Requests库网络爬取实战
实例1:京东商品页面的爬取
import requests
url = "https://item.jd.com/100007136939.html"
try:
kv = {
'user-agent':'Mozilla/5.0'}
r = requests.get(url,headers = kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print("爬取失败")
京东也拒绝爬虫,需要将代理名改为服务器了
实例2:百度/360搜索关键词提交
#baidu
import requests
keyword = "Python"
try:
kv = {
'wd':keyword}
r = requests.get("http://www.baidu.com/s",params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print("爬取失败")
#360
import requests
keyword = "Python"
try:
kv = {
'q':keyword}
r = requests.get("http://www.so.com/s",params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print("爬取失败")
实例3:网络图片的爬取和存储
import requests
import os
url = "http://file06.16sucai.com/2018/0330/61064182a59d797418c44af840cc1f23.jpg"
root = "D://pics//"
path = root + url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(url)
with open(path, 'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
吐槽
现在网站哪能找到jpg结尾的网址,都被隐藏了。
实例4:IP地址归属地的自动查询
import requests
url = 'https://m.ip138.com/iplookup.asp?ip='
try:
kv = {
'user-agent': 'chrome/10'}
r = requests.get(url + '202.204.80.112', headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[-500:])
except:
print("爬取失败")
注:这个出错了,出错我也没看懂,写在这记录一下
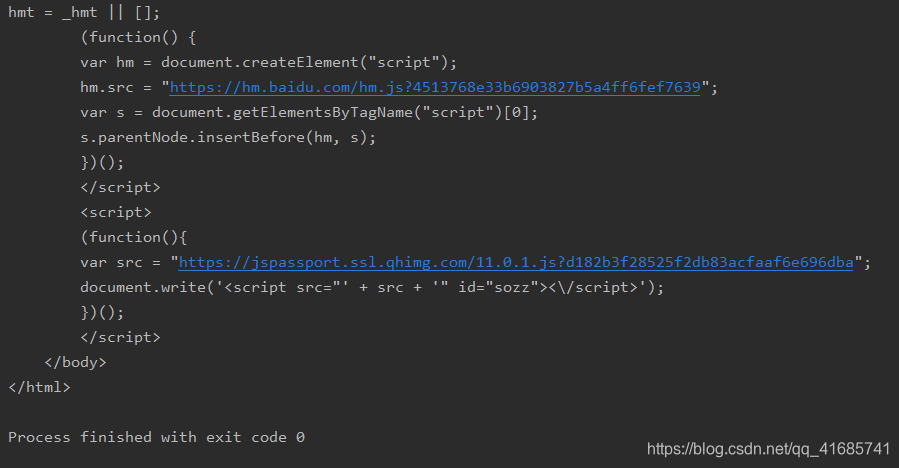
修改以后,附带参考文章https://blog.csdn.net/weixin_44578172/article/details/109376326
import requests
def getHTMLText(url):
try:
kv={
'user-agent':'Mozilla/5.0'}
r=requests.get(url,headers=kv)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.text[2000:3000])#分片查看相应字节
except:
print("爬取失败")
def main():
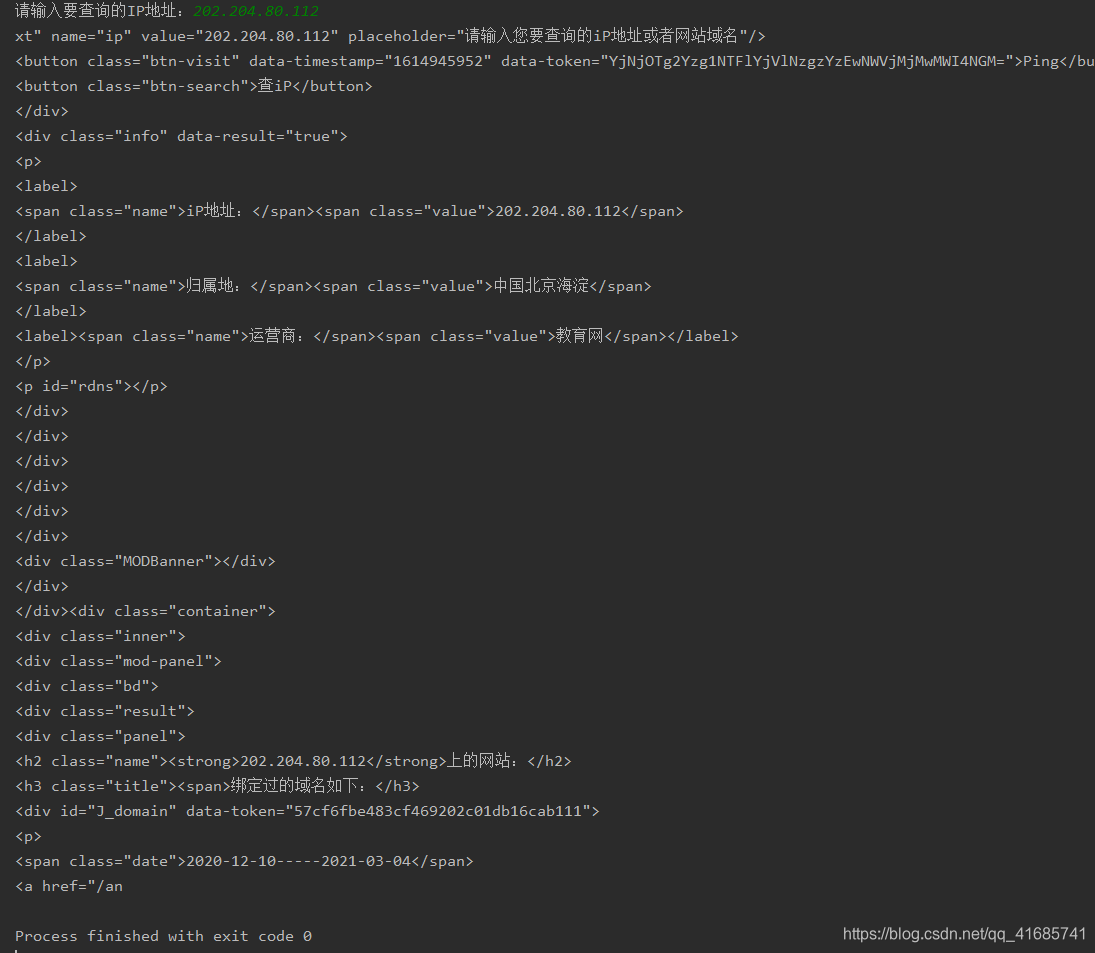
a=input("请输入要查询的IP地址:")
url='https://ipchaxun.com/'+a
getHTMLText(url)
main()
运行结果
小结:
大家看的课程都一样呀,哈哈哈哈,加油