作为一个即将工作的人,想看看自己的薪酬在重庆处于什么段位。如果对如何实现的不感兴趣,可以拉到后面,看第三部分,结果分析可视化部分。
一数据爬取部分
手里没有招聘信息,我们需要从网上爬取。
一.目标站点分析
数据来源:51job
网站超链接:51job重庆
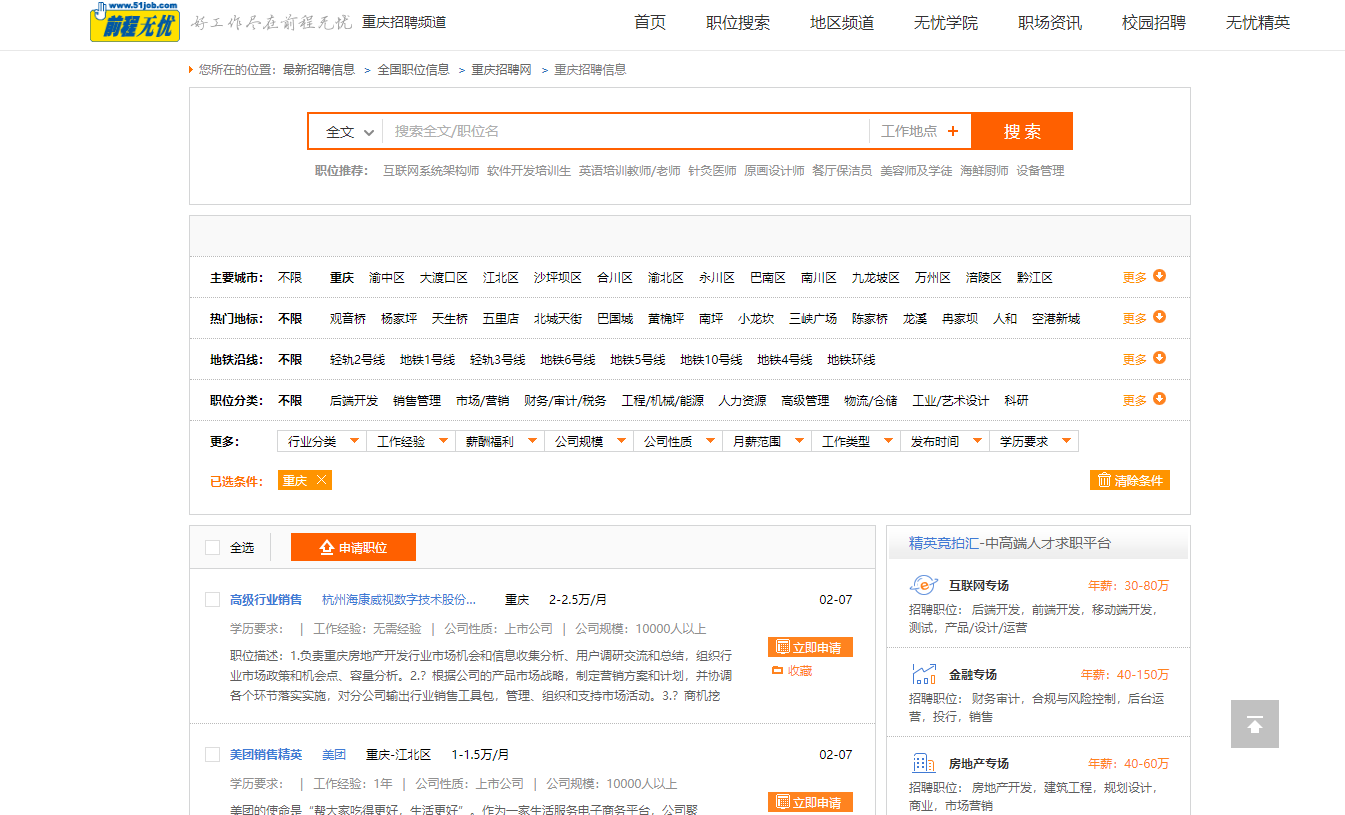
二.爬取单页网页html
采用python +requests
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Author: yudengwu(余登武)
# @Date : 2021/2/7
#@email:[email protected]
import requests
def get_page(url,page):#获取请求并返回解析页面,offest,keyword为可变参数
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'}
try:
response = requests.get(url,headers = headers,timeout=10)
response.encoding = 'gbk' # 加编码,重要!转换为字符串编码,read()得到的是byte格式的
if response.status_code == 200 :
return response.text
except ConnectionError:
print('程序错误')
return None
def main():
for i in range(1, 2): # 遍历网页1
base_url = 'https://jobs.51job.com/chongqing/p'+str(i)+'/'
html=get_page(base_url,i)
print(html)
if __name__ =='__main__':
main()
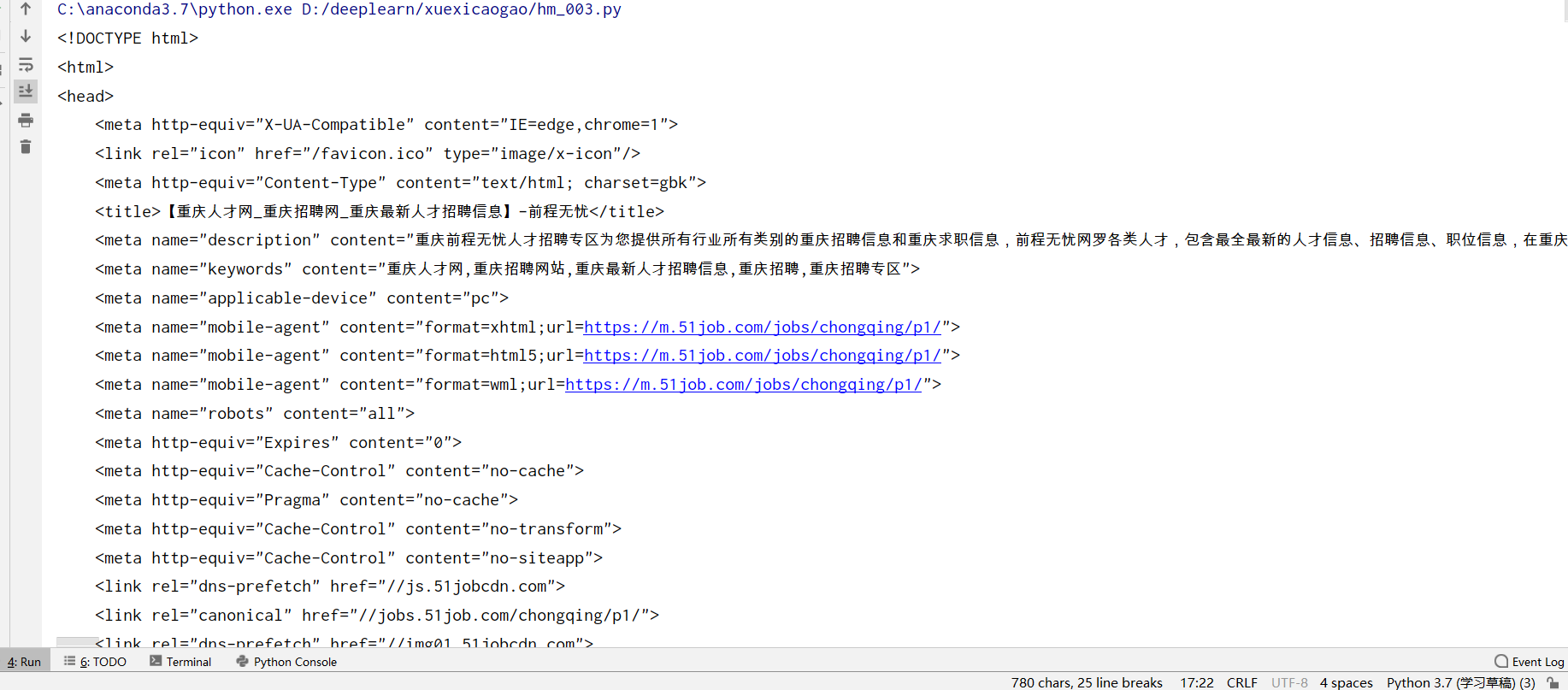 和浏览器里的html一样
和浏览器里的html一样
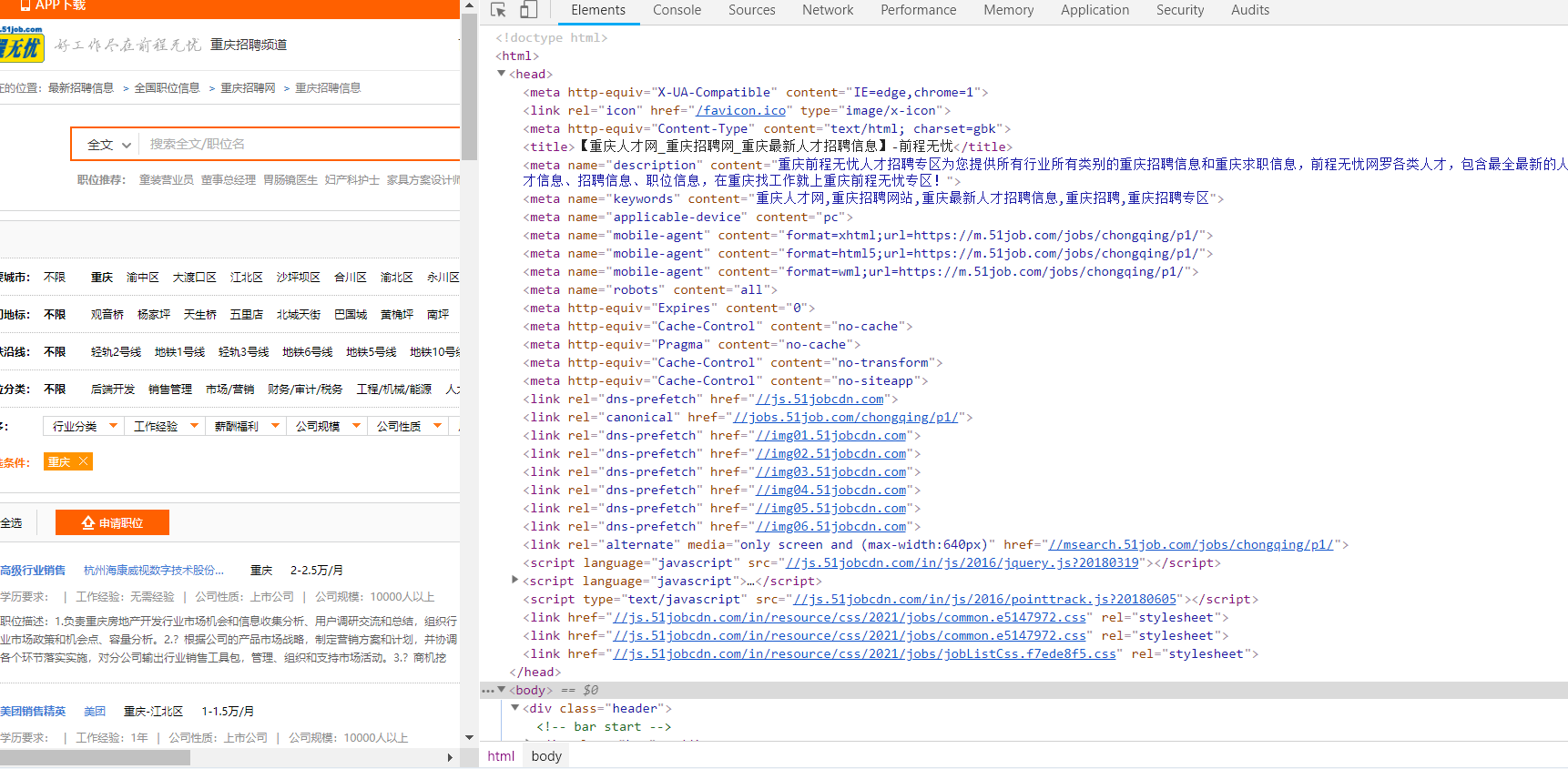
三.网页信息提取
BeautifulSoup+re正则
一条招聘信息对应html区域如图
对前端的css有些熟悉,所以用 BeautifulSoup中select来选择信息。
教程见链接
爬虫笔记:BeautifulSoup详解
该部分的 BeautifulSoup 选择代码为items=soup.select('.maincenter .mcon .left .detlist.gbox .e')

打开一个招聘信息查看
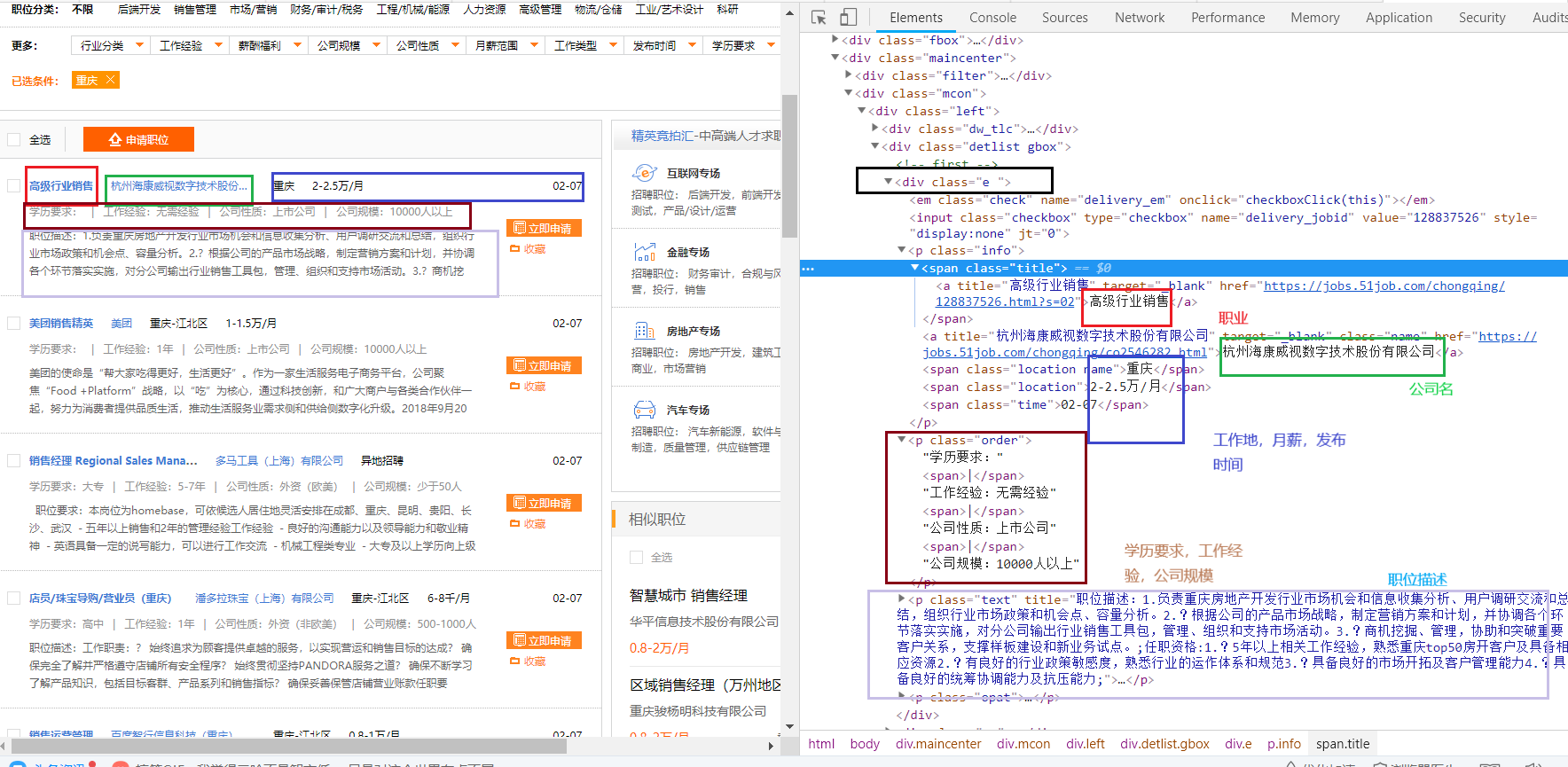
根据上图,可以慢慢确定信息提取代码
如下
再遍历每一个招聘信息for item in items:#遍历每一条招聘信息
职位选择position=item.select('.info .title a')[0]
公司名company_name=item.select('.info a')[1]
工作地workplace=item.select('.info .location.name')
工资salary=item.select('.info .location')[1]
发布日期release_time=item.select('.info .time')[0]
学历要求degree=item.select('.order')[0] degree=degree.get_text() degree_study=re.split(r'\|',degree)[0]
工作经验work_experience=re.split(r'\|',degree)[1]
公司性质nature_company=re.split(r'\|',degree)[2]
公司规模company_size=re.split(r'\|',degree)[3]
岗位描述JobDescribe=item.select('.text')[0]
爬虫部分总代码
开启多线程爬虫
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Author: yudengwu(余登武)
# @Date : 2021/2/7
#@email:[email protected]
import requests
from bs4 import BeautifulSoup
import re
import numpy as np
import pandas as pd
import time
from requests.exceptions import RequestException
def get_page(url,page):#获取请求并返回解析页面,offest,keyword为可变参数
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'}
try:
response = requests.get(url,headers = headers,timeout=10)
response.encoding = 'gbk' # 加编码,重要!转换为字符串编码,read()得到的是byte格式的
if response.status_code == 200 :
return response.text
except RequestException:
print('程序错误')
return None
#解析网页
def pase_page(url,page):
html = get_page(url, page)
html = str(html)
if html is not None:
soup = BeautifulSoup(html, 'lxml')
"--先选择招聘信息,得到的是一组招聘信息--"
items=soup.select('.maincenter .mcon .left .detlist.gbox .e')
#print(items)
for item in items:#遍历每一条招聘信息
'职位'
position=item.select('.info .title a')[0]
position = position.get_text()
#print(position)
'公司名'
company_name=item.select('.info a')[1]
company_name=company_name.get_text()
#print(company_name)
'工作地'
workplace=item.select('.info .location.name')
workplace=' '.join(i.get_text()for i in workplace)
#print(workplace)
'工资'
salary=item.select('.info .location')[1]
#salary=' '.join(i.get_text()for i in salary)
salary=salary.get_text()
# print(salary)
'发布日期'
release_time=item.select('.info .time')[0]
release_time=release_time.get_text()
#print(release_time)
'学历要求'
degree=item.select('.order')[0]
degree=degree.get_text()
degree_study=re.split(r'\|',degree)[0]
#print(degree_study)
'工作经验'
work_experience=re.split(r'\|',degree)[1]
#print(work_experience)
'公司性质'
nature_company=re.split(r'\|',degree)[2]
#print(nature_company)
'公司规模'
company_size=re.split(r'\|',degree)[3]
#print(company_size)
'岗位描述'
JobDescribe=item.select('.text')[0]
JobDescribe=JobDescribe.get_text()
#print(JobDescribe)
'-------------写入表格-------------------'
information = [position,company_name,workplace,salary,release_time,degree_study,work_experience,nature_company,company_size,JobDescribe]
information = np.array(information)
information = information.reshape(-1, 10)
information = pd.DataFrame(information, columns=['position','company_name','workplace','salary','release_time','degree_study','work_experience','nature_company','company_size','JobDescribe'])
information.to_csv('51job重庆招聘数据.csv', mode='a+', index=False, header=False) # mode='a+'追加写入
print('第{0}页存储数据成功'.format(page))
else:
print('解析失败')
#多线程爬取
import threading
def main():
for i in range(1, 4997,3): # 遍历网页1-5000
base_url1 = 'https://jobs.51job.com/chongqing/p'+str(i)+'/'
base_url2 = 'https://jobs.51job.com/chongqing/p' + str(i+1) + '/'
base_url3 = 'https://jobs.51job.com/chongqing/p' + str(i + 2) + '/'
t1 = threading.Thread(target=pase_page, args=(base_url1, i)) # 线程1
t2 = threading.Thread(target=pase_page, args=(base_url2, i+1)) # 线程2
t3 = threading.Thread(target=pase_page, args=(base_url3, i + 2)) # 线程3
t1.start()
t2.start()
t3.start()
if __name__ =='__main__':
main()
有些页由于网页反映快慢问题或者其他问题没有抓取下来。不过对数据集影响不大,至少我们抓取的数据足够多近2万条。


二.数据处理部分
得到的数据表格,里面有些数据需要处理,如工资有的是按千计算,有的是按万计算,有的按月计算,有的按年计算。给我们分析带来很大困扰。我还想把学历要求,公式规模,公式性质这些多余的字去掉。

为了方便处理,首先给表格添加字段

工资处理
import pandas as pd
import re
import numpy as np
#读取数据
csv=pd.read_csv(r'D:\deeplearn\xuexicaogao\51job重庆招聘数据.csv',error_bad_lines=False,encoding='utf-8')
#删除空值
csv.dropna(axis=0, how='any', inplace=True)
'----工资处理---'
def get_money_max_min(x):
try:
if x[-3] == "万":
z = [float(i)*10000 for i in re.findall("[0-9]+\.?[0-9]*",x)]
elif x[-3] == "千":
z = [float(i) * 1000 for i in re.findall("[0-9]+\.?[0-9]*", x)]
if x[-1] == "年":
z = [i/12 for i in z]
return z
except:
return x
salary = csv["salary"].apply(get_money_max_min)#得到的工资为[3000.0, 4500.0]是一个区间,对应我们常说的3-4.5千、月
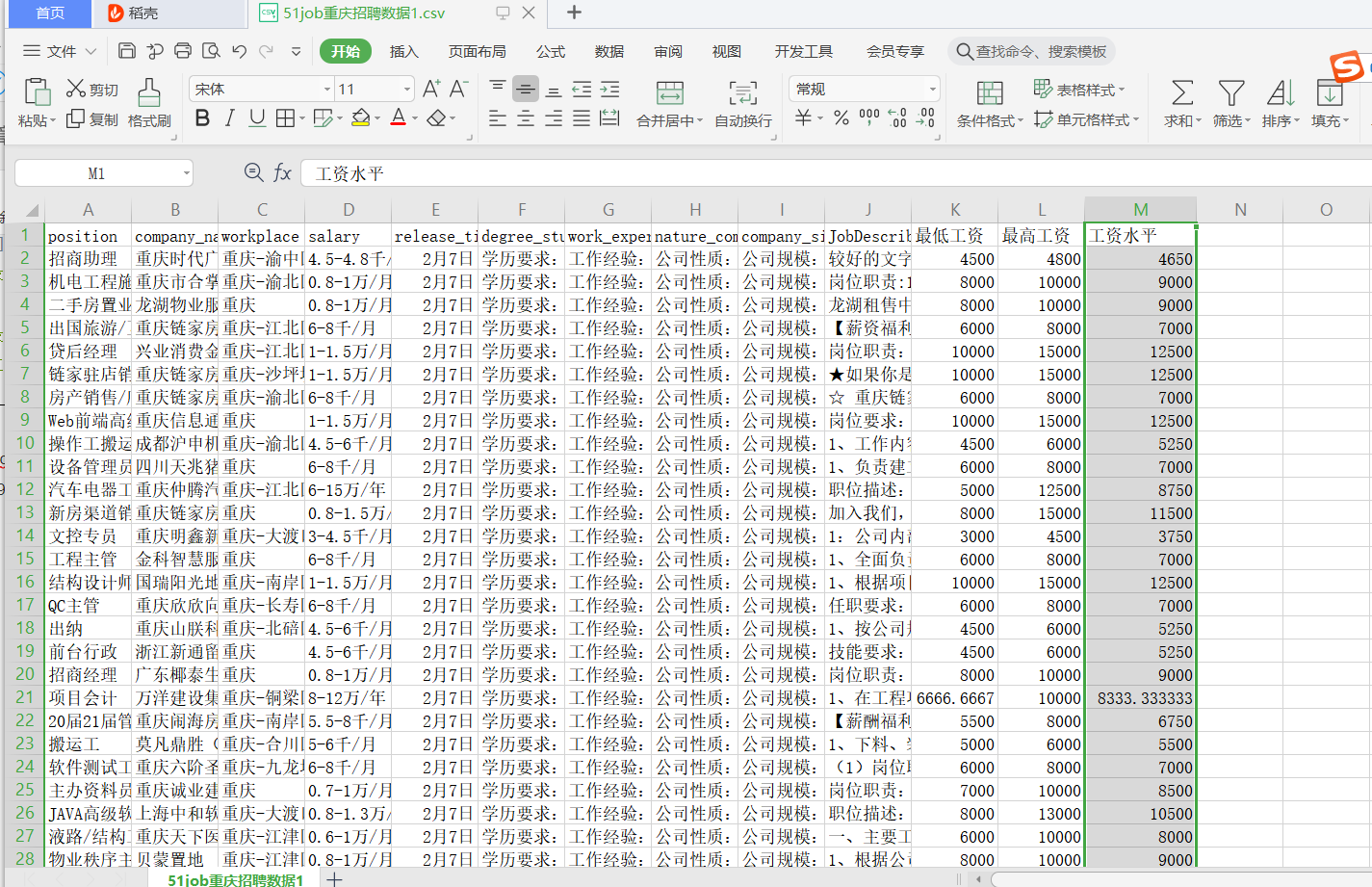
csv['最低工资']=salary.str[0]#16446
csv['最高工资']=salary.str[1]
csv['工资水平']=csv[["最低工资","最高工资"]].mean(axis=1)
csv.to_csv('51job重庆招聘数据1.csv')
处理后续代码
import pandas as pd
import re
import numpy as np
import jieba
#读取数据
csv=pd.read_csv(r'D:\deeplearn\xuexicaogao\51job重庆招聘数据1.csv',error_bad_lines=False,encoding='gbk',header=0)
#删除空值
csv.dropna(axis=0, how='any', inplace=True)
#学历处理
csv['degree_study']=csv['degree_study'].apply(lambda x:re.findall("本科|大专|应届生|在校生|硕士|博士",x))
def func(x):
if len(x) == 0:
return np.nan
elif len(x) == 1 or len(x) == 2:
return x[0]
else:
return x[2]
csv["degree_study"] = csv["degree_study"].apply(func)
csv["degree_study"].value_counts()
'公司规模处理'
def func1(x):
if x == '公司规模:少于50人':
return "<50"
elif x == '公司规模:50-150人':
return "50-150"
elif x == '公司规模:150-500人':
return '150-500'
elif x == '公司规模:500-1000人':
return '500-1000'
elif x == '公司规模:1000-5000人':
return '1000-5000'
elif x == '公司规模:5000-10000人':
return '5000-10000'
elif x == '公司规模:10000人以上':
return ">10000"
else:
return np.nan
csv["company_size"] = csv["company_size"].apply(func1)
'公司类型理'
#csv['nature_company']=csv.loc[csv['nature_company'].apply(lambda x:len(x)<6),"公司类型"] = np.nan
csv['nature_company']=csv['nature_company'].apply(lambda x:re.sub("公司性质:","",x))
'工作经验处理'
csv['work_experience']=csv['work_experience'].apply(lambda x:re.sub("工作经验:","",x))
'对岗位描述进行分词,为后续绘制词云图做好基础'
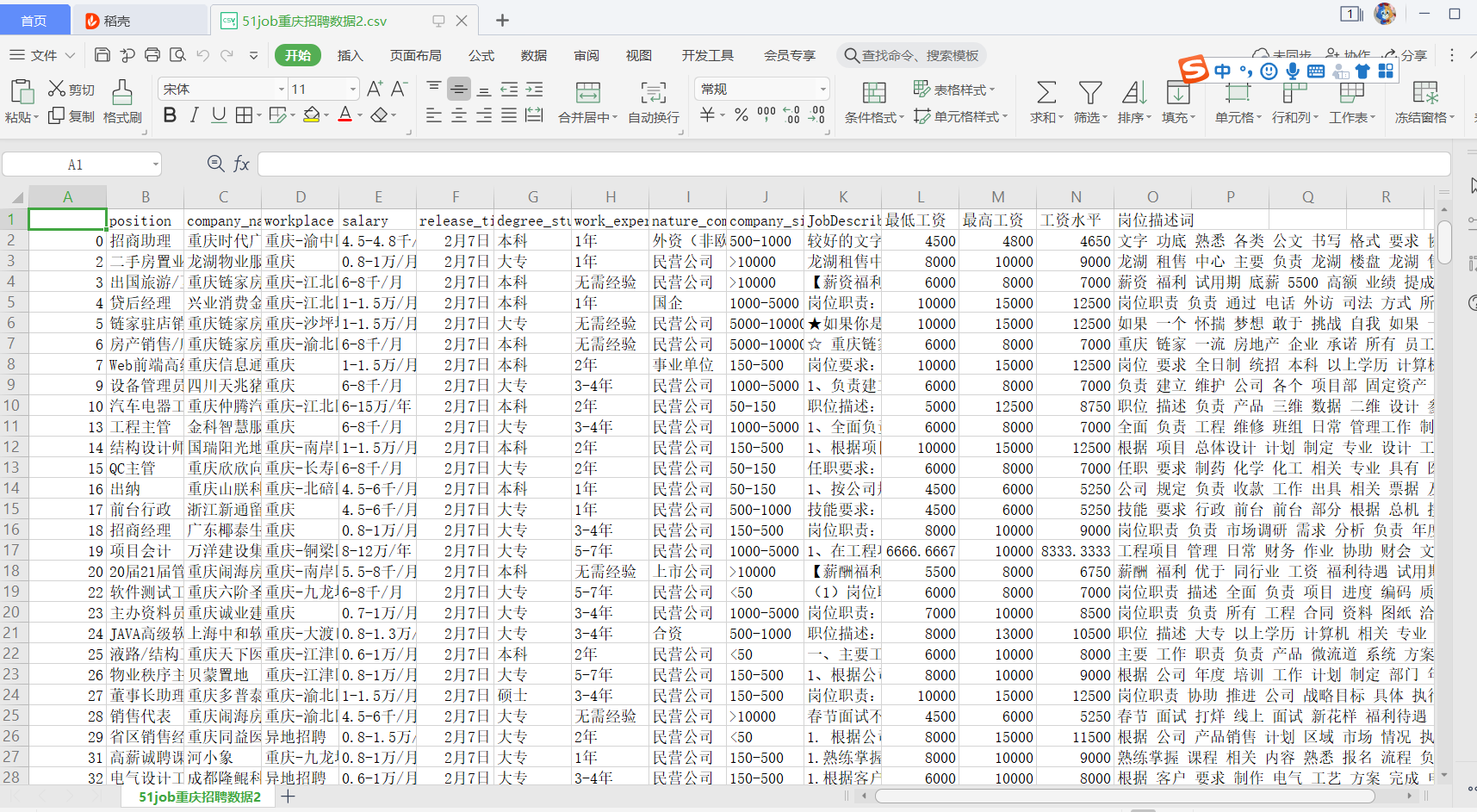
csv['岗位描述词']=csv['JobDescribe'].apply(lambda x:" ".join([w for w in list(jieba.cut(x)) if len(w)>1]))
#删除空值
csv.dropna(axis=0, how='any', inplace=True)
csv.to_csv('51job重庆招聘数据2.csv')
三结果分析可视化部分
1.工资水平分析
如一家公司给出的报酬是6-8千/月,则我们认为工资水平是7千/月
import pandas as pd
df = pd.read_csv('51job重庆招聘数据2.csv',encoding="utf-8")
"---工资水平分析---"
money=df['工资水平']
print(money.describe())
平均工资9304元。我快拖后腿啦。被灰心,能把招聘信息放在求职网上的公司都是好公司。所有平均工资偏高。

在表格里面查找最高工资的是什么单位,干什么的。
项目经理300-450万/年。5-7年工作经验。招聘的是CEO。

import pandas as pd
import matplotlib.pyplot as plt
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
df = pd.read_csv('51job重庆招聘数据2.csv',encoding="utf-8")
#频率分析,各阶段工资占比
money1=df[df['工资水平']<6000]['position'].count()/len(df) #小于6000的占比
money2=df[(df['工资水平']>=6000) &(df['工资水平']<10000)]['position'].count()/len(df) #大于6000,小于10000的占比
money3=df[(df['工资水平']>=10000) &(df['工资水平']<15000)]['position'].count()/len(df) #大于10000,小于15000的占比
money4=df[(df['工资水平']>=15000) &(df['工资水平']<20000)]['position'].count()/len(df) #大于15000,小于20000的占比
money5=df[df['工资水平']>=20000]['position'].count()/len(df) #大于20000的占比
labels = ['小于6000', '大于6000小于10000', '大于10000小于15000', '大于15000小于20000','大于20000']
sizes = [money1,money2,money3,money4,money5]
explode = (0.1, 0.1, 0, 0,0)
plt.pie(sizes, explode=explode,labels=labels, autopct = '%1.1f%%',
shadow= False, startangle =90)
plt.title('工资分布情况')
plt.show()
由图可以看到70.8%的人月工资少于1万。等于说4个人中有3个人月工资少于1万。月工资大于1万5的人就是top10%啦。加油,小伙。

2.学历与工资关系
学历要求为大专(不要多想,应该是以上)
#大专工资水平
junior_collegey=df[df['degree_study']=='大专']
juniormoney1=junior_collegey[junior_collegey['工资水平']<6000]['position'].count()/len(junior_collegey) #小于6000的占比
juniormoney2=junior_collegey[(junior_collegey['工资水平']>=6000) &(junior_collegey['工资水平']<10000)]['position'].count()/len(junior_collegey) #大于6000,小于10000的占比
juniormoney3=junior_collegey[(junior_collegey['工资水平']>=10000) &(junior_collegey['工资水平']<15000)]['position'].count()/len(junior_collegey) #大于10000,小于15000的占比
juniormoney4=junior_collegey[(junior_collegey['工资水平']>=15000) &(junior_collegey['工资水平']<20000)]['position'].count()/len(junior_collegey) #大于15000,小于20000的占比
juniormoney5=junior_collegey[junior_collegey['工资水平']>=20000]['position'].count()/len(junior_collegey) #大于20000的占比
juniormean=df[df['degree_study']=='大专']['工资水平'].mean()#平均工资
labels = ['小于6000', '大于6000小于10000', '大于10000小于15000', '大于15000小于20000','大于20000']
sizes = [juniormoney1,juniormoney2,juniormoney3,juniormoney4,juniormoney5]
explode = (0.1, 0.1, 0, 0,0)
plt.pie(sizes, explode=explode,labels=labels, autopct = '%1.1f%%',
shadow= False, startangle =90)
plt.title('大专工资分布情况,大专平均工资为{0}'.format(juniormean))
plt.show()
大专77.3%的人月收入低于1万,平均月工资8464

本科。本科的代码直接将大专代码中的大专修改为本科即可
本科62.1%的人月收入低于1万,平均工资10487

硕士
硕士64%的人月收入低于1万,平均工资12408。

博士
博士月收入就没有低于1万的,平均工资23022。

读书还是有好处,平均工资,本科比大专多2000,硕士比本科多2000,博士是硕士的2倍。
读书对于我们这些穷苦人出身的还是最好的出路。
3.公司性质与工资关系
民营公司
nature_company=df[df['nature_company']=='民营公司']
money1=nature_company[nature_company['工资水平']<6000]['position'].count()/len(nature_company) #小于6000的占比
money2=nature_company[(nature_company['工资水平']>=6000) &(nature_company['工资水平']<10000)]['position'].count()/len(nature_company) #大于6000,小于10000的占比
money3=nature_company[(nature_company['工资水平']>=10000) &(nature_company['工资水平']<15000)]['position'].count()/len(nature_company) #大于10000,小于15000的占比
money4=nature_company[(nature_company['工资水平']>=15000) &(nature_company['工资水平']<20000)]['position'].count()/len(nature_company) #大于15000,小于20000的占比
money5=nature_company[nature_company['工资水平']>=20000]['position'].count()/len(nature_company) #大于20000的占比
mean=df[df['nature_company']=='民营公司']['工资水平'].mean()#平均工资
labels = ['小于6000', '大于6000小于10000', '大于10000小于15000', '大于15000小于20000','大于20000']
sizes = [money1,money2,money3,money4,money5]
explode = (0.1, 0.1, 0, 0,0)
plt.pie(sizes, explode=explode,labels=labels, autopct = '%1.1f%%',
shadow= False, startangle =90)
plt.title('民营公司工资分布情况,平均工资为{0}'.format(mean))
plt.show()
民营公司73.1%月收入低于1万,平均月收入9156

合资公司
合资公司73%月收入低于1万,平均月收入8891

上市公司
上市公司64.3%月收入低于1万,平均月收入10038

外资公司和非欧美外资公司
shuju=['外资','外资(非欧美)','外资(欧美)']
nature_company=df[df['nature_company'].isin(shuju)]
money1=nature_company[nature_company['工资水平']<6000]['position'].count()/len(nature_company) #小于6000的占比
money2=nature_company[(nature_company['工资水平']>=6000) &(nature_company['工资水平']<10000)]['position'].count()/len(nature_company) #大于6000,小于10000的占比
money3=nature_company[(nature_company['工资水平']>=10000) &(nature_company['工资水平']<15000)]['position'].count()/len(nature_company) #大于10000,小于15000的占比
money4=nature_company[(nature_company['工资水平']>=15000) &(nature_company['工资水平']<20000)]['position'].count()/len(nature_company) #大于15000,小于20000的占比
money5=nature_company[nature_company['工资水平']>=20000]['position'].count()/len(nature_company) #大于20000的占比
mean=df[df['nature_company'].isin(shuju)]['工资水平'].mean()#平均工资
labels = ['小于6000', '大于6000小于10000', '大于10000小于15000', '大于15000小于20000','大于20000']
sizes = [money1,money2,money3,money4,money5]
explode = (0.1, 0.1, 0, 0,0)
plt.pie(sizes, explode=explode,labels=labels, autopct = '%1.1f%%',
shadow= False, startangle =90)
plt.title('外资公司工资分布情况,平均工资为{0}'.format(mean))
plt.show()
外资公司 67%的人月收入低于1万,平均月收入9225

国企
国企56%的人月收入低于1万,平均月收入10462

4.查看公司地址分布
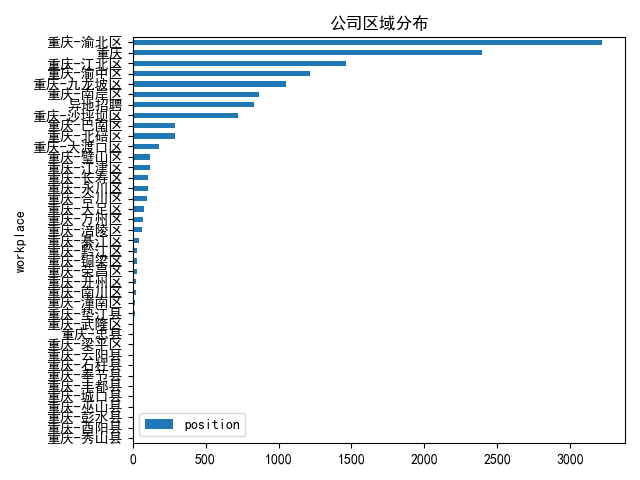
workplace=df.groupby('workplace').count()
workplace=workplace['position'].sort_values()
workplace=pd.DataFrame(workplace)
workplace.plot(kind='barh')
plt.title('公司区域分布')
plt.show()
公司还是集中在主城。一些小县城,招聘信息只有个位数。
5.工作描述词云图
text = df['岗位描述词']
text = (' '.join(map(str, text))).split(' ')
#print(text)
from collections import Counter
from wordcloud import WordCloud
def generate_wordcloud(tup):
wordcloud = WordCloud(background_color='white',
font_path='simhei.ttf',
max_words=50, max_font_size=40,
random_state=42
).generate(str(tup))
return wordcloud
most300 = Counter(text).most_common(300)#10个高频词
plt.imshow(generate_wordcloud(most300), interpolation="bilinear")
plt.title("Top 300", fontsize=30)
plt.show()
没有进行停用词去除(主要是想减少工作量),词云图得到的信息不是很满意。
从停用词中发现:公司对沟通能力,经验,学历,组织能力,专业相关 比较看重。


通过对这篇文章,我了解到啦我处于哪个段位啦。算是比较优秀吧
小伙子加油

作者:电气余登武。原创属实不易,请一键三连(点赞,收藏,关注)再走