前言
作为当前先进的深度学习目标检测算法YOLOv8,已经集合了大量的trick,但是还是有提高和改进的空间,针对具体应用场景下的检测难点,可以不同的改进方法。此后的系列文章,将重点对YOLOv8的如何改进进行详细的介绍,目的是为了给那些搞科研的同学需要创新点或者搞工程项目的朋友需要达到更好的效果提供自己的微薄帮助和参考。由于出到YOLOv8,YOLOv7、YOLOv5算法2020年至今已经涌现出大量改进论文,这个不论对于搞科研的同学或者已经工作的朋友来说,研究的价值和新颖度都不太够了,为与时俱进,以后改进算法以YOLOv7为基础,此前YOLOv5改进方法在YOLOv7同样适用,所以继续YOLOv5系列改进的序号。另外改进方法在YOLOv5等其他目标检测算法同样可以适用进行改进。希望能够对大家有帮助。链接:https://pan.baidu.com/s/1fN07LssywnP_CFDZGPcK7A
提取码:关注后私信
一、解决问题
这篇文章提出的方法主要用并行子网络代替一层层叠加。这有助于有效减少深度同时保持高性能。尝试用提出的方法改进目标检测算法中,提升目标检测效果。
二、基本原理
原文链接:Linear Context Transform Block (arxiv.org)
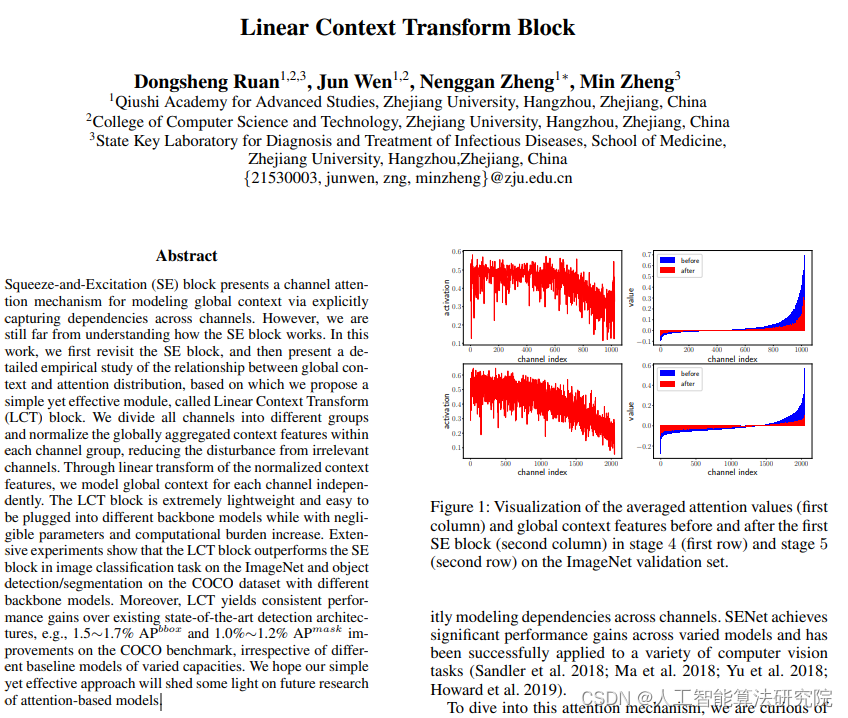
原文摘要:本文介绍了Squeeze-and-Excitation(SE)块,它通过明确捕捉通道之间的依赖关系来建模全局上下文,从而提供了一种通道注意机制。然而,我们对SE块的工作原理还了解得很少。本研究首先重新审视了SE块,然后基于全局上下文和注意力分布之间的关系进行了详细的实证研究,基于此提出了一种简单而有效的模块,称为线性上下文转换(LCT)块。我们将所有通道分成不同的组,并在每个通道组内对全局聚合的上下文特征进行归一化处理,减少了来自无关通道的干扰。通过对归一化上下文特征进行线性变换,我们可以独立地为每个通道建模全局上下文。LCT块非常轻量级且易于插入不同的主干模型,同时增加的参数和计算负担几乎可以忽略不计。大量实验表明,在ImageNet上的图像分类任务以及COCO数据集上的目标检测/分割任务中,LCT块优于SE块,不论使用不同容量的主干模型。此外,LCT在现有最先进的检测架构上都取得了一致的性能提升,例如在COCO基准测试中,APbbox和APmask分别提高了1.51.7%和1.0%1.2%,不论使用不同容量的基线模型。我们希望我们的简单而有效的方法能为基于注意力的模型的未来研究提供一些启示。

三、添加方法
原论文提出的部分参考源码如下所示:
class LCT(nn.Module):
def __init__(self, channels, groups, eps=1e-5):
super().__init__()
assert channels % groups == 0, "Number of channels should be evenly divisible by the number of groups"
self.groups = groups
self.channels = channels
self.eps = eps
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.w = nn.Parameter(torch.ones(channels))
self.b = nn.Parameter(torch.zeros(channels))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
batch_size = x.shape[0]
y = self.avgpool(x).view(batch_size, self.groups, -1)
mean = y.mean(dim=-1, keepdim=True)
mean_x2 = (y ** 2).mean(dim=-1, keepdim=True)
var = mean_x2 - mean ** 2
y_norm = (y - mean) / torch.sqrt(var + self.eps)
y_norm = y_norm.reshape(batch_size, self.channels, 1, 1)
y_norm = self.w.reshape(1, -1, 1, 1) * y_norm + self.b.reshape(1, -1, 1, 1)
y_norm = self.sigmoid(y_norm)
return x * y_norm.expand_as(x)
改进后运行的网络层数以及参数如下所示,博主是在NWPU VHR-10遥感数据集进行训练测试,实验是有提升效果的。具体获取办法可私信获取改进后的YOLO项目百度链接。
四、总结
预告一下:下一篇内容将继续分享深度学习算法相关改进方法。有兴趣的朋友可以关注一下我,有问题可以留言或者私聊我哦
PS:该方法不仅仅是适用改进YOLOv5,也可以改进其他的YOLO网络以及目标检测网络,比如YOLOv7、v6、v4、v3,Faster rcnn ,ssd等。
最后,有需要的请关注私信我吧。关注免费领取深度学习算法学习资料!