介绍
官网: http://cocodataset.org
https://cocodataset.org/#download
MSCOCO 是具有80个类别的大规模数据集,其数据分为三部分:训练、验证和测试,每部分分别包含 118287, 5000 和 40670张图片,总大小约25g。其中测试数据集没有标注信息,所以注释部分只有训练和验证的。
关于COCO的测试集:2017年COCO测试集包含〜40K个测试图像。 测试集被分成两个大致相同大小的split约20K的图像:test-dev 和test-challenge。
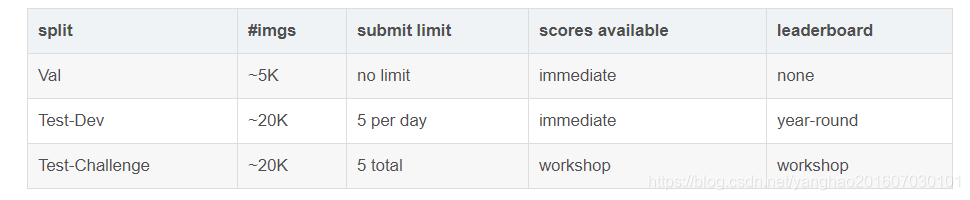
Test-Dev:test-dev split 是在一般情况下测试的默认测试数据。通常应该在test-dev集中报告论文的结果,以便公正公开比较。
Test-Challenge:test-challenge split被用于每年托管的COCO挑战。
关于COCO检测的参考文章:
MS COCO数据集输出数据的结果格式(result format)和如何参加比赛(participate)(来自官网)
下载地址:
2017 Train images [118K/18GB]:http://images.cocodataset.org/zips/train2017.zip
2017 Val images [5K/1GB]:http://images.cocodataset.org/zips/val2017.zip
2017 Test images [41K/6GB]: http://images.cocodataset.org/zips/test2017.zip
2017 Annotations:http://images.cocodataset.org/annotations/annotations_trainval2017.zip
COCO数据组织形式
其数据组织形式:
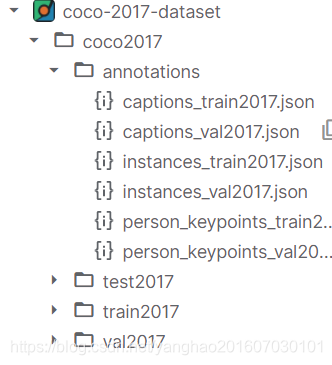
即图片分为3部分,test、train和val,图片的标注保存格式是json文件,并且是所有图片标注放在一个json文件中。
对于目标检测而言,我们需要关注的标注是annotations文件夹下的instances_train.json和instances_val.json,分别对应的是train和val图片的标注。
这两个json文件内的组织形式如下:
总体格式
{
"info": info,#描述数据集的基本信息
"licenses": [license],#协议,不用管
"images": [image],#图片信息,大小,id,文件名等
"annotations": [annotation],#标注信息,包括分割和边框信息
"categories": [category]#类别信息,包括类别id,所属子类和类名
}
以instances_train.json为例,
info部分格式
"info":{
"description":string"COCO 2017 Dataset"
"url":string"http://cocodataset.org"
"version":string"1.0"
"year":int2017
"contributor":string"COCO Consortium"
"date_created":string"2017/09/01"
}
licenses部分格式
"licenses":[#8 items
0:{
#3 items
"url":string"http://creativecommons.org/licenses/by-nc-sa/2.0/"
"id":int1
"name":string"Attribution-NonCommercial-ShareAlike License"
}
1:{
...}#3 items
2:{
...}#3 items
3:{
...}#3 items
4:{
...}#3 items
5:{
...}#3 items
6:{
...}#3 items
7:{
...}#3 items
]
images部分格式
"images":
[
{
"license":int3
"file_name":string"000000391895.jpg"
"coco_url":string"http://images.cocodataset.org/train2017/000000391895.jpg"
"height":int360
"width":int640
"date_captured":string"2013-11-14 11:18:45"
"flickr_url":string"http://farm9.staticflickr.com/8186/8119368305_4e622c8349_z.jpg"
"id":int391895
},
{
...},
....
]
annotations部分格式
"annotations": [
{
"segmentation": [[510.66,423.01,511.72,420.03,510.45......]],
"iscrowd": 0,
"image_id": 1,
"bbox": [ # x1,y1,w,h,coco的边框表示是左上角坐标加宽高
535.0,
371.0,
199.0,
181.0
],
"area": 36019.0,
"category_id": 1,
"id": 1
},
{
...},
....
]
categories部分格式
"categories": [
{
"supercategory": "Cancer",
"id": 1,
"name": "hu"
},
{
"supercategory": "Cancer",
"id": 2,
"name": "shu"
}
]
COCOapi
COCO数据集官方提供了COCO API用于更加方便地解析标注文件,在使用之前通过pip install pycocotools安装依赖。可直接查看该COCOAPI的官方文档。在使用各API前,我们需要实例化COCO类,它接受的参数为标注文件的路径,返回类的对象。COCO中的核心单元是anno。
使用COCO时,首先需要初始化COCO类,
.__init__(self, annotation_file=None):读取val2017.json文件并解析到类中的dataset对象中去,然后.createIndex()。这里的.createIndex()步骤非常关键;
.createIndex():会在初始化的时候,为COCO类创建了5个对象非常重要的对象:
anns:包含所有anno 的字典,key是anno的id,value是anno的值,也就是一条标注;
cats:包含所有的category的字典,key是category的id,value是对应category的一些基本信息。对于行人检测的只有一个类来说,这里只有person;
imgs:包含所image的字典,key是image_id,value是image的基本信息;
imgToAnns:image和anno的对应关系,key是image_id,value是一个包含了这张图片里所有anno的list;
catToImgs:category和image的对应关系,key是category,value是一个包含了有这个category的image的image_id;
上面的初始化之后,就可以调用以下api:
-
.info(self):打印数据集的一些基础信息,不重要; -
.getAnnIds(self, imgIds=[], catIds=[], areaRng=[], iscrow=None):根据一条标注信息对应的image_id、cat_id、area_range、iscrowd来获得对应的id,这里iscrowd对应segmentation的格式,不重要, -
.getCatIds():获得category id; -
.getImgIds():根据些东西获得image_id; -
.loadAnns(self, ids=[]):根据id来获得anno; -
.loadCats(self, ids=[]):根据cat_id来获得category; -
.loadImgs(self, ids=[]):根据image_id来获得image; -
.showAnns(self, anns):根据一条anno记录来进行可视化,但是返回值是None,没什么用。看吧,我就说COCO疏于维护(怕不是写api的实习生实习结束了,手动斜眼); -
.loadRes(self, resFile):是我们最常用的也是最重要的方法。它做了以下工作:
1)初始化另一个COCO类DT(以下用DT指代检测类),用于存储检测数据;
2)将GT的所有image赋给DT,也就是DT所有的image和GT是完全一样的;
3)读取由我们自己生成的结果.json文件,并且判断结果.json文件必须是完全被GT的image包含的;
4)依次为DT类生成caption、bbox、segmention、keypoints,并且,重写DT类里所有anno的id,也就是不管我们有没有在我们的结果文件里生成id,它都会在这里重写这些id以保证id的唯一性;
5)返回需要的DT;
这部分参考:https://zhuanlan.zhihu.com/p/135355550