前言
之前学到的归并、快排、堆排序等其实都可以归为比较排序,因为一定要通过数字之间的比较才知道数字的次序。对于堆排序和归并排序,时间复杂度上界都是 O(nlog(n)),对于快速排序,平均到了O(nlog(n))。
决策树
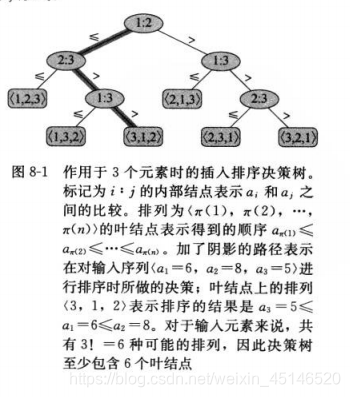
比较排序都可以抽象为像上图一样的完全二叉树。可以表示在给定输入规模的情况下,一个排序算法对所有元素的比较操作。当到达叶节点时,就确定了一个正确的排序。
根据上面的例子可以看出,当比较次数最多的时候就是到达叶子节点的时候。在最坏情况下,任何比较排序都要经历最少nlog(n)次比较。
可以看算法导论的证明:

线性时间排序
回到正题,今天看三种线性排序算法,再与排序算法对比。
计数排序
计数排序假设输入元素的每一个都是在 0 到 k 区间内的一个整数,其中k为某个整数。当k为O(n)时,排序运行时间为O(n)。
思想: 对于每一个输入的数,确认有多少数比它要小,知道这个信息后,自然而然就能将它放在合适的位置上了。
在计数排序算法中,我们会接触到 3个数组,一个数组 A[1…n],A.length=n ,另外还需要两个数组:B[1…n]存放排序的输出,C[0…k]提供临时储存空间。
//这里我理解的k是数组最大值
COUNTING-SORT(A,B,k)
//初始化临时数组C
let C[0..k] be a new array
for i=0 to k
C[i] = 0
//对A中每个元素计数
for j=1 to A.length
C[A[j]]++
//关键!计算出每个数最后的下标
for i=1 to k
C[i] = C[i-1]+C[i]
//将元素记录到B中
for i=A.length downto 1
B[C[A[j]]] = A[j]
C[A[j]]--
大概过程
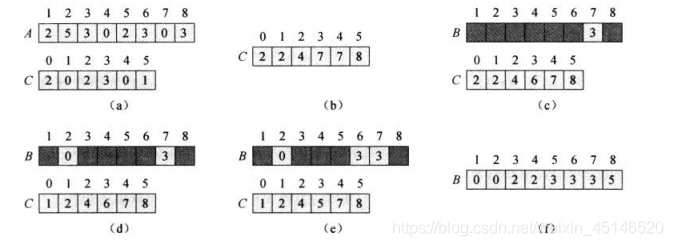
时间代价:O(k+n),在实际情况下,当 k=O(n) 时我们通常考虑这个方法。
基数排序
基数排序理解起来怪怪的,其实是对一个n位数字或字符串的每一位都进行一次排序,又或者一个日期,先对日排序、在对月排序、最后对年排序。
例子

所以说,基数排序可以用来对有多个关键字域的记录进行排序。
RADIX-SORT(A,d)
for i=1 to d
use a stable sort to sort A on digit i //用别的排序排序这个位
如果稳定排序耗时为 O(n+k),则基数排序耗时 O( d(n+k) )。
桶排序
桶排序(bucket sort)假设输入数据均匀分布,平均情况下它的时间代价为O(n)。与计数排序类似,对输入数据做了某种假设,因此桶排序速度也很快。
假设
计数排序:输入都属于一个小区间内的整数。
桶排序:输入是由一个随机过程产生,该过程将元素均匀、独立地分布在 [0,1)区间上。
思想
桶排序将[0,1) 区间划分为 n 个大小相同的子区间,例如 [0,1)、[1,2)…[8,9)等,这些子区间分为各个桶。因为输入数据均匀,所以不会出现很多数据落在同一个桶上的情况。
例子
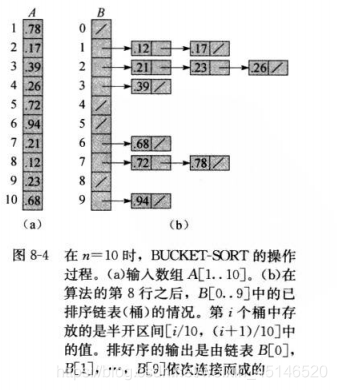
BUCKET-SORT(A)
n = A.length
let B[0...n-1] be a new array
for i=0 to n-1
make B[i] an empty list
for i=1 to n
insert A[i] into list B[func(nA[i])]//找到合适的桶插进去,func表示计算方法
for i=0 to n-1
sort list B[i] with insertion sort
//联和这些桶
concatenate the lists B[0]、B[1]、...、B[n-1] together in order
虽然用上了插入排序,但是期望运行时间依然是 O(n)。感兴趣的话算法导论有解释。
(不太懂为啥用了插入排序那桶排序怎么就不是比较排序了)
参考书籍
《算法导论》第三版