BIRCH(BalancedIterative Reducing and Clustering Using Hierarchies)全称是:利用层次方法的平衡迭代规约和聚类。BIRCH算法是1996年由TianZhang提出来的。Birch算法就是通过聚类特征(CF)形成一个聚类特征树,root层的CF个数就是聚类个数。
BIRCH算法实现分为4个步骤:
1、扫描所有数据,建立初始化的CF树,把稠密数据分成簇,稀疏数据作为孤立点对待。
2、这个步骤是可选的,步骤3的全局或半全局聚类算法有着输入范围的要求,以达到速度与质量的要求,所以此阶段在步骤1的基础上,建立一个更小的CF树。
3、 补救由于输入顺序和页面大小带来的分裂,使用全局/半全局算法对全部叶节点进行聚类。
4、 这个步骤也是可选的,把步骤3的中心点作为种子,将数据点重新分配到最近的种子上,保证重复数据分到同一个簇中,同时添加簇标签。
聚类特征(CF):每一个CF都是一个三元组,可以用(N,LS,SS)表示。其中N代表了这个CF中拥有的样本点的数量;LS代表了这个CF中拥有的样本点各特征维度的和向量,SS代表了这个CF中拥有的样本点各特征维度的平方和。
比如:CF中含有N=5个点,以两维样本点值为:(3,4)、(2,6)、(4,5)、(4,7)、(3,8)。
然后计算:
LS=(3+2+4+4+3,4+6+5+7+8)=(16,30)
SS=(32+22+42+42+32,42+62+52+72+82)=(54,190)
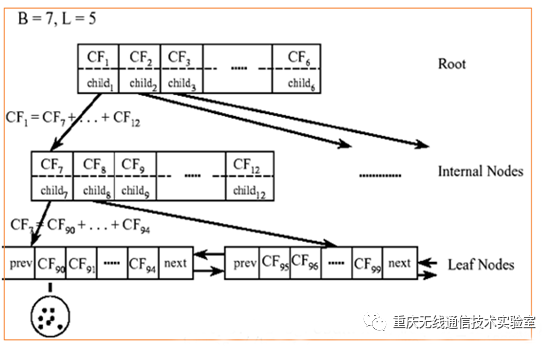
对于上图中的CF Tree,限定了B=7,L=5,也就是说内部节点最多有7个CF(含有的分支点数目),而叶子节点最多有5个CF(每个叶子还有的CF个数,实际上就是每个叶子中包含的样本数目)。叶子节点是通过双向链表连通的。
BIRCH算法举例:
Birch算法在sklearn.cluster中
具体代码如下
#coding = utf-8
##算法涉及主要参数
##n_clusters:簇数
##threshold :扫描阈值
##branches_factors: 每个节点中CF子集群的最大数量,默认值为50
##最后通过读取:label_;来获知每个数据点的分类情况
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets.samples_generator import make_blobs
from sklearn.cluster import Birch
## X为样本特征,Y为样本簇类别,共500个样本,每个样本2个特征,共4个簇,
## 簇中心在[-1,-1],[0,0],[1,1],[2,2]
X,Y = make_blobs(n_samples = 500,n_features = 2,
centers=[[-1,-1],[0,0],[1,1],[2,2]],
cluster_std=[0.5,0.4,0.5,0.4],random_state=9)
##设置birch函数
birch = Birch(n_clusters = None)
##训练数据
y_pred = birch.fit_predict(X)
##绘图
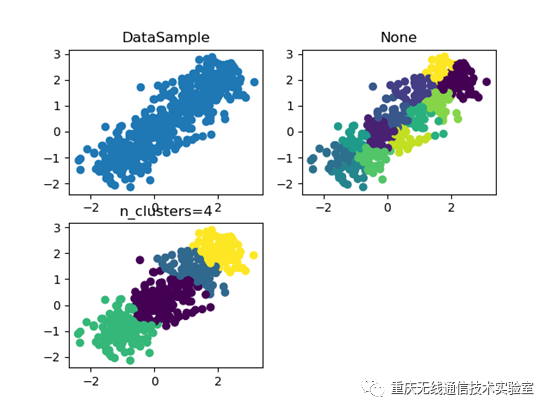
plt.figure()
plt.subplot(2,2,1)
plt.scatter(X[:,0],X[:,1])
plt.title('DataSample')
plt.subplot(2,2,2)
plt.scatter(X[:,0],X[:,1],c=y_pred)
plt.title('None')
##设置birch函数
birch =Birch(n_clusters = 4)
##训练数据
y_pred =birch.fit_predict(X)
plt.subplot(2,2,3)
plt.scatter(X[:,0], X[:, 1], c=y_pred)
plt.title('n_clusters=4')
plt.show()
最后的效果: