Tensilica 是一个迅速成长的公司,公司主要产品是在专业性应用程序微处理器上,为现今高容量嵌入式系统提供最优良的解决方案。公司成立于1997年7月,该公司的投资者包括三家声名卓著的创投公司:Oak Investment Partners, Worldview Technology Partners 和 Foundation Capital, 与高科技电子业内著名的五家公司:Cisco Systems,Inc,Matsushita Electric Industrial Company Ltd, Altera Corporation,NEC Corporation 和 Conexant Systems。Tensilica的创始人为Chris Rowen,同时也是第一任CEO,他原来曾任职于Intel,Stanford,MIPS,SGI和Synopsys,同时他也是可重构处理思想的提出者和实践者。Tensilica公司创立的目的则是提供一种可以实现可重构的、核基于ASIC的、拥有对应软件开发工具的专用微处理器解决方法。
其HIFI系列产品的主要应用包括:


Xtensa处理器作为可配置处理器核,支持指令扩展,用户可以将常用逻辑封装成电路,并增加新的指令进行调用,例如:

f表示函数,既可以是FFT,也可以是CRC等等任何算法。
1.现代处理器为了更好的支持高级编程语言的高效编译,通常处理器所拥有的通用寄存器的数目都有16个甚至32个之多,如此多的寄存器在比较复杂的应用程序上实现深度嵌套调用的时候,为了保证程序的正确执行,寄存器要频繁的进行入栈和出栈操作,这样频繁的堆栈存储器访问将明显降低应用程序的性能,为有效解决这一问题,tensilica的Xtensa架构设计了一种Windows旋转方式的寄存器管理机制,将逻辑寄存器和物理寄存器分开,在函数调用的时候通过windows滑动切换逻辑寄存器,从而避免寄存器覆盖,在设计上增加了一层抽象,减少压栈和出栈的操作,更大限度的提高性能。下图展示在64个物理寄存器上实现的寄存器窗口,虽然ISA仅仅定义了16个AR寄存器,但是实际微架构设计时不限物理寄存器的数量的,当然,成本是随着微架构寄存器的数目增加而增加的。

更具体的一个映射的例子:

关于寄存器窗口工作机制中,WindowBase和指令中的src,dst域合作,实现最终物理寄存器寻址的工作原理,可以用下图表示,连线中的斜线旁数字一起表示数据位宽,下图表示的是一个64个32位物理寄存器微架构实现的寻址方案。

物理寄存器数量是有限的,如果嵌套多层调用call4/8/12,则一定会发生覆盖原来寄存器窗口的情况,覆盖发生时,Xtensa通过寄存器窗口异常来处理这种情况。寄存器窗口机制中,任何地方引用a0-a3都不会产生register window异常,用户在c或者汇编代码里面可以任意使用,因为在任意环境里,当前逻辑窗口的寄存器,要么无覆盖发生,要么已经在call/entry指令中进行了压栈保存。a4-a15的高位寄存器引用会触发低位寄存器的覆盖检测,哪怕没有显示的使用低位寄存器,触发的顺序是先进行overflow4,然后overflow8至overflow12.
entry指令的执行伪码:


2.ESP32和HIFI3/4/5的区别

HIFI3/4/5的ISA是一样的,区别可能在于资源数,执行单元的实现方式方面。


总结:
- HIFI系列在Xtensa核心的基础上,集成了DSP Extensions,比如集成VLIW计算单元加速各种DSP操作等等,ESP32核心则没有这些扩展。
- ESP32和HIFI系列的base ISA部分应该是一样的,这有点类似于RISCV ISA RV32I/64I extensions的设计。但是,Base ISA相同并不表示处理器的特性是完全一样的,尤其是Xtensa这种支持可重构的处理器设计架构,它非常容易扩展新的指令,所以HIFI系列作为xtensa core的DSP实现,一定在增加了支持fast DSP操作DSP指令。ESP32不是DSP,它没有这些。
- ESP32确实有一些32bit mac单指令,比如单周期的乘累加指令,虽然也可以用它做一些DSP操作,但是这和HIFI核的做法是完全不一样的,HIFI核基于硬件vector和VLIW的方式实现,是面向DSP处理的,性能肯定不在一个水平上。
- 实际上github上有一个项目,就是实现了一个用ESP32进行类似DSP操作的算法库。esp-dsp项目。
- HIFI5 DSP是LX系列处理器的一个configuration option,可以加入在LX系列处理器核里面构成DSP核,没有加入的当然不算是DSP,当使用DSP的扩展配置后,编译器会自动将指令用HIFI5 DSP加速的方式编译。
- HIFI5 DSP is built on the baseline of Xtensa RISC Architecture, 它最厉害的能力来源于DSP指令集和音频指令集扩展,而非baseline ISA,如果想看baseline ISA咋样,可以去用esp32或esp8266体验一下。
- HIFI系列处理器最多可以同时发射5条指令(没有结构,数据相关),并将这五条指令打包成128位的超长指令,分配给五套VILW Machine slots执行单元去执行。存在结构相关的指令无法在一起打包成VLIW,比如,由于只有 slot0支持store操作,所以无法同时打包两条或者以上的内存store操作执行,其它依赖slot能力的指令也有限制,具体要看每个slot的支持信息。
- 貌似xtensa对自家编译器xcc的寄存器调度能力非常自信,所以它不推荐用户在HIFI5上手搓DSP汇编
- 相对于HIFI4和HIFI5性能有所增强,包括VLIW machine 槽数(HIFI4 4个,HIFI5 5个),这使得HIFI有更强的计算资源,例如MACs,和load/store带宽,在其其它方面,HIFI5也有所增强。但是从软件开发的角度,HIFI4/5都是基于Xtensa LX processor,并且支持的都是 XEA2异常模型。
- The ESP32 has the MAC16 which adds some 16-bit multiply/add instructions to the ISA, but it does not have HiFi extensions. I think this may mean there are no VLIW machine slots, but I'm not sure... There's some examples of this here if you're interested; the linked code compiles for & runs on an ESP32.
- Window ABI has a limitation that all the codes should be put in the same GB region. e.g. 0 ---- 0x3FFFFFFF or 0x40000000 --- 0x7FFFFFFF, call4/call8/call12 has the effective range (524284 to 524288 bytes). But they have another long call version: callx4/callx8/callx12 which can be enabled by compiler option -mlongcalls. Complier will automatically use them if required. They can allow a call in the 1GB region.
- The Xtensa ISS (invoked with xt-run) supports two major simulation modes, cycle-accurate and fast functional, which the user specifies via a command-line option. In the default cycle-accurate mode, the ISS directly simulates multiple instructions in the pipeline cycle by cycle, modeling most micro-architectural features of the Xtensa processor while maintaining a very high degree of accuracy. In this mode, the ISS can be used as a reference model for a detailed hardware simulation.
In the fast functional (or TurboXim) mode, the ISS does not model the micro-architectural details but performs an architecturally correct simulation of all Xtensa instructions and exceptions. For long-running programs, the fast functional simulation can be 40 to 80 times faster than the cycle-accurate simulation, which makes it ideal for high-level verification of application software.
Our ISS models iDMA and memory, but does not currently support QEMU – which would allow expansion of other system IP. However, we have another tool (XTSC) that supports both transaction-level modeling and pin-level modeling of the Xtensa cores in a SystemC or SystemC/Verilog environment. And we have customers currently co-simulating XTSC alongside other IP on QEMU.
Xtensa LX处理器具有称为FLIX(可变长度指令扩展)的功能,允许处理器将现有的16位和24位Xtensa指令混和生成定制的宽指令,VLIW示意图,slot是执行单元,每个能力不同,需要注意指令不能存在结构相关。

3.根据谷歌到的关于xtensa的资料,提取到的一些关于VLIW应用场景和用法的一些信息,一共包括十种指令打包格式,每种格式在所用资源,应用场景,指令长度方面有所差异。

4:根据经验,一般情况下,处理器ISA的异常入口定义,暴漏给软件的使用方式有两种:
第一种:就是ISA固定死异常的入口地址,比如之前的arm9只有0x00000000/0xffff0000两个选择,mips的启动向量在0xbfc00000等等.
第二种:ISA提供异常基地址寄存器,软件可以将异常入口地址写入,这样异常入口放在地址空间的任何位置都可以,比如 riscv/cortex-a系列。
但是我在 xtensa的spec里面,没有看到关于入口地址的定义,也没有再代码里面找到把异常入口配置给某个寄存器(软件反编译后找符号表,没有找到异常符号设置给某个寄存器的逻辑)
所以造成的困惑是,我知道异常时它会调用某个异常处理函数,但是却不知道执行流从哪里进来的!
所以,如果上面两个选项都否的话,第三种异常处理方式是什么呢?难道是HW数字设计的时候入口地址就决定了,然后生成配置文件(这里就是链接脚本xmm),软件按照这个配置文件将异常代码放在正确的地方,这样我也能理解。
经过确认,xtensa就是这样处理的,也就是说,异常向量表的地址可以重新map,这也是它声称自己作为可重构处理器的一个方面,探查esp32/exp8266SDK的编译链接方式可以知道,软核重构产生的xmm文件产生链接脚本,软件按照产生的链接脚本布局代码和数据,所以说地址和HW里面的异常入口逻辑是绑定的,那么芯片T.O后,如果我再修改xmm文件,造成异常入口代码和实际硬件的不一致,CPU进入了错误的入口处理程序,就会出问题。
不过软件常说,解决一个问题,可以通过加一个层的方式解决,这种说法也适用于硬件,毕竟都是语言嘛,数字设计的时候可以在外围配置一些寄存器,这些寄存器不属于xtensa ISA,通过这些寄存器设定的逻辑,可以灵活设置异常入口,达到类似于riscv mtvec/stvec或者cortex-a CP15 vbar地址效果。
可重构处理器比较灵活,它可以根据不同的配置生成HDL代码,要改变处理器的功能,只需要重新配置生成代码就行,这一点有点类似于软件开发中的配置头文件,不是么?
5:ESP32 xtensa架构freeRTOS 启动流程,注意调用wsr.vecbase指令设置windowoverflow异常入口的操作。

关于WindowOverFlow设置的问题,ESP32里面通过"cpu_hal_set_vecbase"设置基地址,





6:ESP32的异常处理架构:

7:Xtensa ISA Windows check的时机,注意entry指令也会触发windowoverflow exception.

8:Xtensa ABI:

Window ABI和Call0 ABI不能混用,当然,安全的手搓汇编包含call0的除外。

9:Xtensa的寄存器窗口机制深入剖析
从github上cadence维护的freeRTOS开发仓库下载支持xtensa LX系列处理器的代码,这个仓库是cadence提供,开源。
git clone https://github.com/foss-xtensa/amazon-freertos.gitWindow ABI是Xtensa架构的一大特色,也是它最难以理解的地方,call4/call8/call12的调用会对callee函数使用的寄存器产生影响,子函数和父函数之间,相同的寄存器名却对应到不同的物理寄存器,这在ARM,X86,MIPS或者RISCV等架构中是很难想象的,这也对Xtensa架构的理解造成很大障碍。
经过深入分析Xtensa的文档,发现它的寄存器窗口概念虽然学习曲线很陡,主要是由于对文档的理解不够全面,漏掉了很多细节,实际上,关于寄存器窗口转换的核心逻辑,以及当发生窗口覆盖时处理器需要做的WindowOverflowException处理,ISA 架构文档都有介绍的,只是英文读起来比较生涩,相关章节多读几次,慢慢就有些感觉了。
经过总结,实际上,它的寄存器窗口对系统软件有一个很强的假设,这个假设是mandatory的,那就是所有线程的调用栈顶层,要么用call4发起对first function的调用,要么通过手搓汇编手工捏造一个符合call8 exception handler或者call12 exception handler的调用,以满足WindowException触发的最顶层逻辑,这个逻辑就是WindowOverflow8/12需要一个初始的base save area以获取堆栈指针,见下图:



可以看到,_WindowOverflow8/_WindowOverflow12异常开始都需要从堆栈中获取一个sp,这个SP的来源,要么通过call4产生的_WindowOverflow4进行初始化,要么手工捏造一个堆栈布局保证window register机制可以有效运行。
经过分析,一个三级深度的函数调用堆栈布局如下:

基于同样的原因,在FreeRTOS线程创建初始化堆栈填充的时刻,由于线程入口函数上层没有调用链,为了保证寄存器窗口能够正常工作,也要伪造一个call4的现场,方法如下面截图所示:
代码在freertos/kernel/FreeRTOS/portable/XCC/Xtensa/port.c pxPortInitialiseStack函数实现中。

通过开启window register(WOE),设置PS_UM(用户exception)以及最主要的CALLINC(1),恰好对应call4的callinc,EXCM设置为1的目的是保证rfe异常返回。
在线程入口函数执行entry指令的时刻,会用到这里设置的callinc。
10: 关于初始化堆栈是否需要初始化以及如何初始化的逻辑:
如果需要初始化,需要按照如下步骤:

什么情况不需要初始化:

什么时候必须初始化:

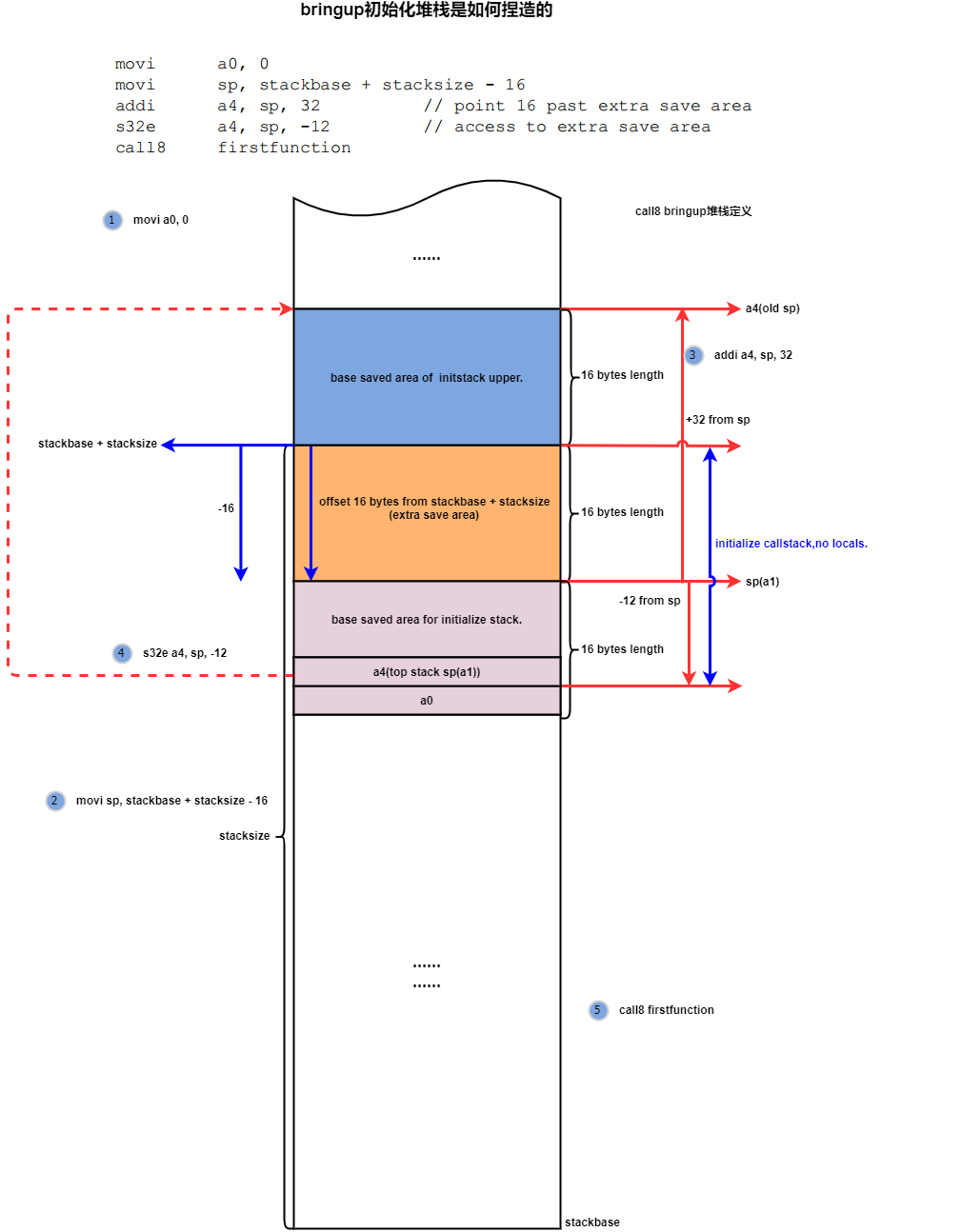
12:call8/call12 初始化stack手工捏造的逻辑,注意以下几点:
1.蓝色部分是 bringup初始化流程手搓的当前堆栈,代表的是bringup汇编所使用的堆栈,一般是_start标志的流程。
2.这个堆栈没有local object,只有褐黄色部分的extra save area和下方紫色部分的base saved area,这个很好理解,汇编阶段捏造的堆栈,本身就不需要栈中的存储。
3.执行流程为,如果由firstfunction发起的调用链在某次函数调用中覆盖了这一层的寄存器,则window会旋转到call8这里代表的寄存器窗口视图,执行WindowOverflow8异常处理,处理过程中,首先获取sp-12地址存储的上一个栈帧的sp(a1,其实这个栈帧都是捏造的,哪里存在上一个栈帧,这里取上一级sp的目的是,只有通过这一层的sp,再加上16个字节的便宜skip掉base saved area(蓝色部分),才能对黄色部分extra save area进行寻址.).
4.在WindowOverflow8中,继续通过a9,也就是firstfunction的栈地址,将bringup栈中a0-a3的值保存到firstfunction的base save area中。
5.为call8/12 捏造一个堆栈的目的是模拟上层存在一个call4的调用,已经为发生过一次windowoverflow4异常,并且将自身的sp保存到call8的base save area里面,这样对于call8层来说,可以通过保存的sp的值寻址到本层的extra save area.
而call8本身的a0-a3是保存在callee的base save area中的。
call12初始化堆栈与call8大同小异,在细节上有所不同,call12考虑到传参和本地变量的空间,传参上,它考虑到了在extra save area为a8-a11预留出16字节的空间,然后又预留了16字节整数倍的loc字节作为stack local 变量的空间.

经过这种堆栈的捏造,线程的调用源头的第一个c函数调用就可以不用call4来实现了.
不得不说,Xtensa的堆栈布局太TM毁三观了,看完Xtensa再回头在看ARM,RV,感觉ARM,RV可爱多了。
13:为了夯实对Window Register ABI的理解,继续分析一下setjmp这个和软件ABI关系最密切的函数。
Xtensa的struct jmp_buf定义如下:





14:特殊指令对特殊寄存器的影响

15:WindowCheck的逻辑

16:貌似xt-xcc编译器编译c代码只能产生call8指令,call4/call12只能由使用者手搓汇编实现,看下面一个可执行文件的call4/8/12的使用频率即可说明。
call0是一个独立的ABI,只能手搓,除非系统选中CALL0 ABI而非Window ABI.

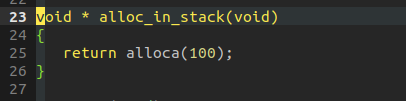
alloca堆栈分配内存指令会产生"movsp"指令,貌似也不太多:

比如,下图中的movsp指令是因为alloc_in_stack中调用了alloca而产生的。


总结:
1.call8要求extra save area 16个字节和base save area 16个字节,所以入口处的entry至少是32.
2.call12要求extra save area 32个字节和base save area 16个字节,所以入口处的entry至少是48.
3.由于c代码编译默认只用call8指令,所以对于非叶子函数来说,入口处一定不能是entry 16.对于叶子函数,貌似c编译器也是以entry 32开始的,其实为了节省空间,应该可以手搓汇编用entry 16开始,然后内部用call4调用或者不进行函数调用。
4.根据寄存器窗口的工作原理,由于进行子函数调用时,旋转寄存器窗口到新的寄存器视图,所以父子函数之间没有寄存器冲突,也就是说,父函数有用的寄存器,不会被子函数踩踏,所以父函数不需要保存,同样的,子函数也不用怕踩踏破坏父函数的执行现场,子函数只会破坏调用链更远处的调用现场,触发W.O.F Exception.
movsp指令的硬件执行逻辑,中间会触发alloca异常搬运当前堆栈的base save area[sp-16,sp]到新的[as-16,as]范围内,算是lazy restore的一种方式。

异常处理流:

17:xtensa原生xt-xcc貌似不支持"__builtin_apply_args" "__builtin_apply" "__builtin_return" 几个GNU GCC内建扩展,不知道ESP32 的xtensa gcc支持度怎么样.

18:ill/ill.n指令类似于riscv的unimp指令,作用是无条件触发非法指令异常,软件中用于调试


19:关于xtensa的中断逻辑:
1.中断LEVEL数字越大,中断的优先级越高,所以Level-1, Level-2, Level-3,...优先级逐渐升高.
2.EXCMLEVEL 默认设置一个比较大的数字,表示可以屏蔽掉大部分中断,当异常发生,PS.EXCM为1,下图表示的公式,处理器的异常level级CINTLEVEL 由PS.EXCM乘积项决定,所以异常发生时刻会屏蔽大部分中断,这种在异常中屏蔽中断的做法,
MPS,ARM,RISCV都有类类似实现,不足为奇。



3.根据PS.UM配置的不同,异常可以走KernelExceptionVector或者UserExceptionVector, UserException可以在处理之前切换堆栈,而KernelException直接使用内核栈.

4.关于中断优先级,NMI最高,DEBUG次之,随着level越小,优先级越低。DEBUG level是优先级仅次于NMI的中断。

5.interrupt寄存器作用类似于通用处理器上的interrupt pending寄存器,标志当前活跃待处理的中断请求。

6.中断处理流程:

7.在用Xplorer ISS模拟器运行FreeRTOS测试用例项目的时候,编译过了,但到了最后一步链接总是不过,原因是FreeRTOS原生代码xtensa_vector.S中的异常处理使用了call0指令,但是由于xtensa指令编码的offset域只有18bit,单位是WORD,换算过来也只支持
1M byte的偏移,而且链接器链接的时候将call0 后面的函数连接到了超过1M远的地址,所以链接不过,类似的问题在MIPS中也存在。
为了解决这个问题,根据xt-xcc手册,需要编译的时候加入一个编译选项:
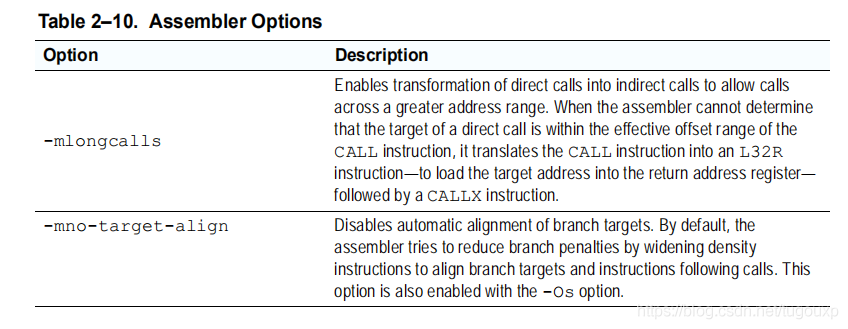
本来是想通过xplorer的build配置页面增加-mlongcalls编译选项的,试了多了不成功,可能是对这套工具不太熟悉的缘故把,后来索性自己修改以下汇编代码,如下图,左边是修改后的,将call0指令变成加载指令和callx指令,发现不同架构在跳转后加入后缀-x 表示寄存器跳转,这一点是相同的,例如arm bx,mips jalx, riscv也有后缀为x的跳转指令。

视立即数的位宽, 编译器判断是否将movi指令编译成l32r指令
