课程目录 小象学院 - 人工智能
关注公众号【Python家庭】领取1024G整套教材、交流群学习、商务合作。整理分享了数套四位数培训机构的教材,现免费分享交流学习,并提供解答、交流群。
你要的白嫖教程,这里可能都有喔~
恭喜你闯进了第7关,让我们继续探索机器学习的奥秘,体验算法的魔力Amazing~

前面我们已经学习了k近邻算法简称kNN,kNN解决的是分类问题,也就是说给kNN输入一个样本,它的预测结果是一个类别标签。
场景引入:预测房价
在实际应用中,我们不只要预测一个样本的类别,有时还要预测一个具体的数值,比如:根据房屋面积预测房价,房价是一个具体的数值而不是一个分类。
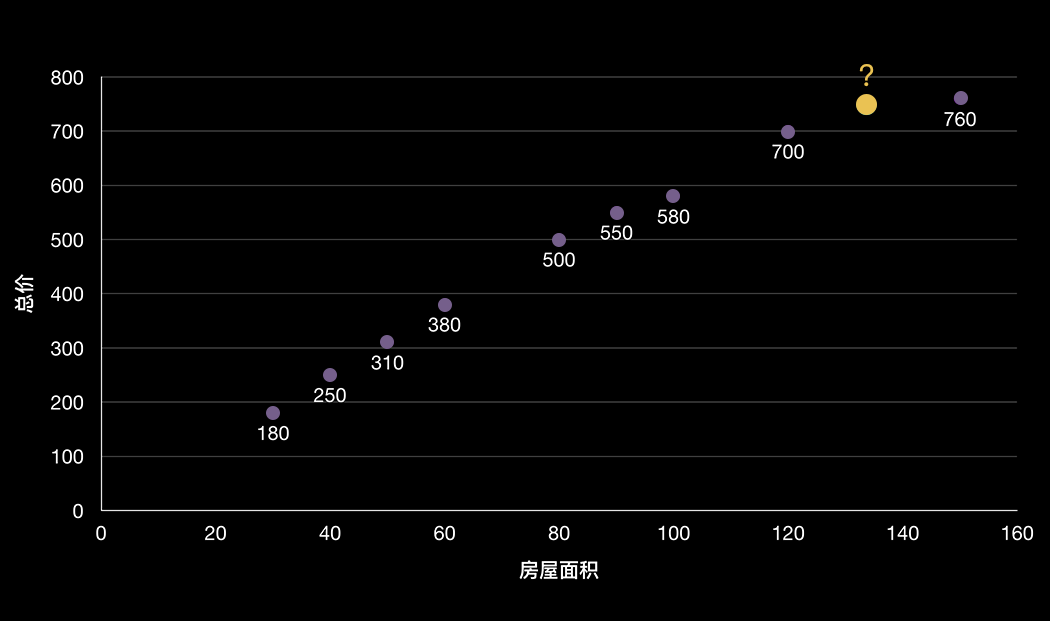
那我们现在就要找到一个机器学习算法模型,它可以解决输入一个样本,预测结果是一个数值这样的问题,这种问题我们称它为回归问题。
解决回归问题有一个思想简单、实现容易、解释性强的算法,它就是家喻户晓的线性回归算法。
那我们还是以房价预测的案例讲解线性回归的原理。
我们假设房屋面积与价格之间存在一种线性关系,也就是通过一条直线可以把不同面积对应的房屋总价尽可能的串联起来,假设直线方程是:y = 5x + 10 ,方程中的x表示房屋面积,y表示把房屋面积带进方程得出的房屋总价。我们可以把这个方程叫做房屋价钱计算器。
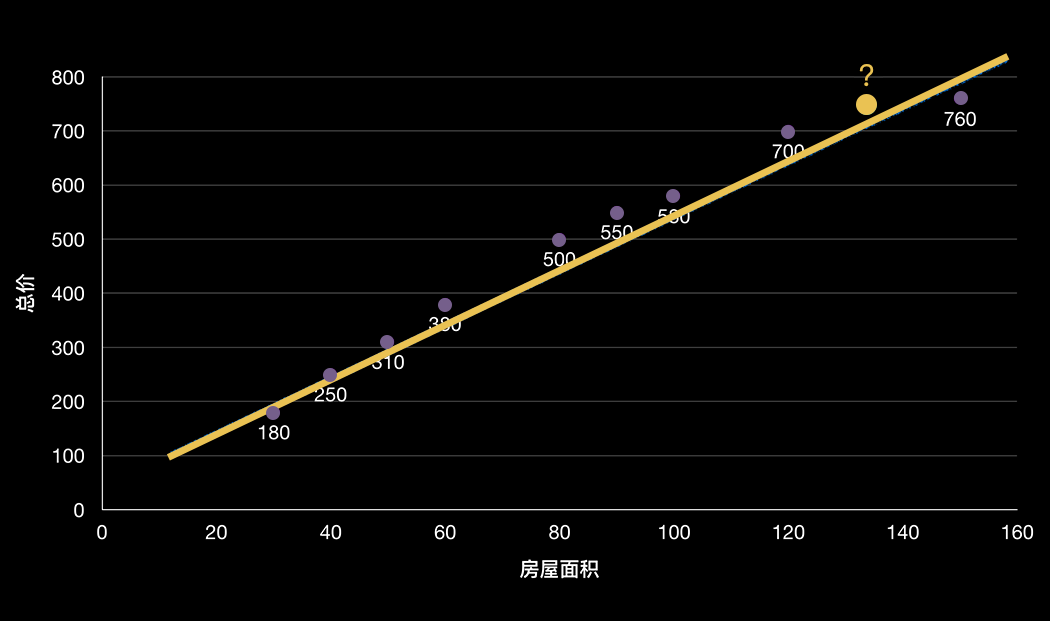
如果你是一个房产中介,当你找到一个要出售的房子时,房主想知道这套140平米的房子现在大概能卖多少钱?
这个时候你就可以把房屋的面积填入房屋计算器,然后房屋计算器按照y = 5x + 10的公式计算,得到一个评估价钱710万,你就可以把这个评估价告诉房主,房主一看哇塞这么多钱!马上能就把房子交给你代理出售了,是不是美滋滋^_^
其实线性回归算法就是要找到这样的一条线,可能是直线,也可能是曲线。
我们先从简单的入手,先学习怎么找一条直线。
我们在初中的时候学习过二元一次方程:y = ax + b,如果在二维平面上根据这个方程画图的话,将会画出一条直线。
还是拿房价预测的例子解释,我们把房屋面积作为特征 x ,房屋的交易总价作为标签 y,如果要找出面积与价格之间的关系的话,就可以通过y = ax + b方程表示。
在历史的房屋交易数据中,每套房卖多少钱都是有记录的,也就是说房屋面积 x 和房屋的交易总价 y 都是已知的。
如果想找到一条直线表示房屋面积和价格之间的关系的话,就是要找到a和b的值。
像房屋价格预测这个例子,样本(历史记录的已卖出的房子)只有一个特征x(房屋面积),使用线性回归法进行预测的话,我们称之为简单线性回归。
俗话说“麻雀虽小,五脏俱全”,虽然简单线性回归的名字很简单,但是不要小看它,通过简单线性回归的学习你可以掌握线性回归算法的很多内容,之后可以推广到更加复杂的线性回归算法上。

线性回归原理
我们来继续研究简单线性回归,假设我们已经知道y = ax + b中的a和b的值,在二维空间上我们根据公式画出了一条直线。
那么在二维空间上的任意一个样本点它所对应的实际横坐标是 ![]() ,实际纵坐标是
,实际纵坐标是![]() 。
。
同一个样本点通过 y = ax + b 计算得到的纵坐标是![]() ,计算过程就是把样本点的横坐标
,计算过程就是把样本点的横坐标 ![]() 带入公式得到
带入公式得到![]() 。
。
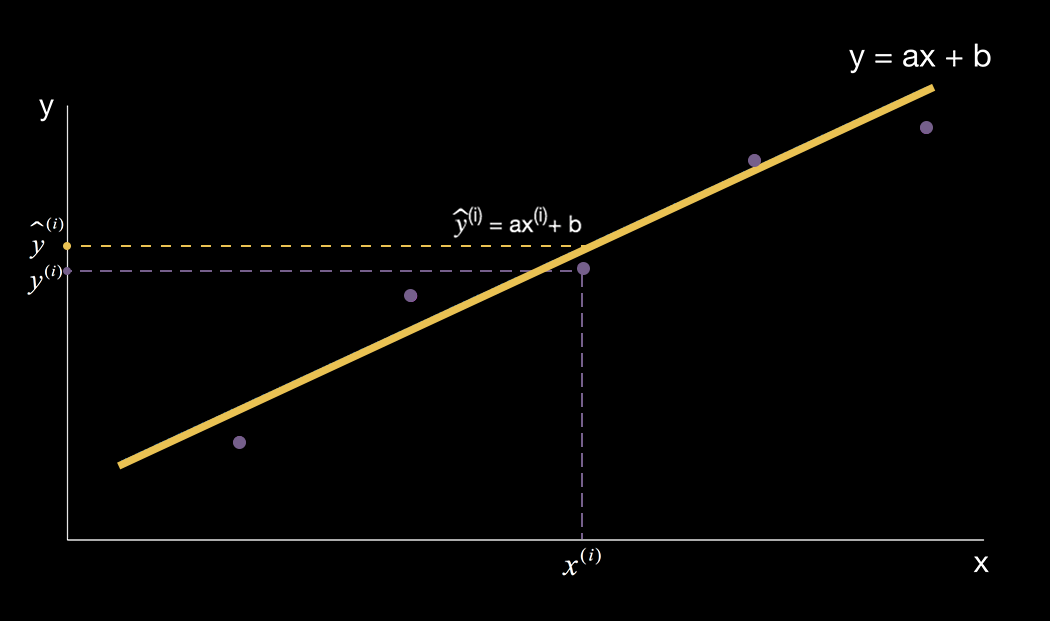
那么![]() 其实就是使用简单线性回归算法针对样本点的
其实就是使用简单线性回归算法针对样本点的 ![]() 这个特征得出的预测值。
这个特征得出的预测值。
从上面的二维平面图我们可以看出,样本点的预测值 ![]() 与真实值
与真实值 ![]() 之间有一段差距。
之间有一段差距。
但是我们是希望真实值![]() 与预测值
与预测值![]() 之间的差距越小越好,只有这样,当有新的样本通过简单线性回归算法模型预测的时候,预测结果才会更加准确。
之间的差距越小越好,只有这样,当有新的样本通过简单线性回归算法模型预测的时候,预测结果才会更加准确。
道理是这么个道理,还是需要用一个表达式来表达真实值![]() 与预测值
与预测值![]() 之间的差距,最直接的方式就是用真实值与预测值求差值:
之间的差距,最直接的方式就是用真实值与预测值求差值:![]() ,这只是一个样本的真实值与预测值之间的差距,不能反映所有样本的预测值与真实值之间差距。
,这只是一个样本的真实值与预测值之间的差距,不能反映所有样本的预测值与真实值之间差距。
所以要把所有已知样本的预测值与真实值相减的结果累加起来,这样才能反映出算法模型作用在所有样本上的预测效果。
计算过程:![]()
上面计算中,将每个样本的真实值与预测值直接相减之后再累加的这种方式可能会出现一个问题:有些差值是正数,有些差值是负数,累加之后最终结果是0。
按道理最终的累加结果是0,我们应该高兴,因为结果是0就证明模型的预测值与真实之间没有差距,非常完美的结果。但是这并不是真实的预测效果,有可能一个样本的真实值与预测值之间的差距是10000,另外一个样本的真实值与预测值之间的差距是 -10000,这两个值都表示预测值与真实值的差距很大,但是两个值相加之后就是0。
解决这个问题有一个好方法:![]() ,每个样本的真实值与预测值相减之后再平方,这就解决了多个样本累加互相抵消的问题。
,每个样本的真实值与预测值相减之后再平方,这就解决了多个样本累加互相抵消的问题。
那么考虑所有样本的计算过程就变成了:![]()
![]()
我们可以把上面的累加求和公式用一个更加简洁的公式表达:![]()
我来解释下这个公式的含义:
![]() 这个符号表示累加求和;
这个符号表示累加求和;
![]() 表示i的取值从1到n,也就是n个元素累加求和;
表示i的取值从1到n,也就是n个元素累加求和;
在机器学习这个场景下解释这个公式的含义就是:有n个样本,每个样本的真实值与预测值相减(计算它们之间的差距)后求平方,然后再累加。
接下来我们要做的事情就是使![]() 的值尽可能的小,值越小就证明预测值与真实值越接近,模型的预测效果越好。
的值尽可能的小,值越小就证明预测值与真实值越接近,模型的预测效果越好。
到这里简单线性回归的核心目标就出来了,简单线性回归的目标是:使 ![]() 的值尽可能小。
的值尽可能小。
简单线性回归中我们要找的最佳直线方程是:y = ax + b,这个直线方程根据样本的特征x,可以给出最佳的预测结果y。
根据直线方程得到的第i个样本的预测值是:![]()
将![]() 带入
带入 ![]() 替换
替换 ![]()
得到: ![]()
由于简单线性回归的目标是使 ![]() 的值尽可能小,同理是使
的值尽可能小,同理是使![]() 的值尽可能小。
的值尽可能小。
公式中的![]() 表示的是样本已知的标签值,
表示的是样本已知的标签值,![]() 表示的是样本已知的特征值,未知变量只有a和b,所以最终就是要找到a和b,使
表示的是样本已知的特征值,未知变量只有a和b,所以最终就是要找到a和b,使![]() 的值尽可能小。
的值尽可能小。
线性回归的损失函数
像这个公式 ![]() 可以评价模型的预测值和真实值的不一致程度,我们称这样的公式为损失函数,使用J(a,b)表示,损失函数的值越小,则表示针对训练数据的模型的性能越好。
可以评价模型的预测值和真实值的不一致程度,我们称这样的公式为损失函数,使用J(a,b)表示,损失函数的值越小,则表示针对训练数据的模型的性能越好。
到目前为止,我们已经找到了简单线性回归的损失函数![]() ,现在需要解决的问题就是找到一组a和b的值使损失函数的值最小。
,现在需要解决的问题就是找到一组a和b的值使损失函数的值最小。
最小二乘法
解决这个问题有一个非常简便的方法,它就是最小二乘法。最小二乘法通过最小化误差( ![]() 就是误差)的平方来寻找数据的最佳匹配函数。
就是误差)的平方来寻找数据的最佳匹配函数。
利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。
最小二乘法给出了a和b的计算公式:


a的计算公式中,![]() 是已知的第i个样本的特征值,
是已知的第i个样本的特征值,![]() 是所有样本的特征的平均值,都是已知的值,所以可以根据样本特征值直接算出a的值。
是所有样本的特征的平均值,都是已知的值,所以可以根据样本特征值直接算出a的值。
b的计算公式中,![]() 是所有样本标签的平均值,通过a的计算公式算出了a的值,也就可以算出b的值。
是所有样本标签的平均值,通过a的计算公式算出了a的值,也就可以算出b的值。
代码实现
老司机手把手使用python带着你实现一个简单线性回归
用类封装算法
AI_7_0_1_最小二乘法实现简单线性回归
# 最小二乘法实现简单线性回归
import numpy as np
import matplotlib.pyplot as plt
class SimpleLinearRegression:
def __init__(self):
# 初始化Simple Linear Regression 模型
# 简单线性回归模型中的未知变量a和b,初始化设置为None。说明:分别在两个变量后添加了一个下划线,表示是通过训练得到的参数
self.a_ = None
self.b_ = None
# 训练模型
def fit(self,x_train,y_train):
# 根据训练数据集x_train,y_train训练Simple Linear Regression模型'''
x_mean = np.mean(x_train) # 特征x均值
y_mean = np.mean(y_train) # 标签y均值
# 根据最小二乘先计算a的值
fz = 0.0 # 分子
fm = 0.0 # 分母
# 通过循环,根据a的计算公式,先计算出分子和分母
for x_i,y_i in zip(x_train,y_train):
fz += (x_i - x_mean) * (y_i - y_mean)
fm += (x_i - x_mean) ** 2
# 计算得到a的值
self.a_ = fz / fm
# 得到a的值之后,再计算b的值
self.b_ = y_mean - self.a_ * x_mean
return self
#给定待预测数据集x_predict,返回每个样本的预测值组成的向量
def predict(self,x_predict):
return np.array([self._predict(x_single) for x_single in x_predict])
def _predict(self,x_single):
# 给定单个待预测数据x,返回x的预测结果值
return self.a_ * x_single + self.b_
# 根据直线方程,带入特征向量x,计算的到向量y
def get_y_line(self,x):
print("y = {}x + {}".format(self.a_,self.b_))
return self.a_ * x + self.b_
# 在二维平面上画散点和直线图
def show_point_line(self,x,y):
plt.scatter(x,y) #绘制散点图
y_l = self.get_y_line(x) #根据直线方程,带入特征向量x,计算的到向量y
plt.plot(x,y_l,color="r") #绘制拟合出来的直线,颜色是红色
plt.axis([0, 6, 0, 6]) #横纵坐标范围0-6
plt.show()测试自定义算法
测试我们自定义的简单线性回归算法模型
AI_7_0_2
from sys import path
path.append(r"../data/course_util")
from ai_course_7_1 import *
%matplotlib inline
#数据集
x = np.array([1., 2., 3., 4., 5.])
y = np.array([1., 3., 2., 3., 5.])
simple_linear = SimpleLinearRegression()
simple_linear.fit(x,y)
y_predict = simple_linear.predict(np.array([6]))
print("y_predict:",y_predict)
simple_linear.show_point_line(x,y)在简单线性回归实现的过程中,计算a的时候,分子和分母是通过循环遍历所有样本计算得到的,使用循环的代码执行效率很低,如果样本数据量很大的话,性能将会非常低!

有没有提高性能的方法呢?这个问题对于经验丰富的老司机来说简直太easy了!
向量化操作
老司机给出的解决方法就是:向量化运算。
向量化运算的形式:![]() ,其中
,其中![]() 表示一个向量,
表示一个向量,![]() 表示另外一个向量。
表示另外一个向量。
所以a的计算公式也要整理成向量化运算的形式:
分子部分的 ![]() 相当于
相当于 ![]() 相当于
相当于 ![]()
分母部分的 ![]() ,可以把其中的
,可以把其中的![]() 看做是
看做是![]() ,
,![]() 看做是
看做是![]()
向量化运算比使用循环遍历样本集的方式性能更高,所以在进行算法模型训练的时候,尽量使用向量进行运算。
下面使用向量化运算优化之前我们自己封装的SimpleLinearRegression
由于只在SimpleLinearRegression类的fit函数中使用for循环进行计算,所以只需要将fit函数中的for循环替换成向量化运算即可。
AI_7_0_3_最小二乘法实现简单线性回归
# 最小二乘法实现简单线性回归
import numpy as np
import matplotlib.pyplot as plt
class SimpleLinearRegressionVectorize:
def __init__(self):
# 初始化Simple Linear Regression 模型
# 要求的未知变量a和b,在a和b前加一个下划线"_"表示这是一个私有属性,不能被外部访问
self.a_ = None
self.b_ = None
# 训练模型
def fit(self,x_train,y_train):
# 根据训练数据集x_train,y_train训练Simple Linear Regression模型'''
x_mean = np.mean(x_train) # 特征x均值
y_mean = np.mean(y_train) # 标签y均值
# 根据最小二乘法a的计算公式,通过向量化的方式计算a
self.a_ = (x_train - x_mean).dot(y_train - y_mean) / (x_train - x_mean).dot(x_train - x_mean)
# 得到a的值之后,再计算b的值
self.b_ = y_mean - self.a_ * x_mean
return self
#给定待预测数据集x_predict,返回每个样本的预测值组成的向量
def predict(self,x_predict):
return np.array([self._predict(x_single) for x_single in x_predict])
def _predict(self,x_single):
# 给定单个待预测数据x,返回x的预测结果值
return self.a_ * x_single + self.b_
# 根据直线方程,带入特征向量x,计算的到向量y
def get_y_line(self,x):
print("y = {}x + {}".format(self.a_,self.b_))
return self.a_ * x + self.b_
# 在二维平面上画散点和直线图
def show_point_line(self,x,y):
plt.scatter(x,y) #绘制散点图
y_l = self.get_y_line(x) #根据直线方程,带入特征向量x,计算的到向量y
plt.plot(x,y_l,color="r") #绘制拟合出来的直线,颜色是红色
plt.axis([0, 6, 0, 6]) #横纵坐标范围0-6
plt.show()测试最初版本的SimpleLinearRegression类和采用向量化优化的SimpleLinearRegressionVectorize类在fit训练的时候的性能差距。
AI_7_0_4
from sys import path
path.append(r"../data/course_util")
from ai_course_7_1 import *
from ai_course_7_2 import *
%matplotlib inline
# 使用10万个样本进行测试
m = 100000
big_x = np.random.random(size=m)
big_y = big_x * 3.0 + 4.0 + np.random.normal(size=m)
# 对自定义的两种简单线性回归模型对比测试
simple_linear1 = SimpleLinearRegression()
simple_linear2 = SimpleLinearRegressionVectorize()
%timeit simple_linear1.fit(big_x,big_y)
%timeit simple_linear2.fit(big_x,big_y)通过刚才的测试结果看,使用向量化运算优化的SimpleLinearRegressionVectorize的单次循环的训练速度要比原来使用for循环的方式快200倍左右(不同硬件环境下运行的时候可能会有些差异,依情况而定,反正就是快!)
所以我们平时在对数据集进行计算的时候,尽量使用向量化运算,可以大幅提高程序的性能。
今天我们先到这里,拜拜~
联系我们,一起学Python吧
分享Python实战代码,入门资料,进阶资料,基础语法,爬虫,数据分析,web网站,机器学习,深度学习等等。
 关注公众号「Python家庭」领取1024G整套教材、交流群学习、商务合作
关注公众号「Python家庭」领取1024G整套教材、交流群学习、商务合作