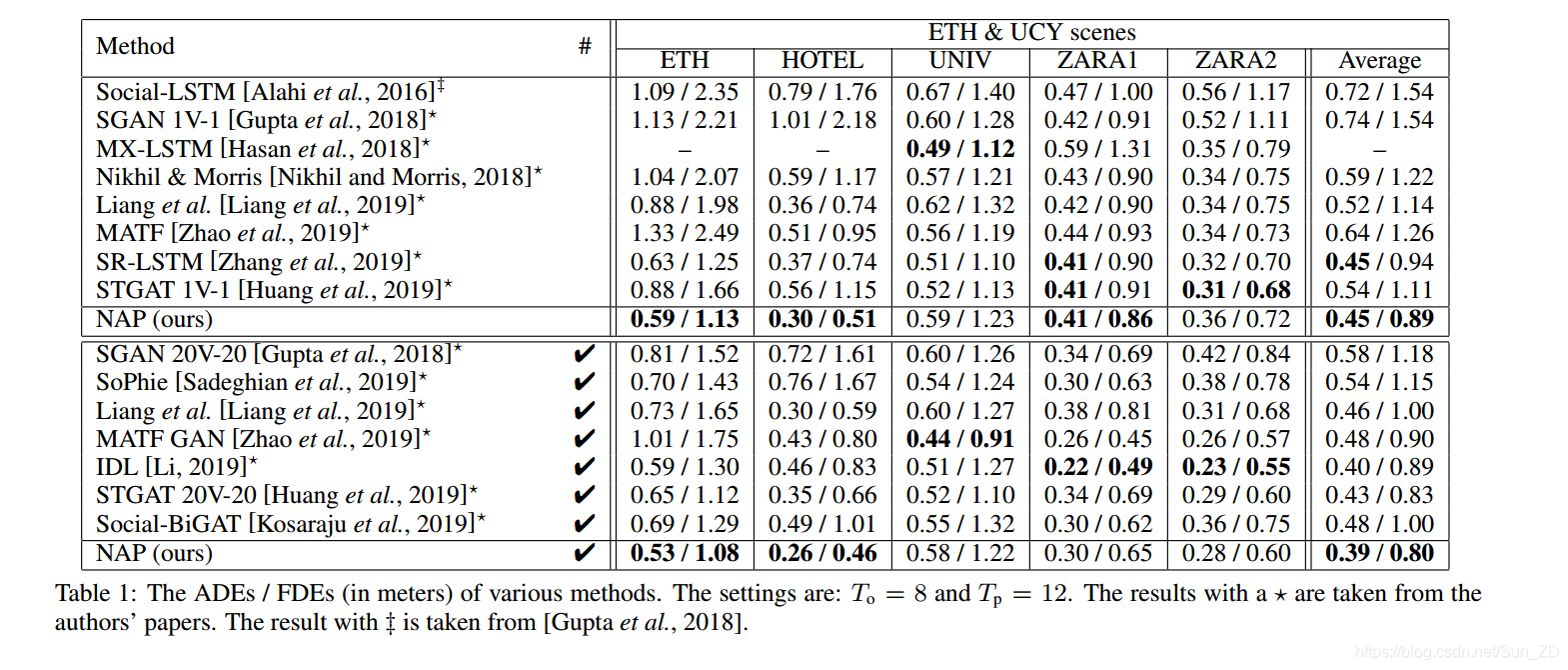
我们提出的方法能够获得与单个预测设置的最新方法相当的结果。 具体而言,NAP具有与SR-LSTM相同的最小平均ADE(0.45m),同时在平均FDE(0.89m)方面优于所有方法。 除NAP之外,SR-LSTM,MXLSTM和STGAT 1V-1在一个或多个场景上也具有最佳性能。
在表1的下半部分,给出并比较了多模式预测的结果。 平均而言,我们的NAP可以实现0.39m的最小ADE和0.80m的最小FDE。 对于每个场景,在表的下半部分中达到最小ADE / FDE的最佳性能的是NAP,IDL,MATF和GAN。 综上所述,这些结果证明了我们提出的方法在单峰和多峰预测环境中的有效性。
4.3 Ablation Study(消融研究)
为了探索在我们提议的方法中不同环境协同工作的有效性,我们考虑以下列出的NAP的四个变体:
•NAP-P:此变体仅使用个人上下文生成器(与时间无关的上下文,图1中的浅蓝色PCG框),即等式(13)中的交互上下
文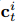 被除去。
被除去。
•NAP-ISS:与NAP-P相比,NAP-ISS禁用个人上下文并基于特定于时间的交互上下文来预测预测(图1中的粉红色框)。
个人上下文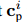 在公式(13)中被除去。 NAP-ISS的其余部分与NAP相同。
在公式(13)中被除去。 NAP-ISS的其余部分与NAP相同。
•NAP-ISg:为了进一步研究消除场景的影响,我们从等式(9)中的“交互上下文生成器”中删除了场景特征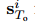 形成这个变体。即,使用社交图和场景特征两者来计算NAP-ISS中的交互上下文成本,而仅使用社交图特征来计算NAP-ISg中的成本。
形成这个变体。即,使用社交图和场景特征两者来计算NAP-ISS中的交互上下文成本,而仅使用社交图特征来计算NAP-ISg中的成本。
•NAP-ISc:类似于NAP-ISg,此变体旨在研究消除社交的影响。我们将社交图特征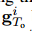 删除,但将场景特征
删除,但将场景特征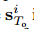 保留在公式(9)中。因此,上下文
保留在公式(9)中。因此,上下文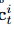 仅从场景特征中计算得出。
仅从场景特征中计算得出。
在我们的消融研究中,我们仅比较了这四个变体的单个预测性能(参见表2),即在实验中从等式(13)中删除了用于多峰性的潜变量zi。
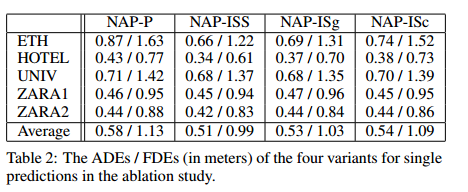
在实验中,通常,仅使用个人上下文(与时间无关)的NAP-P的性能比其他三个变体差。这并不意外,因为如果没有特定于时间的上下文,则NAD无法在预测阶段针对不同时间步长良好的预测。将这三个基于交互上下文的变体相互比较,发现由于社交图和场景特征的存在,NAP-ISS优于其他两个变体就不足为奇了。至于针对NAP-ISc的NAP-ISg,我们观察到NAP-ISg略胜于NAP-ISc。这表明社会影响力比现场影响力(scene influence)更为重要。但是,应该注意的是,ETH / UCY数据集中的五个场景在人行道上没有很多障碍物。 NAP-ISg的性能稍好,这表明在这些数据集中,社交(行人)交互比场景交互更多。
比较表2中四个变量和表1中NAP的结果,我们观察到NAP的性能优于所有四个变量。我们的消融研究证明,在NAP中必须存在所有上下文。
4.4 Different Prediction Lengths(不同的预测长度)
除了表1和表2中使用的预测长度设置(Tp = 12帧,对应4.8秒)之外,还类似于先前的工作SGAN [Gupta,2018]和STGAT [Huang,2019] ,我们针对预测长度Tp = 8帧(或3.2秒)进行实验,以进一步评估NAP的性能。 表3显示了此预测长度设置的平均ADE / FDE结果。 从表1的“平均值”列复制“ Tp = 12”列下的图。由于Tp的增加而导致的每个误差增量(最后一列)的计算公式如下: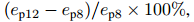 ,其中ep12 和ep8是相同方法的Tp = 12和Tp = 8时的误差(ADE或FDE)。
,其中ep12 和ep8是相同方法的Tp = 12和Tp = 8时的误差(ADE或FDE)。
不出所料,表3中显示的所有方法对于较短的预测长度都具有更好的性能。 在表的上半部分,当为每个输入生成预测轨迹时,Social-LSTM和SGAN 1V-1的误差增量超过50%。 与这两种方法相比,STGAT 1V-1的ADE和FDE的误差增量较小。 对于多模式预测(表的下半部分),STGAT 20V-20再次优于SGAN 20V-20。
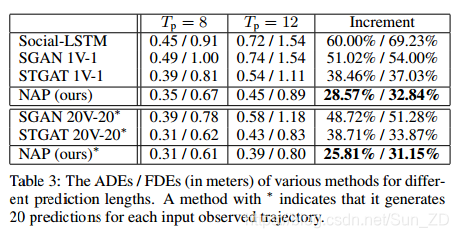
从表3中我们可以看出,对于预测长度设置以及单模式和多模式预测,NAP始终优于所有其他方法。 此外,当Tp增加时,NAP对于ADE和FDE的误差增量也最小。 这表明NAP在生成长轨迹方面更强大。 原因是由于解码器的非自回归特性,它不仅可以独立预测不同时间步长的位置坐标,而且可以在预测长度增加时帮助最小化预测误差的累积。
4.5 Qualitative Results(定性结果)
图3说明了NAP生成的一些预测示例。观察到的和地面的真实轨迹以黄色和绿色显示。每个行人的20个预测的最佳轨迹以粉红色显示。为了更好地可视化,视频帧已变暗和模糊。这些示例涵盖了行人的不同移动行为。
例如,
图3(a)显示了两个简单的直线路径场景,
图3(b)和(c)显示了平缓的转向场景,
图3(d)显示了更困难的场景,在该场景中会发生突然转向在观察阶段即将结束时。尽管图3(d)中的预测轨迹(粉红色)与地面真相轨迹并不完全重叠,但是NAP仍然能够根据后期转弯提示正确预测轨迹。

图4显示了另外两个困难的场景,其中所有20条预测轨迹都以热图的形式显示在每个行人周围。对于图4(a)中的行人和图4(b)中的右行人,它们几乎都在观察阶段的最后一帧突然转弯。但是,NAP仍然能够给出良好的预测轨迹,因为所有可能的路径(包括地面真相轨迹(绿色))都已被热图覆盖。图4(b)中的左行人是一个停车场景。停车后,行人可以保持静止或继续向任何方向行走。生成的热图很好地覆盖了可能的路径。然而,由于那里有长椅,它在左下方区域有一个小凹痕,表明行人必须绕过障碍物。此示例说明了在方法中包括场景影响的重要性。

5 结论
我们提出了一种称为NAP的新方法,该方法可以处理行人轨迹预测过程中的社会影响和场景影响。 NAP使用网络中的可训练特征编码器捕获这些影响。
此外,NAP通过潜在变量生成器处理多模式预测,该潜在变量生成器对描述每个行人的多个合理路径的采样分布进行建模。 与现有的轨迹预测方法不同,NAP的解码器是非自回归的。 因此,NAP能够同时预测不同时间步长的预测,或者仅预测感兴趣的那些时间步长。 通过我们广泛的实验和消融研究,已证明NAP中使用的上下文编码器是有效的。 NAP不仅可以达到最先进的性能,而且随着预测长度的增加,其误差增量也较小。