Netty编解码器
在了解Netty编解码之前,先了解Java的编解码:
- 编码(Encode)称为序列化, 它将对象序列化为字节数组,用于网络传输、数据持久化或者其它用途。
- 解码(Decode)称为反序列化,它把从网络、磁盘等读取的字节数组还原成原始对象(通常是原始对象的拷贝),以方便后续的业务逻辑操作。
java序列化对象只需要实现java.io.Serializable接口并生成序列化ID,这个类就能够通过java.io.ObjectInput和java.io.ObjectOutput序列化和反序列化。
Java序列化目的:1.网络传输。2.对象持久化。
Java序列化缺点:1.无法跨语言。 2.序列化后码流太大。3.序列化性能太低。
Java序列化仅仅是Java编解码技术的一种,由于它的种种缺陷,衍生出了多种编解码技术和框架,这些编解码框架实现消息的高效序列化。
下面我们来了解下Netty自己的编解码器。
一,概念
在网络应用中需要实现某种编解码器,将原始字节数据与自定义的消息对象进行互相转换。网络中都是以字节码的数据形式来传输数据的,服务器编码数据后发送到客户端,客户端需要对数据进行解码。
netty提供了强大的编解码器框架,使得我们编写自定义的编解码器很容易,也容易封装重用。对于Netty而言,编解码器由两部分组成:编码器、解码器。
- 解码器:负责将消息从字节或其他序列形式转成指定的消息对象。
- 编码器:将消息对象转成字节或其他序列形式在网络上传输。
Netty 的编(解)码器实现了 ChannelHandlerAdapter,也是一种特殊的 ChannelHandler,所以依赖于 ChannelPipeline,可以将多个编(解)码器链接在一起,以实现复杂的转换逻辑。
Netty里面的编解码: 解码器:负责处理“入站 InboundHandler”数据。 编码器:负责“出站 OutboundHandler” 数据。
二,解码器
解码器负责 解码“入站”数据从一种格式到另一种格式,解码器处理入站数据是抽象ChannelInboundHandler的实现。实践中使用解码器很简单,就是将入站数据转换格式后传递到ChannelPipeline中的下一个ChannelInboundHandler进行处理;这样的处理时很灵活的,我们可以将解码器放在ChannelPipeline中,重用逻辑。

对于解码器,Netty中主要提供了抽象基类ByteToMessageDecoder和MessageToMessageDecoder
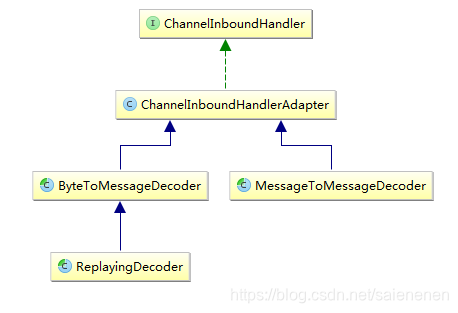
抽象解码器
- ByteToMessageDecoder: 用于将字节转为消息,需要检查缓冲区是否有足够的字节
- ReplayingDecoder: 继承ByteToMessageDecoder,不需要检查缓冲区是否有足够的字节,但是 ReplayingDecoder速度略慢于ByteToMessageDecoder,同时不是所有的ByteBuf都支持。(选择:项目复杂性高则使用ReplayingDecoder,否则使用 ByteToMessageDecoder)
- MessageToMessageDecoder: 用于从一种消息解码为另外一种消息(例如POJO到POJO)
1,ByteToMessageDecoder解码器
用于将接收到的二进制数据(Byte)解码,得到完整的请求报文(Message)。
ByteToMessageDecoder是一种ChannelInboundHandler,可以称为解码器,负责将byte字节流住(ByteBuf)转换成一种Message,Message是应用可以自己定义的一种Java对象。
下面列出了ByteToMessageDecoder两个主要方法:
protected abstract void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out)//这个方法是唯一的一个需要自己实现的抽象方法,作用是将ByteBuf数据解码成其他形式的数据。
decodeLast(ChannelHandlerContext, ByteBuf, List<Object>),//实际上调用的是decode(...)。
参数的作用如下:
- Bytubuf:需要解码的二进制数据
- List:解码后的有效报文列表,我们需要将解码后的报文添加到这个List中。之所以使用一个List表示,是因为考虑到粘包问题,因此入参的in中可能包含多个有效报文。
当然,也有可能发生了拆包,in中包含的数据还不足以构成一个有效报文,此时不往List中添加元素即可。
另外特别要注意的是,在解码时,不能直接调用ByteBuf的readXXX方法来读取数据,而是应该首先要判断能否构成一个有效的报文。
案例,假设协议规定传输的数据都是int类型的整数
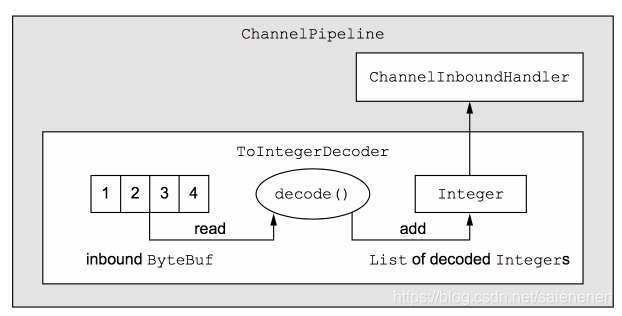
上图中显式输入的ByteBuf中包含4个字节,每个字节的值分别为:1,2,3,4。我们自定义一个ToIntegerDecoder进行解码,尽管这里我看到了4个字节刚好可以构成一个int类型整数,但是在真正解码之前,我们并不知道ByteBuf包含的字节数能否构成完成的有效报文,因此需要首先判断ByteBuf中剩余可读的字节,是否大于等于4,如下:
public class ToIntegerDecoder extends ByteToMessageDecoder {
@Override
public void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
if (in.readableBytes() >= 4) {
out.add(in.readInt());
} }
}
只有在可读字节数>=4的情况下,我们才进行解码,即读取一个int,并添加到List中。
在可读字节数小于4的情况下,我们并没有做任何处理,假设剩余可读字节数为3,不足以构成1个int。那么父类ByteToMessageDecoder发现这次解码List中的元素没有变化,则会对in中的剩余3个字节进行缓存,等待下1个字节的到来,之后再回到调用ToIntegerDecoder的decode方法。
另外需要注意: 在ToIntegerDecoder的decode方法中,每次最多只读取一个1个int。如果ByteBuf中的字节数很多,例如为16,那么可以构成4个int,而这里只读取了1个int,那么剩余12字节怎么办?这个其实不用担心,ByteToMessageDecoder再每次回调子类的decode方法之后,都会判断输入的ByteBuf中是否还有剩余字节可读,如果还有,会再次回调子类的decode方法,直到某个回调decode方法List中的元素个数没有变化时才停止,元素个数没有变化,实际上意味着子类已经没有办法从剩余的字节中读取一个有效报文。
由于存在剩余可读字节时,ByteToMessageDecoder会自动再次回调子类decode方法,因此笔者建议在实现ByteToMessageDecoder时,decode方法每次只解析一个有效报文即可,没有必要一次全部解析出来。
ByteToMessageDecoder提供的一些常见的实现类:
- FixedLengthFrameDecoder:定长协议解码器,我们可以指定固定的字节数算一个完整的报文
- LineBasedFrameDecoder: 行分隔符解码器,遇到\n或者\r\n,则认为是一个完整的报文
- DelimiterBasedFrameDecoder: 分隔符解码器,与LineBasedFrameDecoder类似,只不过分隔符可以自己指定
- LengthFieldBasedFrameDecoder:长度编码解码器,将报文划分为报文头/报文体,根据报文头中的Length字段确定报文体的长度,因此报文提的长度是可变的
- JsonObjectDecoder:json格式解码器,当检测到匹配数量的"{" 、”}”或”[””]”时,则认为是一个完整的json对象或者json数组。
- HttpObjectDecoder:一个HTTP数据的解码器
这些实现类,都只是将接收到的二进制数据,解码成包含完整报文信息的ByteBuf实例后,就直接交给了之后的ChannelInboundHandler处理。
2、ReplayingDecoder 解码器
ReplayingDecoder是byte-to-message解码的一种特殊的抽象基类,byte-to-message解码读取缓冲区的数据之前需要检查缓冲区是否有足够的字节,使用ReplayingDecoder就无需自己检查;若ByteBuf中有足够的字节,则会正常读取;若没有足够的字节则会停止解码。
也正因为这样的包装使得ReplayingDecoder带有一定的局限性。
- 不是所有的操作都被ByteBuf支持,如果调用一个不支持的操作会抛出DecoderException
- ByteBuf.readableBytes()大部分时间不会返回期望值
如果你能忍受上面列出的限制,相比ByteToMessageDecoder,你可能更喜欢ReplayingDecoder。在满足需求的情况下推荐使用ByteToMessageDecoder,因为它的处理比较简单,没有ReplayingDecoder实现的那么复杂。ReplayingDecoder继承于ByteToMessageDecoder,所以他们提供的接口是相同的。下面代码是ReplayingDecoder的实现:
public class ToIntegerReplayingDecoder extends ReplayingDecoder<Void> {
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
out.add(in.readInt());
}
}
3、MessageToMessageDecoder
ByteToMessageDecoder是将二进制流进行解码后,得到有效报文。而MessageToMessageDecoder则是将一个本身就包含完整报文信息的对象转换成另一个Java对象。
举例: 前面介绍了ByteToMessageDecoder的部分子类解码后,会直接将包含了报文完整信息的ByteBuf实例交由之后的ChannelInboundHandler处理,此时,你可以在ChannelPipeline中,再添加一个MessageToMessageDecoder,将ByteBuf中的信息解析后封装到Java对象中,简化之后的ChannelInboundHandler的操作。
另外:一些场景下,有可能你的报文信息已经封装到了Java对象中,但是还要继续转成另外的Java对象,因此一个MessageToMessageDecoder后面可能还跟着另一个MessageToMessageDecoder。一个比较容易的理解的类比案例是Java Web编程,通常客户端浏览器发送过来的二进制数据,已经被web容器(如tomcat)解析成了一个HttpServletRequest对象,但是我们还是需要将HttpServletRequest中的数据提取出来,封装成我们自己的POJO类,也就是从一个Java对象(HttpServletRequest)转换成另一个Java对象(我们的POJO类)。
MessageToMessageDecoder的类声明如下:
/**
* 其中泛型参数I表示我们要解码的消息类型。例前面,我们在ToIntegerDecoder中,把二进制字节流转换成了一个int类型的整数。
*/
public abstract class MessageToMessageDecoder<I> extends ChannelInboundHandlerAdapter
类似的,MessageToMessageDecoder也有一个decode方法需要覆盖 ,如下:
/**
* 参数msg,需要进行解码的参数。例如ByteToMessageDecoder解码后的得到的包含完整报文信息ByteBuf
* List<Object> out参数:将msg经过解析后得到的java对象,添加到放到List<Object> out中
*/
protected abstract void decode(ChannelHandlerContext ctx, I msg, List<Object> out) throws Exception;
例如,现在我们想编写一个IntegerToStringDecoder,把前面编写的ToIntegerDecoder输出的int参数转换成字符串,此时泛型I就应该是Integer类型。
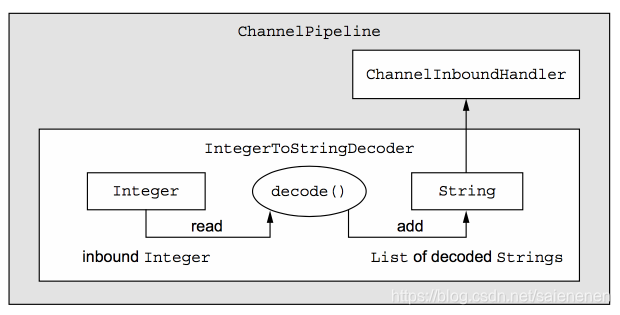
public class IntegerToStringDecoder extends MessageToMessageDecoder<Integer> {
@Override
public void decode(ChannelHandlerContext ctx, Integer msg List<Object> out) throws Exception {
out.add(String.valueOf(msg));
}
}
此时我们应该按照如下顺序组织ChannelPipieline中ToIntegerDecoder和IntegerToStringDecoder 的关系:
ChannelPipieline ch=....
ch.addLast(new ToIntegerDecoder());
ch.addLast(new IntegerToStringDecoder());
也就是说,前一个ChannelInboudHandler输出的参数类型,就是后一个ChannelInboudHandler的输入类型。
特别注意,如果我们指定MessageToMessageDecoder的泛型参数为ByteBuf,表示其可以直接针对ByteBuf进行解码,那么其是否能替代ByteToMessageDecoder呢?
答案是不可以的。因为ByteToMessageDecoder除了进行解码,还要会对不足以构成一个完整数据的报文拆包数据(拆包)进行缓存。而MessageToMessageDecoder则没有这样的逻辑。
因此通常的使用建议是,使用一个ByteToMessageDecoder进行粘包、拆包处理,得到完整的有效报文的ByteBuf实例,然后交由之后的一个或者多个MessageToMessageDecoder对ByteBuf实例中的数据进行解析,转换成POJO类。
三,编码器(Encoder)
与ByteToMessageDecoder和MessageToMessageDecoder相对应,Netty提供了对应的编码器实现MessageToByteEncoder和MessageToMessageEncoder,二者都实现ChannelOutboundHandler接口。
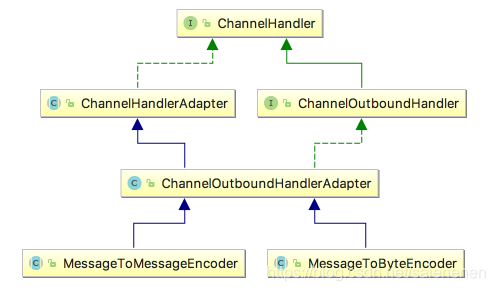
相对来说,编码器比解码器的实现要更加简单,原因在于解码器除了要按照协议解析数据,还要要处理粘包、拆包问题;而编码器只要将数据转换成协议规定的二进制格式发送即可。
1、抽象类MessageToByteEncoder
MessageToByteEncoder也是一个泛型类,泛型参数I表示将需要编码的对象的类型,编码的结果是将信息转换成二进制流放入ByteBuf中。子类通过覆写其抽象方法encode来实现编码,如下所示:
public abstract class MessageToByteEncoder<I> extends ChannelOutboundHandlerAdapter {
....
protected abstract void encode(ChannelHandlerContext ctx, I msg, ByteBuf out) throws Exception;
}
可以看到,MessageToByteEncoder的输出对象out是一个ByteBuf实例,我们应该将泛型参数msg包含的信息写入到这个out对象中。
MessageToByteEncoder使用案例:
public class IntegerToByteEncoder extends MessageToByteEncoder<Integer> {
@Override
protected void encode(ChannelHandlerContext ctx, Integer msg, ByteBuf out) throws Exception {
out.writeInt(msg);//将Integer转成二进制字节流写入ByteBuf中
}
}
2、抽象类MessageToMessageEncoder
MessageToMessageEncoder同样是一个泛型类,泛型参数I表示将需要编码的对象的类型,编码的结果是将信息放到一个List中。子类通过覆写其抽象方法encode,来实现编码,如下所示:
public abstract class MessageToMessageEncoder<I> extends ChannelOutboundHandlerAdapter {
...
protected abstract void encode(ChannelHandlerContext ctx, I msg, List<Object> out) throws Exception;
...
}
与MessageToByteEncoder不同的,MessageToMessageEncoder编码后的结果放到的out参数类型是一个List中。例如,你一次发送2个报文,因此msg参数中实际上包含了2个报文,因此应该解码出两个报文对象放到List中。
MessageToMessageEncoder提供的常见子类包括:
- LineEncoder:按行编码,给定一个CharSequence(如String),在其之后添加换行符\n或者\r\n,并封装到ByteBuf进行输出,与LineBasedFrameDecoder相对应。
- Base64Encoder:给定一个ByteBuf,得到对其包含的二进制数据进行Base64编码后的新的ByteBuf进行输出,与Base64Decoder相对应
- LengthFieldPrepender:给定一个ByteBuf,为其添加报文头Length字段,得到一个新的ByteBuf进行输出。Length字段表示报文长度,与LengthFieldBasedFrameDecoder相对应。
- StringEncoder:给定一个CharSequence(如:StringBuilder、StringBuffer、String等),将其转换成ByteBuf进行输出,与StringDecoder对应
- HttpObjectEncoder
这些MessageToMessageEncoder实现类最终输出的都是ByteBuf,因为最终在网络上传输的都要是二进制数据。
四、编码解码器Codec
编码解码器: 同时具有编码与解码功能,特点同时实现了ChannelInboundHandler和ChannelOutboundHandler接口,因此在数据输入和输出时都能进行处理。
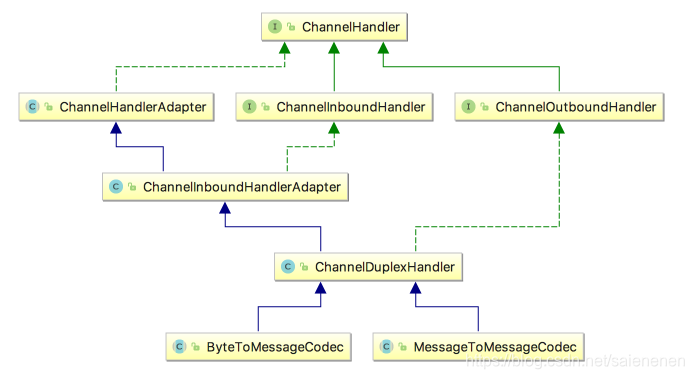
Netty提供提供了一个ChannelDuplexHandler适配器类,编码解码器的抽象基类 ByteToMessageCodec 、MessageToMessageCodec都继承与此类,如下:
ByteToMessageCodec内部维护了一个ByteToMessageDecoder和一个MessageToByteEncoder实例,可以认为是二者的功集合,泛型参数I是接受的编码类型:
public abstract class ByteToMessageCodec<I> extends ChannelDuplexHandler {
private final TypeParameterMatcher outboundMsgMatcher;
private final MessageToByteEncoder<I> encoder;
private final ByteToMessageDecoder decoder = new ByteToMessageDecoder(){
…}
...
protected abstract void encode(ChannelHandlerContext ctx, I msg, ByteBuf out) throws Exception;
protected abstract void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception;
...
}
MessageToMessageCodec内部维护了一个MessageToMessageDecoder和一个MessageToMessageEncoder实例,可以认为是二者的功集合,泛型参数
INBOUND_IN和OUTBOUND_IN分别表示需要解码和编码的数据类型。
public abstract class MessageToMessageCodec<INBOUND_IN, OUTBOUND_IN> extends ChannelDuplexHandler {
private final MessageToMessageEncoder<Object> encoder= ...
private final MessageToMessageDecoder<Object> decoder =…
...
protected abstract void encode(ChannelHandlerContext ctx, OUTBOUND_IN msg, List<Object> out) throws Exception;
protected abstract void decode(ChannelHandlerContext ctx, INBOUND_IN msg, List<Object> out) throws Exception;
}