导入需要用到的机器学习库函数
import pandas as pd
import numpy as np
import warnings
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
warnings.filterwarnings('ignore')
%matplotlib inline
import itertools
import matplotlib.gridspec as gridspec
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier,RandomForestRegressor
# from mlxtend.classifier import StackingClassifier
from sklearn.model_selection import cross_val_score, train_test_split
# from mlxtend.plotting import plot_learning_curves
# from mlxtend.plotting import plot_decision_regions
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import train_test_split
import lightgbm as lgb
from sklearn.neural_network import MLPClassifier,MLPRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error
添加一个降低数据内存的函数,即将数据进行格式转换
def reduce_mem_usage(df):
start_mem = df.memory_usage().sum() / 1024**2
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype('category')
end_mem = df.memory_usage().sum() / 1024**2
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df
导入数据并查看数据类型
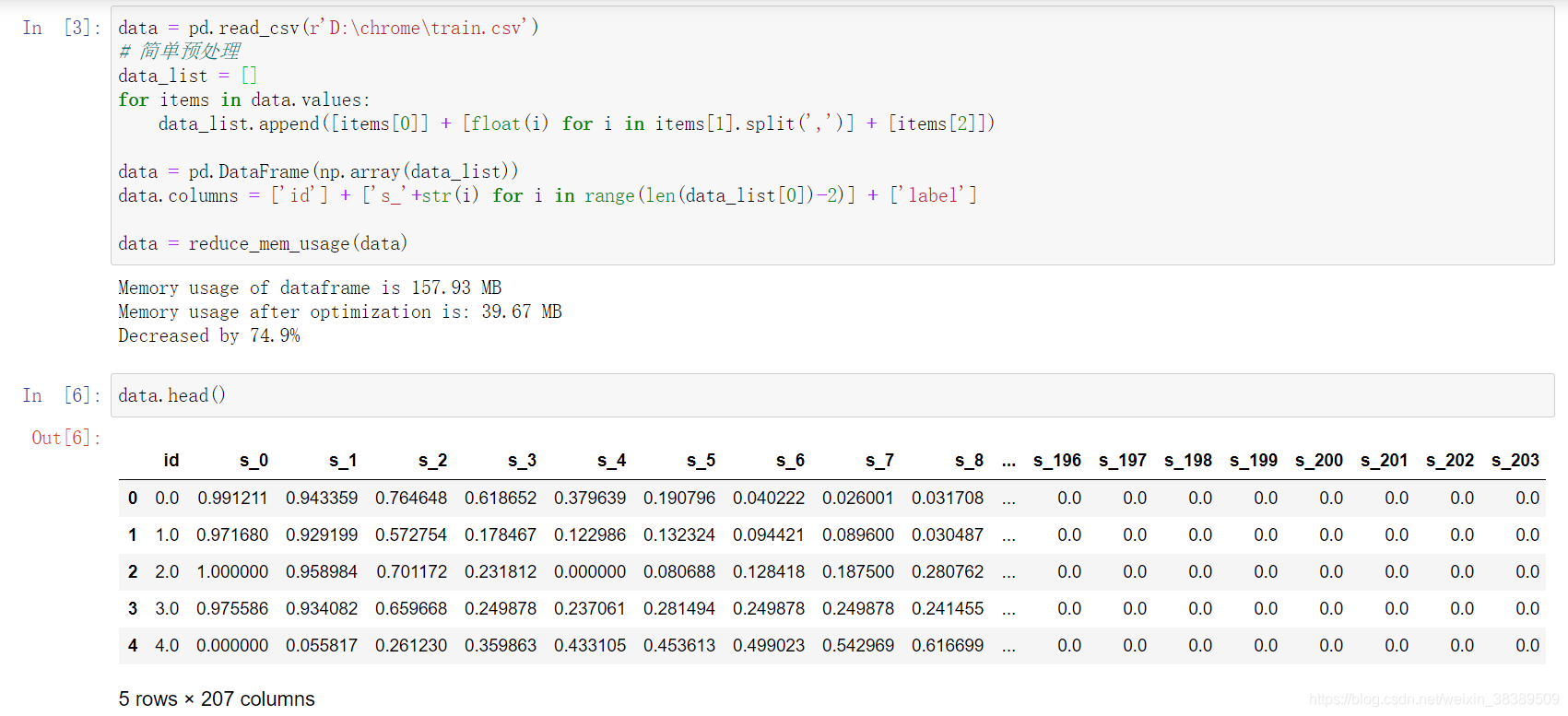 可以看到经过预处理,数据已经变成了207列数据,除去id和label,剩下的都是feature列。
可以看到经过预处理,数据已经变成了207列数据,除去id和label,剩下的都是feature列。
train = pd.read_csv('./data/train.csv')
test = pd.read_csv('./data/testA.csv')
# 简单预处理
train_list = []
for items in train.values:
train_list.append([items[0]] + [float(i) for i in items[1].split(',')] + [items[2]])
test_list = []
for items in test.values:
test_list.append([items[0]] + [float(i) for i in items[1].split(',')])
train = pd.DataFrame(np.array(train_list))
test = pd.DataFrame(np.array(test_list))
# id列不算入特征
features = ['s_'+str(i) for i in range(len(train_list[0])-2)]
train.columns = ['id'] + features + ['label']
test.columns = ['id'] + features
train = reduce_mem_usage(train)
test = reduce_mem_usage(test)
处理过之后的内存对比结果。
Memory usage of dataframe is 157.93 MB
Memory usage after optimization is: 39.67 MB
Decreased by 74.9%
Memory usage of dataframe is 31.43 MB
Memory usage after optimization is: 7.90 MB
Decreased by 74.9%
划分数据集分为训练集和测试集
# 根据8:2划分训练集和校验集
X_train = train.drop(['id','label'], axis=1)
y_train = train['label']
# 测试集
X_test = test.drop(['id'], axis=1)
# 第一次运行可以先用一个subdata,这样速度会快些
X_train = X_train.iloc[:50000,:20] #只取出前20个特征
y_train = y_train.iloc[:50000]
X_test = X_test.iloc[:,:20]
# 划分训练集和测试集
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2)
基于单个模型进行建模,这里参数都是指定的没有进行调参,预测结果可能不是很准确
# 单模函数
def build_model_rf(X_train,y_train):
model = RandomForestRegressor(n_estimators = 100)
model.fit(X_train, y_train)
return model
def build_model_lgb(X_train,y_train):
model = lgb.LGBMRegressor(num_leaves=63,learning_rate = 0.1,n_estimators = 100)
model.fit(X_train, y_train)
return model
def build_model_nn(X_train,y_train):
model = MLPRegressor(alpha=1e-05, hidden_layer_sizes=(5, 2), random_state=1,solver='lbfgs')
model.fit(X_train, y_train)
return model
利用训练数据集对模型进行训练
# 这里针对三个单模进行训练,其中subA_rf/lgb/nn都是可以提交的模型
# 单模没有进行调参,因此是弱分类器,效果可能不是很好。
print('predict rf...')
model_rf = build_model_rf(X_train,y_train)
val_rf = model_rf.predict(X_val)
subA_rf = model_rf.predict(X_test)
print('predict lgb...')
model_lgb = build_model_lgb(X_train,y_train)
val_lgb = model_lgb.predict(X_val)
subA_lgb = model_rf.predict(X_test)
print('predict NN...')
model_nn = build_model_nn(X_train,y_train)
val_nn = model_nn.predict(X_val)
subA_nn = model_rf.predict(X_test)
加权融合
首先尝试加权融合模型:
- 如果没有给权重矩阵,就是均值融合模型
- 权重矩阵可以进行自定义,这里我们是用三个单模进行融合。如果有更多需要更改矩阵size
# 加权融合模型,如果w没有变,就是均值融合
def Weighted_method(test_pre1,test_pre2,test_pre3,w=[1/3,1/3,1/3]):
Weighted_result = w[0]*pd.Series(test_pre1)+w[1]*pd.Series(test_pre2)+w[2]*pd.Series(test_pre3)
return Weighted_result
# 初始权重,可以进行自定义,这里我们随便设置一个权重
w = [0.2, 0.3, 0.5]
val_pre = Weighted_method(val_rf,val_lgb,val_nn,w)
MAE_Weighted = mean_absolute_error(y_val,val_pre)
print('MAE of Weighted of val:',MAE_Weighted)
展示用多个单模型融合成融合模型结果
## 预测数据部分
subA = Weighted_method(subA_rf,subA_lgb,subA_nn,w)
## 生成提交文件
sub = pd.DataFrame()
sub['SaleID'] = X_test.index
sub['price'] = subA
sub.to_csv('./sub_Weighted.csv',index=False)
stacking融合
## Stacking
## 第一层
train_rf_pred = model_rf.predict(X_train)
train_lgb_pred = model_lgb.predict(X_train)
train_nn_pred = model_nn.predict(X_train)
stacking_X_train = pd.DataFrame()
stacking_X_train['Method_1'] = train_rf_pred
stacking_X_train['Method_2'] = train_lgb_pred
stacking_X_train['Method_3'] = train_nn_pred
stacking_X_val = pd.DataFrame()
stacking_X_val['Method_1'] = val_rf
stacking_X_val['Method_2'] = val_lgb
stacking_X_val['Method_3'] = val_nn
stacking_X_test = pd.DataFrame()
stacking_X_test['Method_1'] = subA_rf
stacking_X_test['Method_2'] = subA_lgb
stacking_X_test['Method_3'] = subA_nn
# 第二层是用random forest
model_lr_stacking = build_model_rf(stacking_X_train,y_train)
## 训练集
train_pre_Stacking = model_lr_stacking.predict(stacking_X_train)
print('MAE of stacking:',mean_absolute_error(y_train,train_pre_Stacking))
## 验证集
val_pre_Stacking = model_lr_stacking.predict(stacking_X_val)
print('MAE of stacking:',mean_absolute_error(y_val,val_pre_Stacking))
## 预测集##
print('Predict stacking...')
subA_Stacking = model_lr_stacking.predict(stacking_X_test)
conclusion:
- 结果层面的融合,这种是最常见的融合方法,其可行的融合方法也有很多,比如根据结果的得分进行加权融合,还可以做Log,exp处理等。在做结果融合的时候。有一个很重要的条件是模型结果的得分要比较近似但结果的差异要比较大,这样的结果融合往往有比较好的效果提升。如果不满足这个条件带来的效果很低,甚至是负效果。
- 特征层面的融合,这个层面叫融合融合并不准确,主要是队伍合并后大家可以相互学习特征工程。如果我们用同种模型训练,可以把特征进行切分给不同的模型,然后在后面进行模型或者结果融合有时也能产生比较好的效果。
- 模型层面的融合,模型层面的融合可能就涉及模型的堆叠和设计,比如加stacking,部分模型的结果作为特征输入等,这些就需要多实验和思考了,基于模型层面的融合最好不同模型类型要有一定的差异,用同种模型不同的参数的收益一般是比较小的