目录
- Bert详解(1)—从WE、ELMO、GPT到BERT
- BERT详解(2)—源码讲解[生成预训练数据]
- BERT详解(3)—源码解读[预训练模型]
- BERT详解(4)—fine-tuning
- BERT(5)—实战[BERT+CNN文本分类]
1. 计算机视觉中的预训练
我们设计好网络结构以后,对于图像来说一般是CNN的多层叠加网络结构,可以先用某个训练集合比如训练集合A或者训练集合B对这个网络进行预先训练,在A任务上或者B任务上学会网络参数,然后存起来以备后用。假设我们面临第三个任务C,网络结构采取相同的网络结构,在比较浅的几层CNN结构,网络参数初始化的时候可以加载A任务或者B任务学习好的参数,其它CNN高层参数仍然随机初始化。之后我们用C任务的训练数据来训练网络,此时有两种做法,一种是浅层加载的参数在训练C任务过程中不动,这种方法被称为“Frozen”;另外一种是底层网络参数尽管被初始化了,在C任务训练过程中仍然随着训练的进程不断改变,这种一般叫“Fine-Tuning”,顾名思义,就是更好地把参数进行调整使得更适应当前的C任务。一般图像或者视频领域要做预训练一般都这么做
预训练的好处:
(1)若C任务的训练数据集较少,现阶段的好用的CNN比如Resnet/Densenet/Inception等网络结构层数很深,几百万上千万参数量起步,训练数据少很难很好地训练这么复杂的网络,但是如果其中大量参数通过大的训练集合比如ImageNet预先训练好直接拿来初始化大部分网络结构参数,然后再用C任务手头比较可怜的数据量上Fine-tuning过程去调整参数让它们更适合解决C任务,那事情就好办多了。这样原先训练不了的任务就能解决了,即使手头任务训练数据也不少,加个预训练过程也能极大加快任务训练的收敛速度。
为什么接上预训练就能取的好的效果?
对于层级的CNN结构来说,不同层级的神经元学习到了不同类型的图像特征,由底向上特征形成层级结构,以人脸识别为例,通过tensorboard可视化我们可以看出,最底层的神经元学到的是线段等特征,图示的第二个隐层学到的是人脸五官的轮廓,第三层学到的是人脸的轮廓,通过三步形成了特征的层级结构,越是底层的特征越是所有不论什么领域的图像都会具备的比如边角线弧线等底层基础特征,越往上抽取出的特征越与手头任务相关。正因为此,所以预训练好的网络参数,尤其是底层的网络参数抽取出特征跟具体任务越无关,越具备任务的通用性,所以这是为何一般用底层预训练好的参数初始化新任务网络参数的原因,而高层特征跟任务关联较大,实际可以不用使用,或者采用Fine-tuning用新数据集合清洗掉高层无关的特征抽取器。
总结下就是底层特征的可复用性和高层特征的任务相关性
2. NLP中的预训练----word Embedding
如下图在训练任务时得到的参数矩阵W(需要学习)其实就是每一个单词对应的word embedding值(用onehot矩阵乘该权重矩阵就是取出每个单词的词向量)
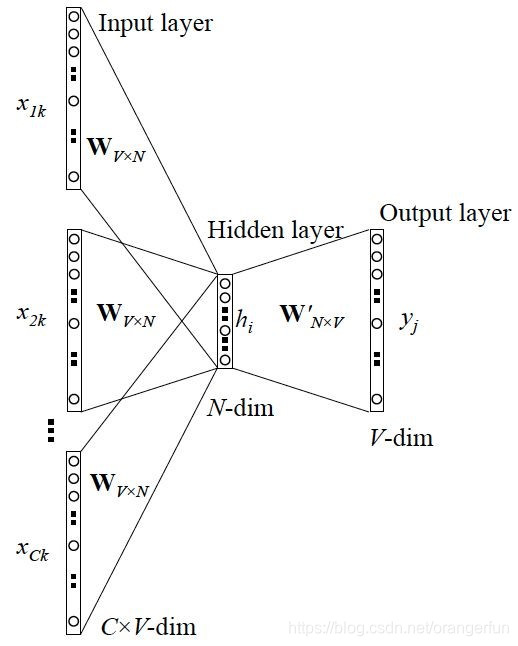
那么word embedding到底和pre-training有什么关系呢?其实这就是标准的预训练过程。被广泛应用于NLP的下游任务。
使用Word Embedding等价于把Onehot层到embedding层的网络用预训练好的参数矩阵Q初始化了。这跟前面讲的图像领域的低层预训练过程其实是一样的,区别无非Word Embedding只能初始化第一层网络参数,再高层的参数就无能为力了。下游NLP任务在使用Word Embedding的时候也类似图像有两种做法,一种是Frozen,就是Word Embedding那层网络参数固定不动;另外一种是Fine-Tuning,就是Word Embedding这层参数使用新的训练集合训练也需要跟着训练过程更新掉
word Embedding存在一词多义的问题
Word Embedding在对一个单词进行编码的时候,是区分不开这多个含义的,因为它们尽管上下文中的单词不同,但是在用语言模型训练的时候,不论上下文是什么句子经过word2vec,都是预测相同的一个单词,而同一个单词占的是同一行的参数空间,这导致两种不同的上下文信息都会编码到相同的word embedding空间里去。所以word embedding无法区分多义词的不同语义
3.从Word Embedding 到 ELMO
之前的Word Embedding本质上是个静态的方式,即训练好之后每个单词的表达就固定住了,以后使用的时候,不论新句子上下文单词是什么,这个单词的Word Embedding不会跟着上下文场景的变化而改变,所以对于比如Bank这个词,它事先学好的Word Embedding中混合了几种语义 ,在应用中来了个新句子,即使从上下文中(比如句子包含money等词)明显可以看出它代表的是“银行”的含义,但是对应的Word Embedding内容也不会变,它还是混合了多种语义。
ELMO的本质思想是:先用语言模型学好一个单词的Word Embedding,此时多义词无法区分,不过这没关系。在实际使用Word Embedding的时候,单词已经具备了特定的上下文了,这个时候我可以根据上下文单词的语义去调整单词的Word Embedding表示,这样经过调整后的Word Embedding更能表达在这个上下文中的具体含义,自然也就解决了多义词的问题了。所以ELMO本身是个根据当前上下文对Word Embedding动态调整的思路。
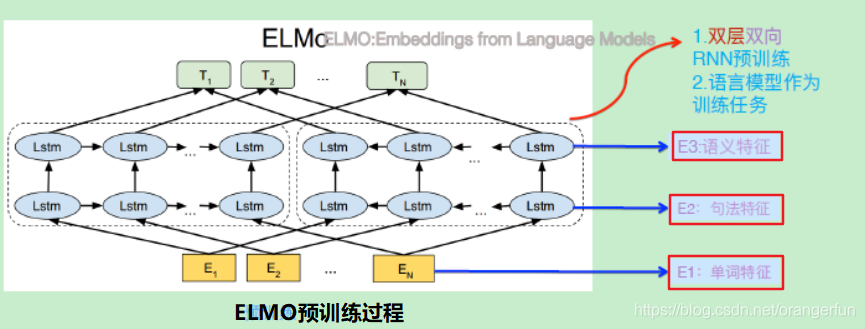
ELMO采用了典型的两阶段过程,第一个阶段是利用语言模型进行预训练;第二个阶段是在做下游任务时,从预训练网络中提取对应单词的网络各层的Word Embedding作为新特征补充到下游任务中。
ELMO的网络结构采用了双层双向LSTM,目前语言模型训练的任务目标是根据单词 Wi 的上下文去正确预测单词 Wi ,Wi 之前的单词序列Context-before称为上文,之后的单词序列Context-after称为下文。图中左端的前向双层LSTM代表正方向编码器,输入的是从左到右顺序的除了预测单词外 Wi 的上文Context-before和下文Context-after;右端的逆向双层LSTM代表反方向编码器,输入的是从右到左的逆序的句子上文和下文;每个编码器的深度都是两层LSTM叠加,而每一层的正向和逆向单词编码会拼接到一起;如下图所示
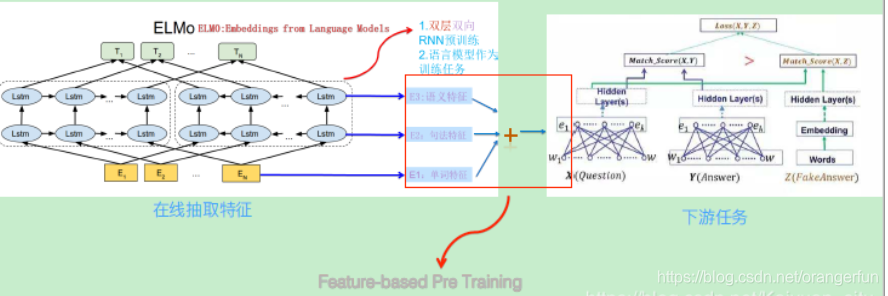
预训练好网络结构后,如何给下游任务使用呢?
下图展示了下游任务的使用过程,比如我们的下游任务仍然是QA问题,此时对于问句X,我们可以先将句子X作为预训练好的ELMO网络的输入,这样句子X中每个单词在ELMO网络中都能获得对应的三个Embedding(单词的Embedding,句法层面的Embedding,语义层面的Embedding),之后给予这三个Embedding中的每一个Embedding一个权重a,这个权重可以学习得来,根据各自权重累加求和,将三个Embedding整合成一个。然后将整合后的这个Embedding作为X句在自己任务的那个网络结构中对应单词的输入,以此作为补充的新特征给下游任务使用。对于上图所示下游任务QA中的回答句子Y来说也是如此处理。因为ELMO给下游提供的是每个单词的特征形式,所以这一类预训练的方法被称为“Feature-based Pre-Training”
ELMO也存在一些缺点
(1)特征抽取器选择方面,ELMO使用了LSTM而不是新贵Transformer;Transformer提取特征的能力是要远强于LSTM的
(2)ELMO采取双向拼接这种融合特征的能力可能比Bert一体化的融合特征方式弱,但是,这只是一种从道理推断产生的怀疑,目前并没有具体实验说明这一点。
4. 从Word Embedding到GPT
GPT也采用两阶段过程,第一个阶段是利用语言模型进行预训练,第二阶段通过Fine-tuning的模式解决下游任务。下图展示了GPT的预训练过程,其实和ELMO是类似的,主要不同在于两点:
(1)特征抽取器不是用的RNN,而是用的Transformer
(2)GPT的预训练虽然仍然是以语言模型作为目标任务,但是采用的是单向的语言模型,即根据 Wi 单词的上文去正确预测单词 Wi,而抛开了下文
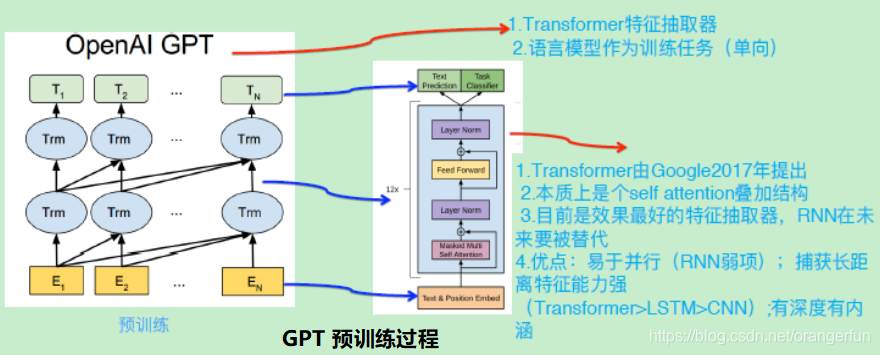
GPT下游任务的使用:
首先,对于不同的下游任务来说,本来你可以任意设计自己的网络结构,现在不行了,你要向GPT的网络结构看齐,把任务的网络结构改造成和GPT的网络结构是一样的。然后,在做下游任务的时候,利用第一步预训练好的参数初始化GPT的网络结构,这样通过预训练学到的语言学知识就被引入到你手头的任务里来,再次,你可以用手头的任务去训练这个网络,对网络参数进行Fine-tuning,使得这个网络更适合解决手头的问题。
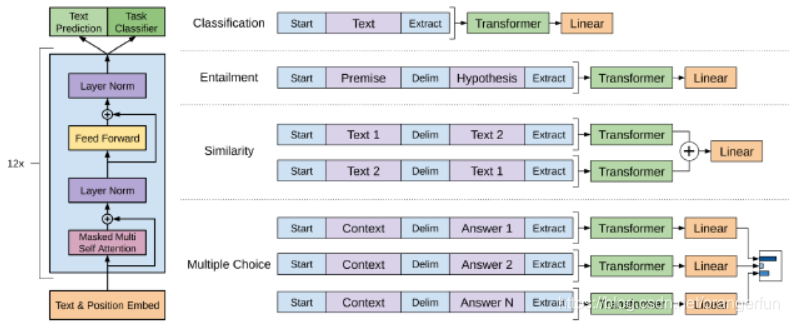
GPT如何改造下游任务?
(1)对于分类问题,不用怎么动,加上一个起始和终结符号即可;
(2)对于句子关系判断问题,比如Entailment,两个句子中间再加个分隔符即可;
(3)对文本相似性判断问题,把两个句子顺序颠倒下做出两个输入即可,这是为了告诉模型句子顺序不重要;
(4)对于多项选择问题,则多路输入,每一路把文章和答案选项拼接作为输入即可
GPT的缺点:主要的就是那个单向语言模型
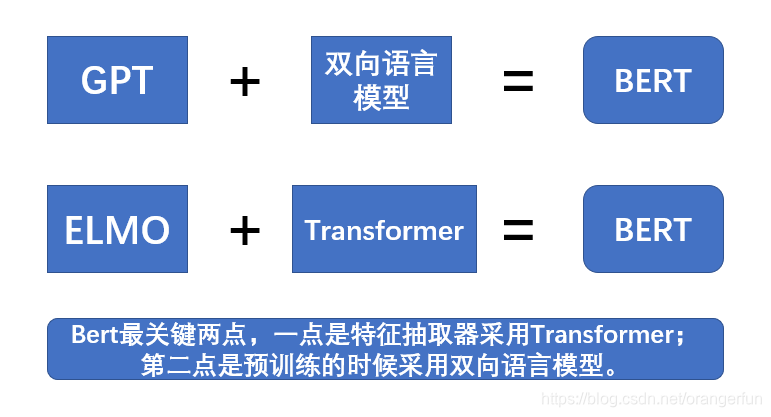
5.BERT
Bert采用和GPT完全相同的两阶段模型,首先是语言模型预训练;其次是使用Fine-Tuning模式解决下游任务。和GPT的最主要不同在于在预训练阶段采用了类似ELMO的双向语言模型,当然另外一点是语言模型的数据规模要比GPT大。
- 对于Transformer来说,怎么才能在这个结构上做双向语言模型任务呢?
作者们提出了一个叫Masked语言模型来解决这个问题,其实这跟word2vec中的CBOW模型思想很类似,它的核心思想是:在做语言模型任务的时候,我把要预测的单词抠掉,然后根据它的上文Context-Before和下文Context-after去预测单词,具体做法如下:
随机选择语料中15%的单词,把它抠掉,也就是用[Mask]掩码代替原始单词,然后要求模型去正确预测被抠掉的单词,但是这里有个问题:训练过程大量看到[mask]标记,但是真正后面用的时候是不会有这个标记的,这会引导模型认为输出是针对[mask]这个标记的,但是实际使用又见不到这个标记,这自然会有问题。为了避免这个问题,Bert改造了一下:
15%的被选中要执行[mask]替身的单词中,只有80%真正被替换成[mask]标记,10%被随机替换成另外一个单词,10%情况这个单词还待在原地不做改动
- Bert还有一个创新点叫做 Next Sentence Prediction
做语言模型预训练的时候,分两种情况选择两个句子,一种是选择语料中真正顺序相连的两个句子;另外一种是第二个句子从语料库中随机选择一个拼到第一个句子后面。我们要求模型除了做上述的Masked语言模型任务外,附带再做个句子关系预测,判断第二个句子是不是真的是第一个句子的后续句子。之所以这么做,是考虑到很多NLP任务是句子关系判断任务,单词预测粒度的训练到不了句子关系这个层级,增加这个任务有助于下游句子关系判断任务。所以可以看到,它的预训练是个多任务过程。
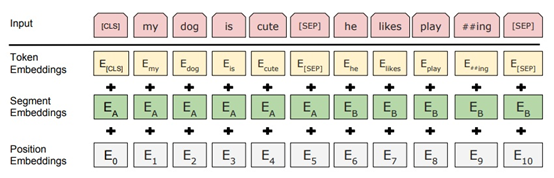
- BERT的输入部分
它的输入部分是个线性序列,两个句子通过分隔符分割,最前面和最后增加两个标识符号。每个单词有三个embedding:token嵌入、Segment嵌入和Position嵌入。
(1)token嵌入
token嵌入层的作用是将单词转换为固定维的向量表示形式。在BERT的例子中,每个单词都表示为一个768维的向量;假设输入文本是“I like strawberries”。下图描述了token嵌入层的作用
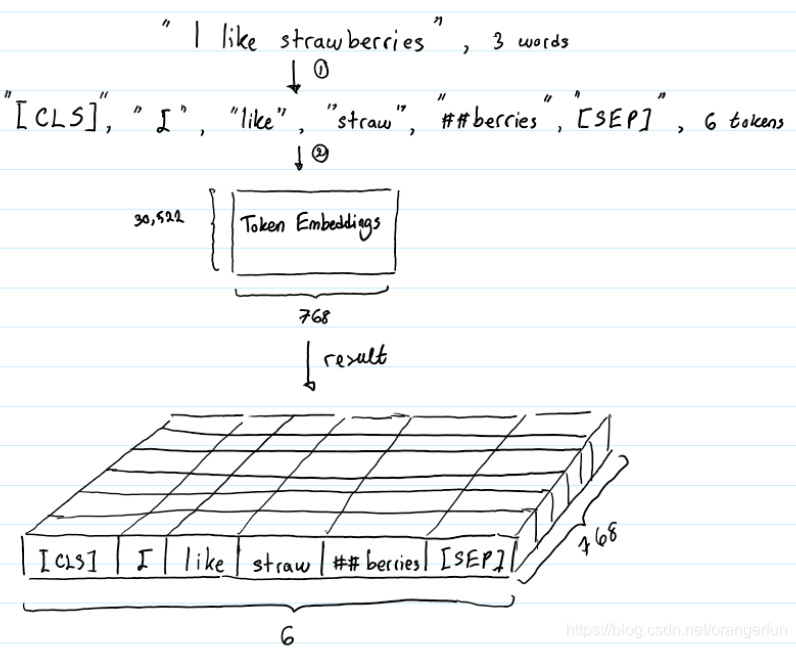
在将输入文本传递到token嵌入层之前,首先对其进行token化。另外,在tokens的开始([CLS])和结束([SEP])处添加额外的tokens。这些tokens的目的是作为分类任务的输入表示,并分别分隔一对输入文本
tokens化是使用一种叫做WordPiece token化的方法来完成的,这种方式类似BPE,可以有效解决未登录词问题,这就是“strawberries”被分成“straw”和“berries”的方式
token嵌入层将每个wordpiece token转换为768维向量表示形式。这将使得我们的6个输入token被转换成一个形状为(6,768)的矩阵,或者一个形状为(1,6,768)的张量,如果我们包括批处理维度的话。
(2)Segment嵌入
BERT能够解决包含文本分类的NLP任务。这类问题的一个例子是对两个文本在语义上是否相似进行分类。这对输入文本被简单地连接并输入到模型中。那么BERT是如何区分输入的呢?答案是Segment嵌入。
假设我们的输入文本对是(“I like cats”, “I like dogs”)。下面是Segment嵌入如何帮助BERT区分这个输入对中的tokens :
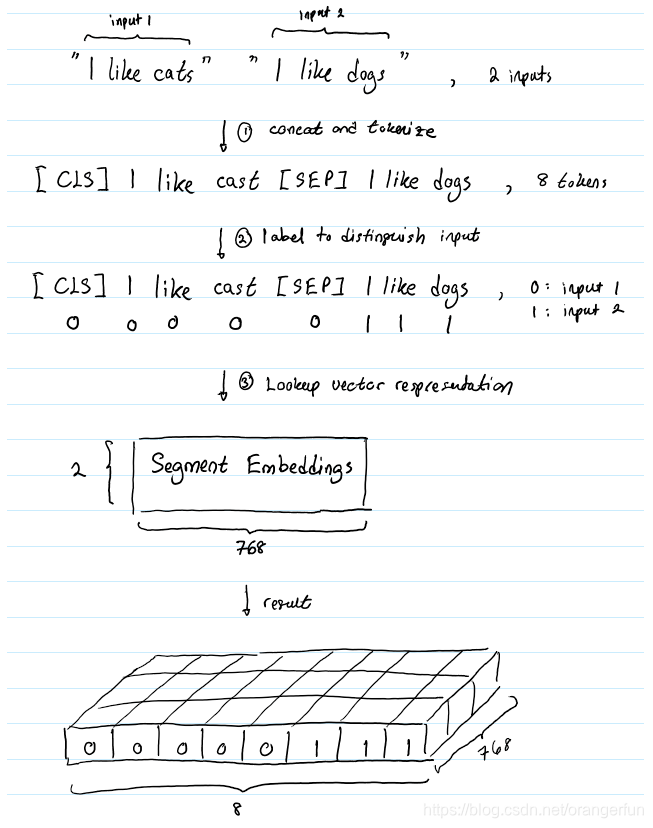
Segment嵌入层只有两个向量表示。第一个向量(索引0)分配给属于输入1的所有tokens,而最后一个向量(索引1)分配给属于输入2的所有tokens。如果一个输入只有一个输入语句,那么它的Segment嵌入就是对应于Segment嵌入表的索引为0的向量。
(3)Position嵌入
Transformers不编码其输入的顺序特征,因此要加入位置编码;BERT被设计用来处理长度为512的输入序列。作者通过让BERT学习每个位置的向量表示来包含输入序列的顺序特征。这意味着Position嵌入层是一个大小为(512,768)的查找表,其中第一行是第一个位置上的任意单词的向量表示,第二行是第二个位置上的任意单词的向量表示,等等。因此,如果我们输入“Hello world”和“Hi there”,“Hello”和“Hi”将具有相同的Position嵌入,因为它们是输入序列中的第一个单词。同样,“world”和“there”的Position嵌入是相同的
(4)总的词嵌入
长度为n的token化输入序列将有三种不同的表示,即:
- token嵌入,形状(1,n, 768),这只是词的向量表示
- Segment嵌入,形状(1,n, 768),这是向量表示,以帮助BERT区分成对的输入序列。
- Position嵌入,形状(1,n, 768),让BERT知道其输入具有时间属性。
对这些表示进行元素求和,生成一个形状为(1,n, 768)的单一表示。这是传递给BERT的编码器层的输入表示。
- Fine-Tuning阶段
这个阶段的做法和GPT是一样的。当然,它也面临着下游任务网络结构改造的问题,在改造任务方面Bert和GPT有些不同
(1)对于句子关系类任务,很简单,和GPT类似,加上一个起始和终结符号,句子之间加个分隔符即可。对于输出来说,把第一个起始符号对应的Transformer最后一层位置上面串接一个softmax分类层即可。
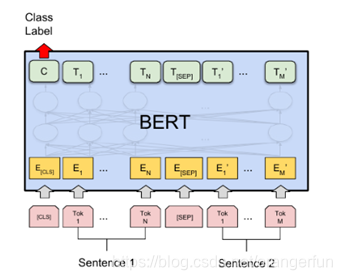
(2)对于普通的分类任务,输入是一个序列,所有的Token都是属于同一个Segment(Id=0),我们用第一个特殊Token [CLS]的最后一层输出接上softmax进行分类,用分类的数据来进行Fine-Tuning
(3)对于序列标注问题,输入部分和单句分类是一样的,只需要输出部分Transformer最后一层每个单词对应位置都进行分类即可。
6.总结
从模型或者方法角度看,Bert借鉴了ELMO,GPT及CBOW,主要提出了Masked 语言模型及Next Sentence Prediction,但是这里Next Sentence Prediction基本不影响大局,而Masked LM明显借鉴了CBOW的思想。所以说Bert的模型没什么大的创新,更像最近几年NLP重要进展的集大成者。
预训练这个过程本质上是通过设计好一个网络结构来做语言模型任务,然后把大量甚至是无穷尽的无标注的自然语言文本利用起来,预训练任务把大量语言学知识抽取出来编码到网络结构中,当手头任务带有标注信息的数据有限时,这些先验的语言学特征当然会对手头任务有极大的特征补充作用,因为当数据有限的时候,很多语言学现象是覆盖不到的,泛化能力就弱,集成尽量通用的语言学知识自然会加强模型的泛化能力