文章目录
本篇博客仅作为学习交流,不可用于商业用途
1 网站分析
猫眼电影的地址是“https://maoyan.com/board/4?offset=20”,其中offset表示偏移量,offset=20表示你要爬取排名第21到第30的电影。所以要构造一个变量BASE_URL = ‘http://maoyan.com/board/4?offset=’,用于拼接整个爬取的链接。猫眼的反爬虫机制很多,2.3节会介绍如何解决反爬虫的方法。
2 代码完成
2.1 导包&定义变量
首先,导包,并且定义全局变量
import requests
import logging
import pymongo
from pyquery import PyQuery as pq
from urllib.parse import urljoin
import multiprocessing
# 定义日志级别
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s: %(message)s')
# 根路径
BASE_URL = 'http://maoyan.com/board/4?offset='
# 总页数
TOTAL_PAGE = 10
# MongoDB配置信息
MONGO_CONNECTION_STRING = 'mongodb://localhost:27017'
MONGO_DB_NAME = 'movies'
MONGO_COLLECTION_NAME = 'maoyan'
client = pymongo.MongoClient(MONGO_CONNECTION_STRING)
db = client[MONGO_DB_NAME]
collection = db[MONGO_COLLECTION_NAME]
2.2 拼接url
# 拼接url,调用get_html(url)
def get_index(page):
url = f'{BASE_URL}{page}'
return get_html(url)
2.3 爬取HTML
猫眼电影网的反爬虫机制很多,这里可以通过添加User-Agent和cookie来解决,你需要添加自己浏览器的cookie,如下图所示:
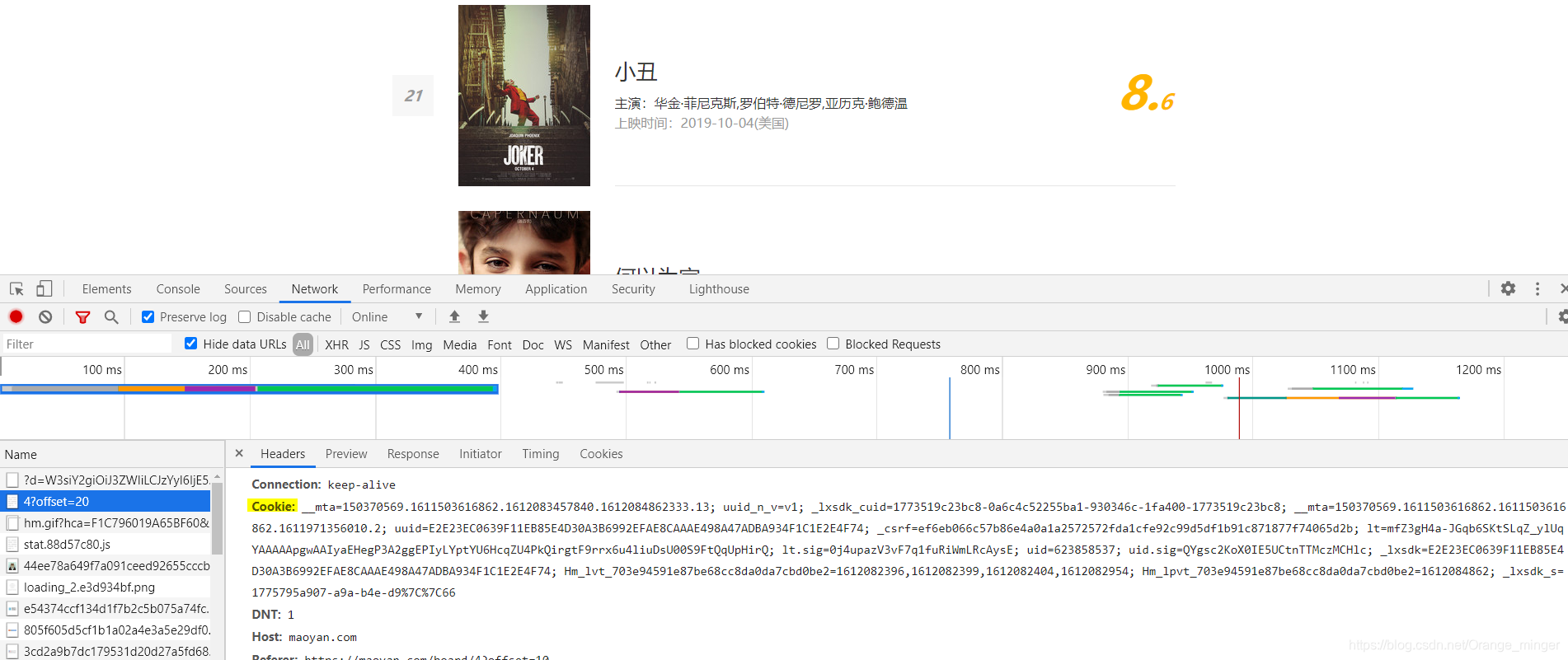
同时,你要用自己的浏览器浏览几次猫眼网,能够遇到验证码验证就最好了。
def get_html(url):
logging.info('scraping %s...', url)
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.3987.122 Safari/537.36",
"Cookie": '__mta=150370569.1611503616862.1612082954043.1612082957903.9; uuid_n_v=v1; _lxsdk_cuid=1773519c23bc8-0a6c4c52255ba1-930346c-1fa400-1773519c23bc8; __mta=150370569.1611503616862.1611503616862.1611971356010.2; uuid=E2E23EC0639F11EB85E4D30A3B6992EFAE8CAAAE498A47ADBA934F1C1E2E4F74; _csrf=ef6eb066c57b86e4a0a1a2572572fda1cfe92c99d5df1b91c871877f74065d2b; lt=mfZ3gH4a-JGqb6SKtSLqZ_ylUqYAAAAApgwAAIyaEHegP3A2ggEPIyLYptYU6HcqZU4PkQirgtF9rrx6u4liuDsU00S9FtQqUpHirQ; lt.sig=0j4upazV3vF7q1fuRiWmLRcAysE; uid=623858537; uid.sig=QYgsc2KoX0IE5UCtnTTMczMCHlc; _lxsdk=E2E23EC0639F11EB85E4D30A3B6992EFAE8CAAAE498A47ADBA934F1C1E2E4F74; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1612082396,1612082399,1612082404,1612082954; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1612082957; _lxsdk_s=1775795a907-a9a-b4e-d9%7C%7C31'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
logging.info('scraping %s successfully', url)
return response.text
logging.error('get invalid status code %s while scraping %s', response.status_code, url)
except requests.RequestException:
logging.error('error occurred while scraping %s', url, exc_info=True)
2.4 解析HTML
# 解析html
def parse_html(response):
doc = pq(response)
divs = doc('.movie-item-info').items()
for div in divs:
name = div.find(".name>a").attr("title")
url = urljoin(BASE_URL, div.find(".name>a").attr('href'))
star = div.find(".star").text()
release_time = div.find(".releasetime").text()
yield {
'name': name,
'url': url,
'star': star,
'release_time': release_time
}
2.5 保存结果
第 1 个参数是查询条件,即根据 name 进行查询;
第 2 个参数是 data 对象本身,也就是所用的数据,这里我们用 $set 操作符表示更新操作;
第 3 个参数很关键,这里实际上是 upsert 参数,如果把这个设置为 True,则可以做到存在即更新,不存在即插入的功能,更新会根据第一个参数设置的 name 字段,所以这样可以防止数据库中出现同名的电影数据。
# 将数据保存到MongoDB
def save_data(data):
if data is not None:
collection.update_one({
'name': data.get('name')
}, {
'$set': data
}, upsert=True)
else:
logging.info("save_data fail... because data is none")
2.6 多线程爬取
# 多线程爬取
def multiprocess(offset):
response = get_index(offset)
# print(response)
results = parse_html(response) # 得到包含元组的迭代器
for result in results:
save_data(result)
2.7 主函数
if __name__ == '__main__':
# 开启多线程爬取
pool = multiprocessing.Pool(8)
offset = (0, 10, 20, 30, 40, 50, 60, 70, 80, 90)
pool.map(multiprocess, offset)
pool.close()
pool.join()
# 查看爬取结果
results = collection.find()
for result in results:
print(result)
print(collection.find().count())
2.8 结果展示
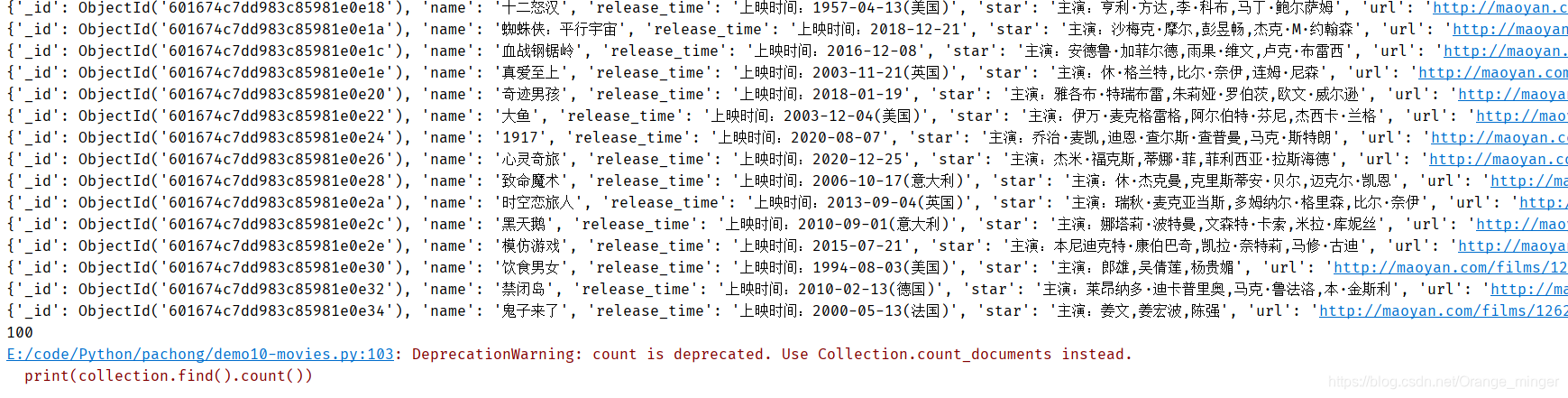
3、完整代码
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# Author: RuiMing Lin
# DateTime: 2021/01/25 15:56
# Description: 使用pyquery爬取猫眼电影网
import requests
import logging
import re
import pymongo
from pyquery import PyQuery as pq
from urllib.parse import urljoin
import multiprocessing
# 定义日志级别
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s: %(message)s')
# 根路径
BASE_URL = 'http://maoyan.com/board/4?offset='
# 总页数
TOTAL_PAGE = 10
# MongoDB配置信息
MONGO_CONNECTION_STRING = 'mongodb://localhost:27017'
MONGO_DB_NAME = 'movies'
MONGO_COLLECTION_NAME = 'maoyan'
client = pymongo.MongoClient(MONGO_CONNECTION_STRING)
db = client[MONGO_DB_NAME]
collection = db[MONGO_COLLECTION_NAME]
# 爬取html
def get_html(url):
logging.info('scraping %s...', url)
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.3987.122 Safari/537.36",
"cookie": '__mta=150370569.1611503616862.1612082954043.1612082957903.9; uuid_n_v=v1; _lxsdk_cuid=1773519c23bc8-0a6c4c52255ba1-930346c-1fa400-1773519c23bc8; __mta=150370569.1611503616862.1611503616862.1611971356010.2; uuid=E2E23EC0639F11EB85E4D30A3B6992EFAE8CAAAE498A47ADBA934F1C1E2E4F74; _csrf=ef6eb066c57b86e4a0a1a2572572fda1cfe92c99d5df1b91c871877f74065d2b; lt=mfZ3gH4a-JGqb6SKtSLqZ_ylUqYAAAAApgwAAIyaEHegP3A2ggEPIyLYptYU6HcqZU4PkQirgtF9rrx6u4liuDsU00S9FtQqUpHirQ; lt.sig=0j4upazV3vF7q1fuRiWmLRcAysE; uid=623858537; uid.sig=QYgsc2KoX0IE5UCtnTTMczMCHlc; _lxsdk=E2E23EC0639F11EB85E4D30A3B6992EFAE8CAAAE498A47ADBA934F1C1E2E4F74; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1612082396,1612082399,1612082404,1612082954; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1612082957; _lxsdk_s=1775795a907-a9a-b4e-d9%7C%7C31'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
logging.info('scraping %s successfully', url)
return response.text
logging.error('get invalid status code %s while scraping %s', response.status_code, url)
except requests.RequestException:
logging.error('error occurred while scraping %s', url, exc_info=True)
# 拼接url,调用get_html(url)
def get_index(page):
url = f'{BASE_URL}{page}'
return get_html(url)
# 解析html
def parse_html(response):
doc = pq(response)
divs = doc('.movie-item-info').items()
for div in divs:
name = div.find(".name>a").attr("title")
url = urljoin(BASE_URL, div.find(".name>a").attr('href'))
star = div.find(".star").text()
release_time = div.find(".releasetime").text()
# logging.info('get detail url %s', detail_url)
yield {
'name': name,
'url': url,
'star': star,
'release_time': release_time
}
# 将数据保存到MongoDB
def save_data(data):
if data is not None:
collection.update_one({
'name': data.get('name')
}, {
'$set': data
}, upsert=True)
else:
logging.info("save_data fail... because data is none")
# 多线程爬取
def multiprocess(offset):
response = get_index(offset)
# print(response)
results = parse_html(response) # 得到包含元组的迭代器
for result in results:
save_data(result)
if __name__ == '__main__':
# 开启多线程爬取
pool = multiprocessing.Pool(8)
offset = (0, 10, 20, 30, 40, 50, 60, 70, 80, 90)
pool.map(multiprocess, offset)
pool.close()
pool.join()
# 查看爬取结果
results = collection.find()
for result in results:
print(result)
print(collection.find().count())