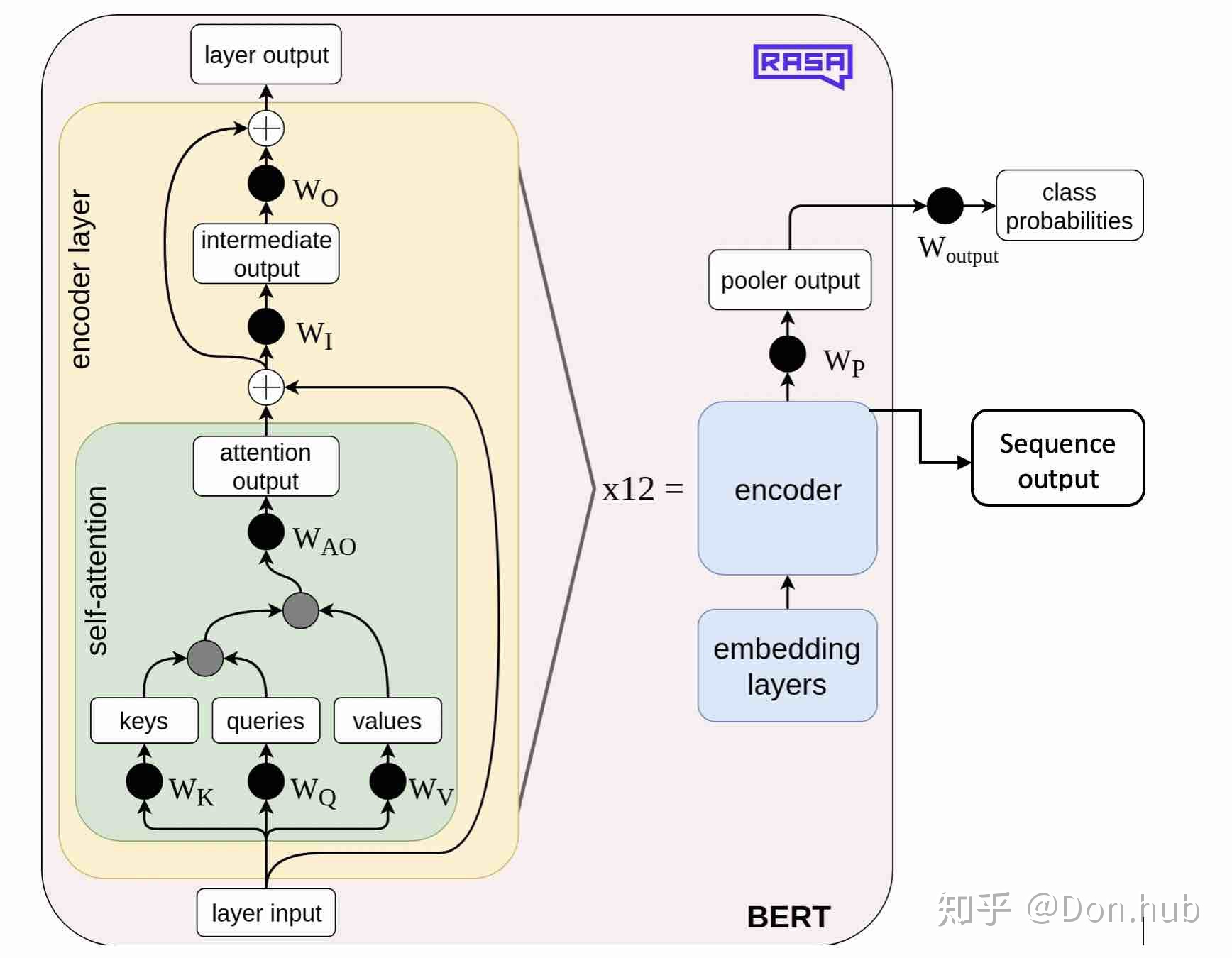
1、bert结构
2、句子token
原始输入my dog is cute;
bert的token方式有3种,basicToken, peiceToken,FullToken
3、embedding

- [CLS]: 代表的是分类任务的特殊token,它的输出就是模型的pooler output
- [SEP]:分隔符
- 其他:句子A以及句子B是模型的输入文本,其中句子B可以为空,则输入变为[CLS]+句子A
tokens.append("[CLS]")
segment_ids.append(0)
for token in tokens_a:
tokens.append(token)
segment_ids.append(0)
tokens.append("[SEP]")
segment_ids.append(0)
for token in tokens_b:
tokens.append(token)
segment_ids.append(1)
tokens.append("[SEP]")
segment_ids.append(1)(在这篇博客中,作者进行了论述https://zhuanlan.zhihu.com/p/103226488)
4、output
5、任务(MLM nsp)
MLM任务中被选15%的
for index in cand_indexes:
if len(masked_lms) >= num_to_predict: # 15% of total tokens
break
...
masked_token = None
# 80% of the time, replace with [MASK]
if rng.random() < 0.8:
masked_token = "[MASK]"
else:
# 10% of the time, keep original
if rng.random() < 0.5:
masked_token = tokens[index]
# 10% of the time, replace with random word
else:
masked_token = vocab_words[rng.randint(0, len(vocab_words) - 1)]
output_tokens[index] = masked_token参考博客
https://zhuanlan.zhihu.com/p/103226488 (80% 10% 10%mask策略的具体计算逻辑;这是我影响比较深的一段代码逻辑 )
https://zhuanlan.zhihu.com/p/156113715 (预训练模型加载和参数映射详解;这是我影响比较深的一段代码逻辑 )