课程目录 小象学院 - 人工智能
关注公众号【Python家庭】领取1024G整套教材、交流群学习、商务合作。整理分享了数套四位数培训机构的教材,现免费分享交流学习,并提供解答、交流群。
你要的白嫖教程,这里可能都有喔~
通过前面几个课时的学习,你已经掌握了k近邻算法的核心原理,并且能够使用python实现属于自己的k近邻算法,在这里要给你一个大大的赞!!!
我们知道在运行k近邻算法之前,要给k设置个初始值,那么为什么要在k近邻算法运行之前设置这个k值呢?
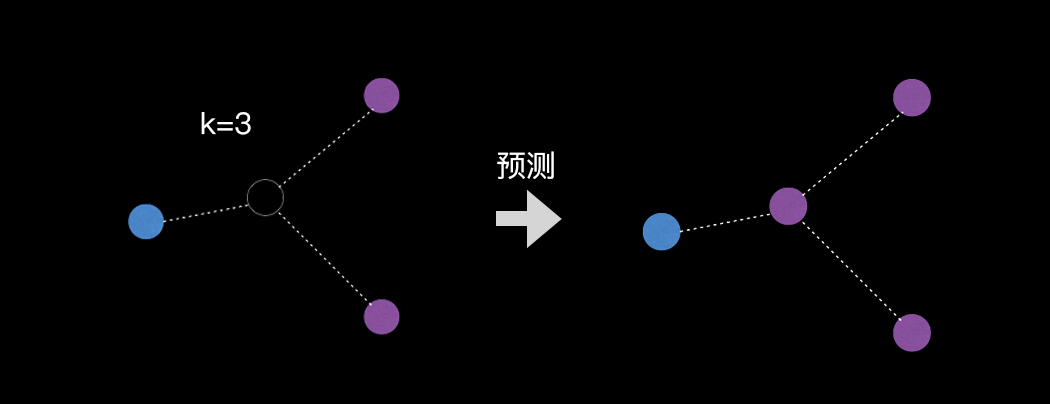
因为k近邻算法的核心原理是:对于一个未知的样本,如果要预测这个样本的分类(类别),就看离它最近的k个邻居都是什么分类, 从最近的k个邻居中,选择类别占比最多的一个分类作为未知样本的预测分类,所以k近邻算法需要提前设置k值。
超参数介绍
k值在k近邻算法中扮演着如此重要的角色,那么它配拥有一个特别酷的名字,叫做超参数。
超参数可以理解成:在运行机器学习算法之前预先设置的参数。
不要纠结为什么叫“超参数”这个名字,它跟一个小朋友的小名叫“狗蛋”是一个道理。

既然超参数是在机器学习算法运行之前人工设置的一个值,那么这个超参数值设置成多少合适呢?又如何寻找一个好的超参数呢?

k值的选取
这个问题有两个常用的解决方法,第一种方法:根据经验选择k值,这种方法需要具备一定的经验,有点玄学的感觉,在这里咱们不做过多的讨论。
第二种方法:网格搜索,在一组给定的候选参数中,通过循环遍历,尝试每一种可能性,选取表现最好的那个参数作为最优解,也可以把这种方法称为暴力搜索或穷举搜索 。
调参之网格搜索
机器学习工程师经常做的一件事就是调参,网格搜索是一种常用的调参方法,也有人戏称机器学习工程师为“调参工程师”(此处捂嘴笑3分钟)。
调参的过程就是针对超参数,在其众多的参数值中选择一个最优参数,使算法模型的表现最好(预测的更准确)。
为什么叫网格搜索呢?不就是用个循环,遍历一组参数值,找到一个还不错的参数,使算法模型预测的更准确么,非要弄个不好理解的概念让我学!
别着急,请听我给你慢慢道来~
以包含两个超参数的模型为例,目前已知参数a有三种可能值(10,11,12),参数b有五种可能值(1,2,3,4,5),把参数a和b所有可能的组合列出来可以表示成一个3*5的表格,表格中每一个组合结果的单元格就是一个网格。

有了这个包含所有参数组合的表格,就可以使用循环遍历表格中的每一个参数组合,应用到模型中。这个遍历表格的过程就像在网格中搜索,试图找到最优解,所以把这种寻找最优解的过程称为网格搜索(grid_search)。
代码实现
说了这么多,到底网格搜索应该怎么用呢?下面开始我的表演(哼哼哈嘿~)
kNN算法中使用网格搜索寻找超参数k的最优解:给定一组k值,通过循环遍历,把每个k值分别代入算法模型,通过比较每次模型的准确率,最后找到超参数k的最优解。
导入数据集
step1. 使用sklearn提供的手写数字数据集
AI_5_0_1
from sklearn import datasets
digits = datasets.load_digits() # 加载手写数字数据集
x = digits.data # 样本特征,每个样本包括8*8像素的图像,也就是一个样本有64个特征(像素点)
y = digits.target # 样本标签,手写的数字是什么,[0, 9]整数的标签(1797, 64)
为了方便理解数据集,通过matplotlib显示数据集中第一个手写数字图片的样子(样本特征数据集x与标签数据集y是一一对应的)
AI_5_0_2
from sklearn import datasets
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
digits = datasets.load_digits()
x = digits.data
y = digits.target
print("第一张手写图片的64个特征:")
print(x[0])
print("第一张手写图片中的数字是:",y[0])
# 获取手写第一张图片
plt.imshow(digits.images[0])
plt.show()第一张手写图片的64个特征:
[ 0. 0. 5. 13. 9. 1. 0. 0. 0. 0. 13. 15. 10. 15. 5. 0. 0. 3.
15. 2. 0. 11. 8. 0. 0. 4. 12. 0. 0. 8. 8. 0. 0. 5. 8. 0.
0. 9. 8. 0. 0. 4. 11. 0. 1. 12. 7. 0. 0. 2. 14. 5. 10. 12.
0. 0. 0. 0. 6. 13. 10. 0. 0. 0.]
第一张手写图片中的数字是: 0
![]()

训练集和测试集划分
setp2. 划分训练数据集和测试数据集
AI_5_0_3
from sklearn import datasets
from sklearn.model_selection import train_test_split
digits = datasets.load_digits()
x = digits.data
y = digits.target
# x_train:样本特征 训练数据集
# x_test :样本特征 测试数据集
# y_train:手写数字标签 训练数据集
# y_test :手写数字标签 测试数据集
# train_test_split函数中的参数test_size:设置测试数据集占比,0.2表示从整体的数据集中取出20%作为测试集
# train_test_split函数中的参数random_state:设置一个随机种子值,可以任意设置,保证多次运行相同一段代码划分的数据集是相同的
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=111)
print("x_train样本数量:",x_train.shape[0])
print("y_train标签数量:",y_train.shape[0])
print("x_test样本数量:",x_test.shape[0])
print("y_test标签数量:",y_test.shape[0])x_train样本数量: 1437
y_train标签数量: 1437
x_test样本数量: 360
y_test标签数量: 360![]()
网格搜索寻找最优k值
step3. 使用网格搜索寻找kNN超参数k的最优解
AI_5_0_4
from sklearn import datasets
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
# 从sklearn机器学习库中引入内置的kNN算法模型KNeighborsClassifier
from sklearn.neighbors import KNeighborsClassifier
digits = datasets.load_digits()
x = digits.data
y = digits.target
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=111)
best_score = 0.0 # 存储准确率最大值,初识值是0
best_k = -1 # 存储准确率最大值的k值,初识值是-1
# 设置一组k值,值的范围从1到10,循环遍历这组k值,
# 注意:range函数返回的数据集是左闭右开区间,所以不包含11
for k in range(1, 11):
# 创建一个kNN算法模型对象
kNN = KNeighborsClassifier(n_neighbors=k)
# 使用训练数据集训练kNN算法模型
kNN.fit(x_train, y_train)
# 通过测试数据集,验证取当前k值的模型准确率
score = kNN.score(x_test, y_test)
print("目前已知best_score=",best_score)
print("本次循环k={},kNN准确率score={}".format(k,score))
# 如果当前k值的kNN模型预测值准确率 大于 之前存储的最好准确率,则更新best_k为当前k值,best_score为当前准确率
if score > best_score:
best_k = k
best_score = score
print("本次更新完毕!")
print("*************Game Over*************")
print("best_k =", best_k)
print("best_score =", best_score)目前已知best_score= 0.0
本次循环k=1,kNN准确率score=0.9916666666666667
本次更新完毕!
目前已知best_score= 0.9916666666666667
本次循环k=2,kNN准确率score=0.9888888888888889
目前已知best_score= 0.9916666666666667
本次循环k=3,kNN准确率score=0.9833333333333333
目前已知best_score= 0.9916666666666667
本次循环k=4,kNN准确率score=0.9805555555555555
目前已知best_score= 0.9916666666666667
本次循环k=5,kNN准确率score=0.9777777777777777
目前已知best_score= 0.9916666666666667
本次循环k=6,kNN准确率score=0.9777777777777777
目前已知best_score= 0.9916666666666667
本次循环k=7,kNN准确率score=0.9777777777777777
目前已知best_score= 0.9916666666666667
本次循环k=8,kNN准确率score=0.9805555555555555
目前已知best_score= 0.9916666666666667
本次循环k=9,kNN准确率score=0.9777777777777777
目前已知best_score= 0.9916666666666667
本次循环k=10,kNN准确率score=0.9722222222222222
*************Game Over*************
best_k = 1
best_score = 0.9916666666666667通过网格搜索找到了当k=1时,k近邻算法的预测准确率最高达到了99.17%(四舍五入的结果)。
本小节总结:
-
超参数:在运行机器学习算法之前需要预先设置值的参数
-
网格搜索:在一组给定的候选参数中,通过循环遍历,尝试每一种可能性,选取表现最好的那个参数作为最优解
今天我们先到这里,拜拜~
联系我们,一起学Python吧
分享Python实战代码,入门资料,进阶资料,基础语法,爬虫,数据分析,web网站,机器学习,深度学习等等。
 关注公众号「Python家庭」领取1024G整套教材、交流群学习、商务合作
关注公众号「Python家庭」领取1024G整套教材、交流群学习、商务合作