课程目录 小象学院 - 人工智能
关注公众号【Python家庭】领取1024G整套教材、交流群学习、商务合作。整理分享了数套四位数培训机构的教材,现免费分享交流学习,并提供解答、交流群。
你要的白嫖教程,这里可能都有喔~
Hi,欢迎来到小象学院!从今天起,我将带领你进入一个看似神秘但实际上很有趣的领域—人工智能,希望通过本关的学习,你能体会到人工智能的魅力,并对它背后最重要的驱动力—机器学习有一定了解。准备好了吗,让我们开始吧!
说起人工智能,你首先想到的是什么?是像电影《终结者》中那样的机器人?还是打败了世界冠军的下棋程序AlphaGo?还是与我们生活息息相关的自动驾驶技术、智能音箱等产品呢?

其实,上面提到的几个例子都属于人工智能的范畴。人工智能,顾名思义,就是希望机器能像人一样拥有思考能力。也正因如此,人工智能“威胁论”总是不绝于耳,那么当下的人工智能究竟发展到什么阶段了呢?
请你思考一下,以下哪些是我们现阶段可以实现的人工智能?
A. 可以用语音控制的智能音箱
B. 可以打败人类的围棋程序
C. 可以在大多数场景中实现自动驾驶的无人车
D. 可以像人类一样思考、行动的机器人
本题的答案是开放的,我更倾向于选择A和B,下面我来说说我的理由:
A选项,人类的声音被传感器接收后,从计算机角度看,这些语音信号就是一些我们可以处理的离散数值。语音识别技术在现阶段已经非常成熟,像科大讯飞公司的一些语音识别产品已经达到可以媲美人类的水平了。
B选项,下围棋这个任务其实可以转换为一个图像处理的问题,因为棋盘是固定大小的,每下一步棋后的棋盘可以看作一张图片,作为后续处理的输入数据使用,近几年人工智能的火热其实也是从AlphaGo战胜围棋世界冠军李世石开始的。
说到这,就不得不提一下人工智能发展过程中的三个阶段:计算智能、感知智能和认知智能。
在计算智能方面,计算机早就超过了人类,不必多说。
在感知智能方面,机器已经可以和人类媲美,比如上面提到的语音识别和图像处理技术都属于感知智能的范畴,目前人工智能取得的大多数成果还是属于感知智能这个阶段。
在认知智能方面,机器和人类还有巨大的差距,主要体现在思考、推理等能力上的差距。实现认知智能是人工智能的终极目标,而自然语言处理技术是实现认知智能的基石,比如上面提到的智能音箱,只识别出人类说的是什么还不够,还要能听懂并和人类进行交流,这也是我们目前所面临的巨大挑战。
此外,李开复博士也曾将人工智能分类为弱人工智能、强人工智能和超人工智能。我们现在取得的很多突破性的成果,如AlphaGo,其实都属于弱人工智能。弱人工智能也很强大,之所以说它弱,是因为它只能在特定的领域做得很好。
C选项和D选项中说的无人车和机器人,实际上属于强人工智能或超人工智能了。
可能有人会说,最近自动驾驶不是很火么,实现自动驾驶的那一天看起来似乎并不遥远啊?其实我也挺期待这一天的到来,等自动驾驶技术成熟了,我就买辆车,让它自己出去拉客赚钱。。。。。。哈哈,开个玩笑。
目前自动驾驶还处于初级阶段,即便投入应用,也是特定场景下的特定应用,比如使用无人车在特定路段送快递,我们离实现真正意义上的自动驾驶还有很长很长的路要走。
AI和机器学习的关系
说了这么多人工智能的应用,接下来我们聊一聊人工智能(AI)和机器学习(ML)的关系。
随着人工智能的火热,“机器学习”、“深度学习”等概念也随之流行起来。
人工智能涉及到的学科众多,如认知学、心理学、计算机科学、神经生物学、智能搜索、模式识别等等,探索如何实现人工智能的方式也有很多,但是在当下,机器学习无疑是实现这个宏伟目标的所有方式中最具有生命力的。
值得一提的是,在机器学习这个概念未兴起之前,这个学科一直被叫作模式识别,模式识别可以看作是机器学习的前身。
那近年来很火的深度学习又是什么呢?深度学习这个概念源于对一种经典的机器学习算法--神经网络的研究,其中“深度”指的是网络的层数很多。深度学习在语音和图像领域取得的成果要远远超过传统的算法。
小结一下,人工智能、机器学习和深度学习是包含的关系:机器学习是人工智能的一个分支,深度学习是机器学习的一个分支。
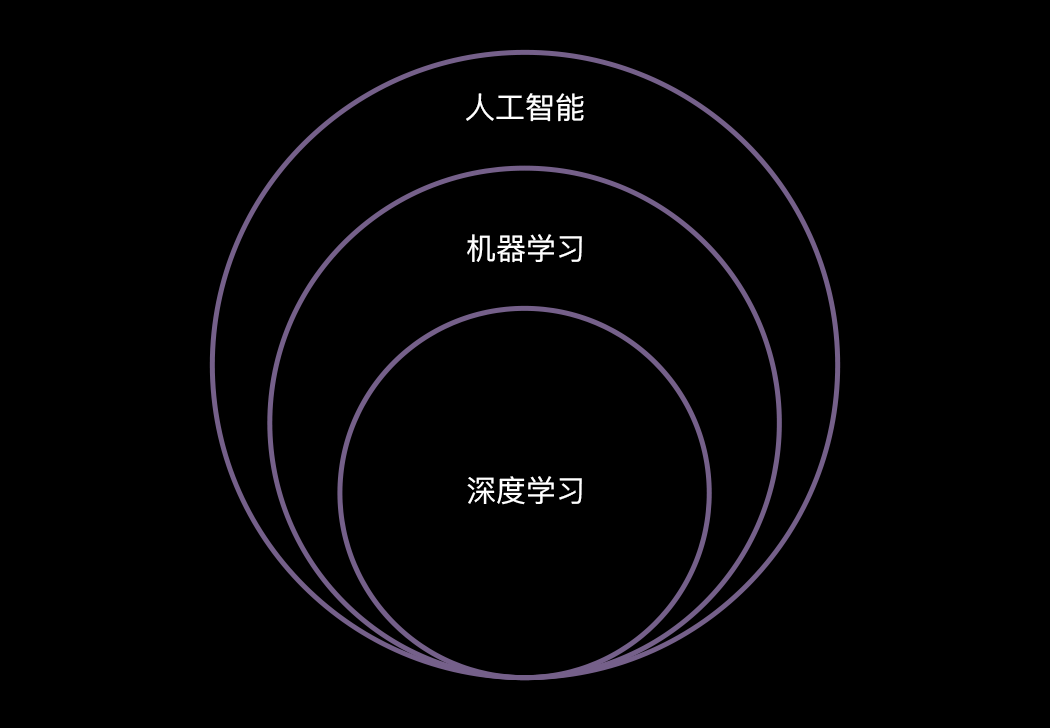
通过上面的介绍,我们知道机器学习是目前实现人工智能最核心的技术,接下来的将围绕机器学习这个概念进行详细地讲解。
在介绍机器学习是什么之前,首先思考这样一个问题:我们为什么需要机器学习?
比如:现在让你设计一个类似于微信群中抢红包的功能,这个问题是可以通过人为定义一些规则来解决的,有了规则就可以很容易地通过编程实现这个需求。
但是实际生活中还有更多问题无法通过固定的规则解决,比如如何从一张图片中识别出猫和狗?(如何去定义一只猫或狗呢?)

这个问题对于计算机来说很难,但对于人来说并非难事。机器学习作为一门研究人工智能的学科,大多数情况下面临的都是“无法通过固定规则解决”的问题。
什么是机器学习
接下来,我们就来聊一下什么是机器学习。
如果给机器学习下一个简单定义,机器学习就是让机器去学习。那么问题来了,从哪里学?学什么?怎么学?
首先回答第一个问题,机器学习是从大量的数据中进行学习。
数据的重要性就不必多说了,在互联网时代,数据可以看做是一种“新能源”。
机器学习需要的数据还必须是大量的,这和人类的学习过程是有本质区别的。通常,人类去学习一个知识点只需要几个例子(样本)就可以了,而机器学习涉及的算法模型往往需要成千上万的数据样本,甚至更多,这也是为什么现阶段我们只能实现弱人工智能。
第二个问题,机器学习学到的东西到底是什么?
笼统地说,机器学习要自动学习出一套规则,来帮助我们更好地做决策。具体来说,机器学习学到的东西是算法模型的参数,简单解释一下,算法模型就可以看作是一些数学公式,其中包含的未知数就是需要学习的参数。
最后一个问题,怎样学习得到这些参数呢?答案是训练。
了解了这三个问题之后,让我们慢慢地揭开人工智能的神秘面纱!
我们人类从出生开始,就慢慢地接触周围的人和事物,学习说话、吃饭、走路等行为。
随着年龄的增长,身体的发育,我们会进入学校学习科学文化知识,学习如何与老师、同学沟通。
从学校毕业后,我们进入社会参加工作,从工作中我们不断地学习解决问题、与人沟通的能力。
在生活中,当你看到一只不认识的小动物时,这时有人告诉你它是一只小猫,那么你就会记住长成这样的小动物是小猫。
那么你下次再见到一只长得差不多动物的时候,我们就会认出它是一只小猫。
诸如上述的这些行为,我们人类不断地从周围的人、事、物中学习,让我们具有判断能力、沟通能力等各种能力,这就是典型的经验学习的过程。

那么,要想让机器也像人类一样具有某些能力,就需要让机器模仿人类的学习过程,不断地学习锻炼,才能够逐步具备一些能力。
当然,以目前的科技发展程度,机器是不能进入学校与老师、同学进行交流学习的。
但是,可以把机器需要学习的行为抽象成大量的数据,机器从已知的大量数据中不断地学习,学习数据中蕴含的规律或者判断规则,将来把学到的规则应用到新数据上就可以做出正确的判断或者预测,这个学习的过程就是机器学习。

机器学习的应用并不是停留在实验室,实际上,在我们的生活中,机器学习早已经被大量的运用。
例如,最早的一个应用是垃圾邮件识别。
如果采用常规的方法识别垃圾邮件,我们可以针对垃圾邮件的特点(比如,特定的标题、发件地址等)编写过滤规则,把匹配规则成功的邮件标记为垃圾邮件。
这种方法的优点是实现简单,缺点是当发送垃圾邮件的人发现他发出去的邮件都被过滤掉了,那么他就会改变策略,重新编辑新的垃圾邮件,当我们发现有新的垃圾邮件后,还要继续修改过滤规则,一直这样重复下去。
所以通过编写规则过滤垃圾邮件的方法是不可取的。
那么,使用什么方法可以应对不断变化的垃圾邮件规则,减少大量的人工操作呢?
可行的方法是使用机器学习识别垃圾邮件,机器学习算法通过从大量的垃圾邮件样本数据中学习出识别垃圾邮件的模型。
当有新的垃圾邮件输入到训练好的模型时,就会将该邮件标记为垃圾邮件,即使垃圾邮件的标题、发送邮件地址等信息发生变化,机器学习算法也可以从新的数据中学到新的模型识别出垃圾邮件。
在我们的生活中,机器学习用于识别垃圾邮件只是一个很小的应用,还有很多其他的应用。
例如,人脸识别、语音翻译、车牌号识别、语音识别、金融风控、医疗诊断、天气预测、电商推荐等等。
我相信在不久的将来,还会有更多的机器学习、人工智能相关的项目落地,有更多的智能产品进入我们的生活,例如,最近两年很火的自动驾驶汽车、智能机器人等。
机器学习核心概念
那么接下来,我们来熟悉下机器学习里的一些核心概念。
我们可以把机器学习算法看做是一个什么都不知道的小孩,小孩在成长过程中需要学习各种各样的知识。例如,学习识别水果种类,如果小孩以前没有看见过水果,他是不能够区分出什么是苹果,什么是梨的。
当妈妈给他一个苹果的时候,他会问:“妈妈,这个是什么?”。

妈妈会告诉他:“这个红红的,圆圆的,吃起来甜甜的是苹果”。
小孩已经知道什么是红苹果了,有一天他又看到了一个绿苹果,就又不知道这是什么水果了,还会问他妈妈:“妈妈,这是什么?”。

妈妈会告诉他:“这也是苹果,只是它的颜色是绿色的”。小孩惊讶,原来苹果还有绿色的。下次小孩再遇到红苹果、绿苹果就都能认出来了。
通过这个生活的小场景,我们就知道,一个小孩在学习的过程中需要大量的案例做参考。那么机器学习算法最开始就是个什么都不懂的小孩,需要用大量的样例数据来训练它,让它对某个事物具有判断能力。
机器的学习过程就是模仿小孩的学习过程,机器在学习的过程中用到的大量样例数据组成一个大的数据集合,叫做样本数据集。
在机器学习中,通常会把样本数据集分成两部分:训练数据集和测试数据集。
为什么要分成两部分呢?下面由我来揭开这个谜底!
训练数据集就相当于小孩不认识苹果之前,小孩的妈妈准备一筐各种各样的苹果,妈妈通过这框苹果教会小孩识别苹果。
那么在机器学习中,要让一个算法模型具备某种判断能力,就需要用训练数据集来训练它。
所以,训练数据集的作用是:训练机器学习算法模型。
机器学习算法经过训练得到一个模型之后,非常自信的说它能够识别苹果了,光听它说还不行,我们得用测试数据测试下这个模型的预测效果。相当于一个公司在把一个产品投放到市场之前,内部做的产品测试。
用于测试算法模型效果的数据集就是测试数据集。
那么在机器学习中,一个大的数据集应该按什么样的比例划分训练数据集和测试数据集呢?
通常会将训练数据集与测试数据集按照8:2或者7:3的比例划分,在实际工作中,可以根据实际情况调整这个比值。
在机器学习中,将数据集中的一行记录称为一个样本,把样本中包含的属性称为特征(feature)。
下图是一个水果数据集的部分截图,数据集中存储了大量不同水果的属性(特征)和水果种类数据。

水果数据集中包含很多列,其中mass水果质量、width水果宽度、hight水果高度、color_score水果颜色,这四列的值以数字的形式表示,分别表示水果的不同属性,也就是这个数据集中的每个样本具有4个特征。
水果数据集中的fruit_name这列数据表示的是水果种类,fruit_label这列数据是用数字表示的水果种类,相当于水果种类编号。这两列表示水果种类的数据被称为目标变量或者标签。
机器学习算法分类
我们可以把机器学习算法看做是一个解决问题的工具,用这个工具来解决工作和生活中遇到的问题,那么机器学习都能解决什么样的问题呢?
第一类要解决的问题是分类问题,说白了就是让机器具备划分类别的能力。
计算机在大量包含各种特征和目标变量(类别)的已知样本数据集中,不断地训练算法模型,使其能够学习出正确分类规则。
当有新的数据输入时,算法模型根据已学习到的分类规则,输出预测类别。
例如,根据肿瘤大小预测是良性还是恶性肿瘤。
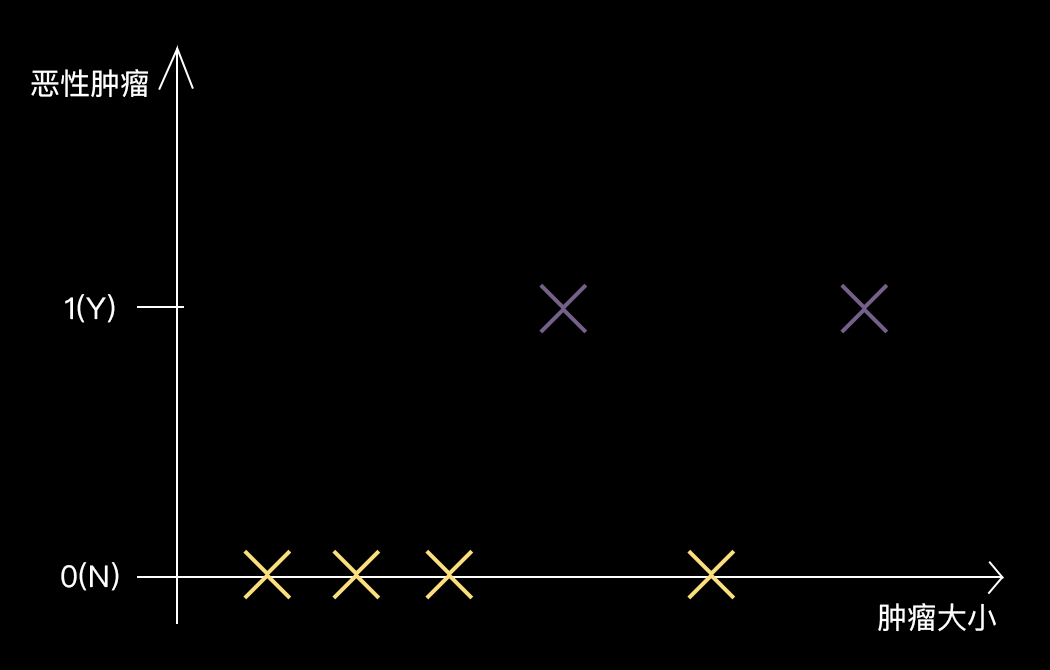
医院中存有大量肿瘤病人的病例数据,每个样本数据中包含肿瘤的大小和是否是恶性肿瘤,恶性肿瘤用1表示,良性肿瘤用0表示。
计算机根据已有的大量肿瘤数据,经过不断地训练,学习出一个肿瘤分类模型,当有新的病人来看病时,根据病人肿瘤的大小,肿瘤分类模型预测出肿瘤是否是恶性肿瘤,预测结果要么是恶性肿瘤(用数字1表示),要么是良性肿瘤(用数字0表示)。
第二类要解决的问题是回归问题,可能你会被回归这俩字搞懵,不只你懵,搁谁谁都懵!下面我来解释下。
解决回归问题与分类问题的相同点是:他们使用的数据集中的样本都包含特征和目标变量;不同点是:回归算法模型是一个连续的函数,在模型训练的过程中,模拟出一条线去拟合(尽量地去迎合^-^)数据集中不同的目标变量,这个目标变量不是固定的类别而是连续的数值。
例如,根据房屋面积预测房价。
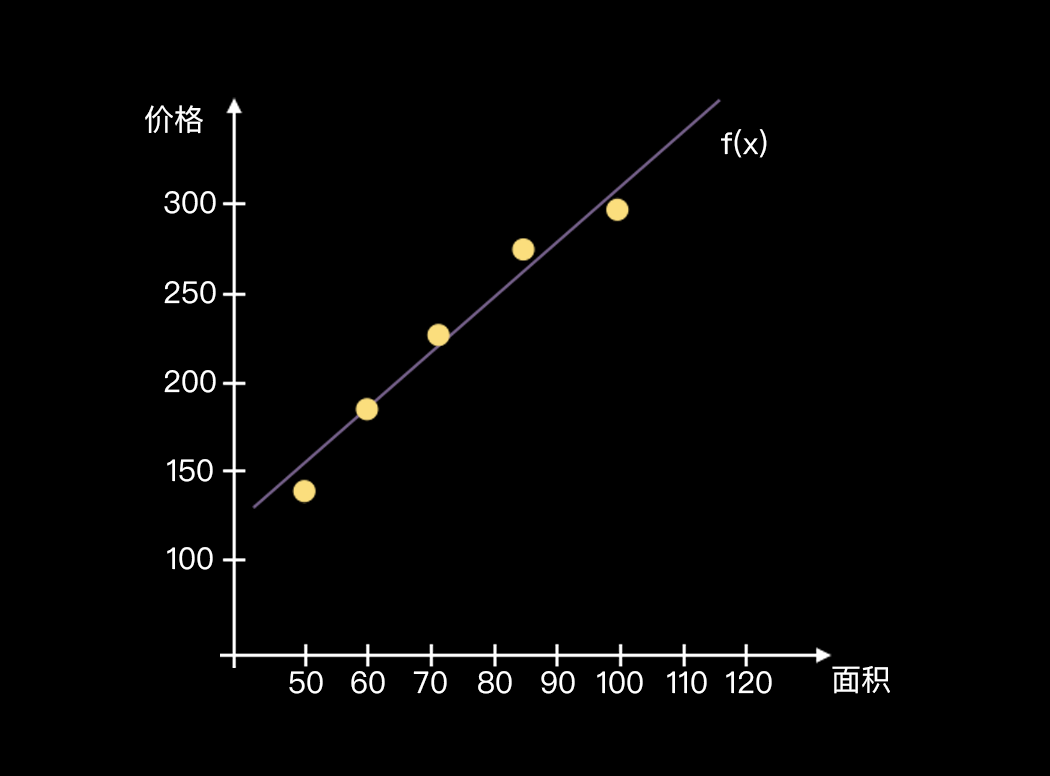
一个房产中介公司已经积累了大量的房屋销售数据,记录了不同房屋面积的出售价钱(假设忽略地理位置、房屋朝向等因素对售价的影响)。
计算机根据已有的大量房屋销售数据,经过不断地训练,学习出一个连续的函数作为预测房屋售价的模型,当有新的房子出售时,模型根据房屋的面积预测出房价作为参考售价。
第三类要解决的问题是聚类问题,聚类问题跟回归问题、分类问题有些差别。
解决聚类问题使用的是一组没有明确目标变量(标签)的样本数据集,经过不断地训练学习,分析出数据本身潜在的特征,将具有相似特征的数据聚为一类。
这有点像我们俗话说的“臭味相投”,往往具有相似特征的人是一类人群。
例如,电商平台对网购消费者进行分类。

电商平台存储了大量用户的历史消费数据,这些历史数据中不包含用户所属类别,电商平台也不知道将用户划分成多少个类别,经过对大量消费数据的分析,从数据中找到相似用户的消费特征,将具有相似特征的用户聚为一类。
之后商家可以根据用户类别制定针对性的营销方案,提升用户体验,同时提高销售额。
按照解决的问题划分可以分为:分类问题、回归问题、聚类问题。除了以这个角度划分外,还可以按照数据集中是否包含目标变量来划分。
在实际工作中,不是所有的数据集都有目标变量(标签),有些数据集只有特征数据没有标签数据。所以根据使用的样本数据集是否包含目标变量(标签),可以把机器学习分为有监督学习和无监督学习两类。
使用带有类别标签的样本数据集训练的模型属于有监督学习,例如:分类、回归。
使用不带有类别标签的样本数据集训练的模型属于无监督学习,例如:聚类。
机器学习项目开发流程
我们已经学习了很多机器学习的核心概念,那么我们再学习下开发一个机器学习项目的基本流程。
先看一张图机器学习项目开发流程图,能用图表达的事情,就不用文字表达。

根据机器学习项目开发流程图,下面开始介绍一个机器学习项目开发流程的主要步骤:
第1步:收集数据
收集数据的方法有很多种,可以从公司内部的产品数据中获取,如果内部的数据有限,最常用的方法就是使用爬虫程序自动从网上爬取相关数据。
第2步:准备数据
准备数据的过程非常重要,在实际工作中,有很大一部分时间都是在准备数据。这个过程大致包含数据处理、格式转换、特征提取等。这一步的主要目的是对数据进行规范化处理,从数据中找到有用的信息。
第3步:选择机器学习算法
根据实际任务的具体需求结合样本集选择合适的算法模型。
第4步:算法模型训练
使用训练样本集对已选好的算法模型进行训练。算法工程师在模型训练的过程中,根据经验给模型设置一些初始参数值,然后在训练集上不断地训练模型,找到最优参数解。
第5步:算法模型测试
模型训练好之后,使用测试样本集对模型进行测试,通过损失函数对预测值进行验证。
第6步:模型上线
将验证通过的算法模型发布到生产环境,对新数据进行预测。
好了,到这里我们已经掌握了机器学习领域一些核心概念和一个机器学习项目的开发流程。为我们后面的学习打下了坚实的基础!
今天我们先到这里,拜拜~
联系我们,一起学Python吧
分享Python实战代码,入门资料,进阶资料,基础语法,爬虫,数据分析,web网站,机器学习,深度学习等等。
 关注公众号「Python家庭」领取1024G整套教材、交流群学习、商务合作
关注公众号「Python家庭」领取1024G整套教材、交流群学习、商务合作