1.什么是GAN?
GAN 模型中的两位博弈方分别由生成式模型(generative model)和判别式模型(discriminative model)充当。
- 生成模型 G 捕捉样本数据的分布,用服从某一分布(均匀分布,高斯分布等)的噪声 z 生成一个类似真实训练数据的样本,追求效果是越像真实样本越好;
- 判别模型 D 是一个二分类器,估计一个样本来自于训练数据(而非生成数据)的概率,如果样本来自于真实的训练数据,D 输出大概率,否则,D 输出小概率。
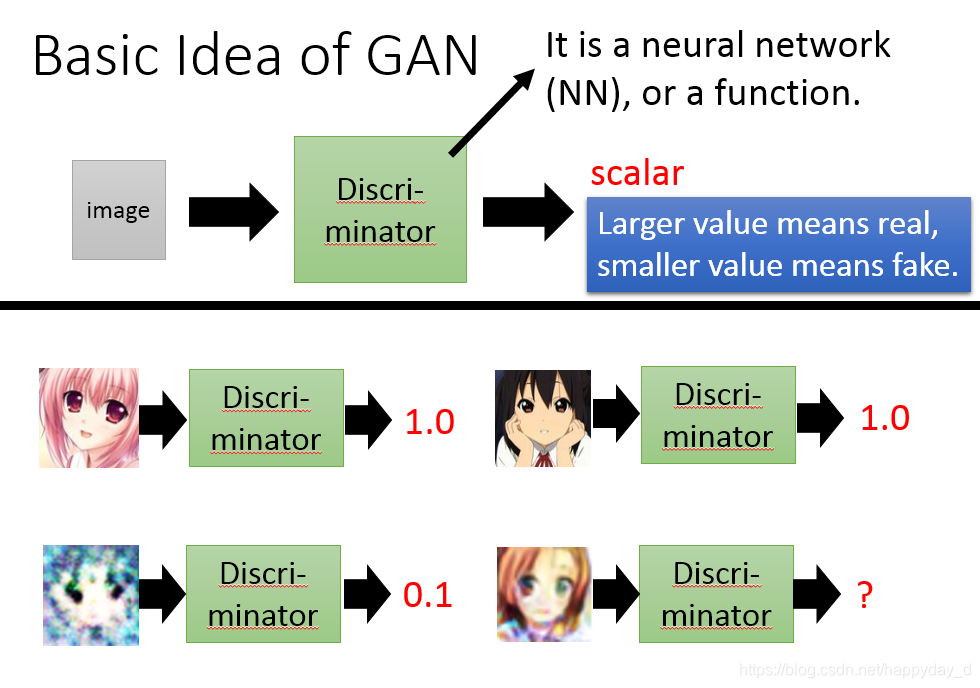
如下图二次元人物生成过程,上图为Generator,给出一个向量,经过Generator产生出一个图像,给出不同的向量可以得到不同的图像,存在一个问题是产生的图像是否接近真实的图像,此时需Discriminator来判定,如下图,真实的图像D网络给出较高的分数,而不真实的图像给出较低的分数,最终的目的是G网络产生的图像D网络也能给出很高的分数。
输入向量的每一维都代表一些特征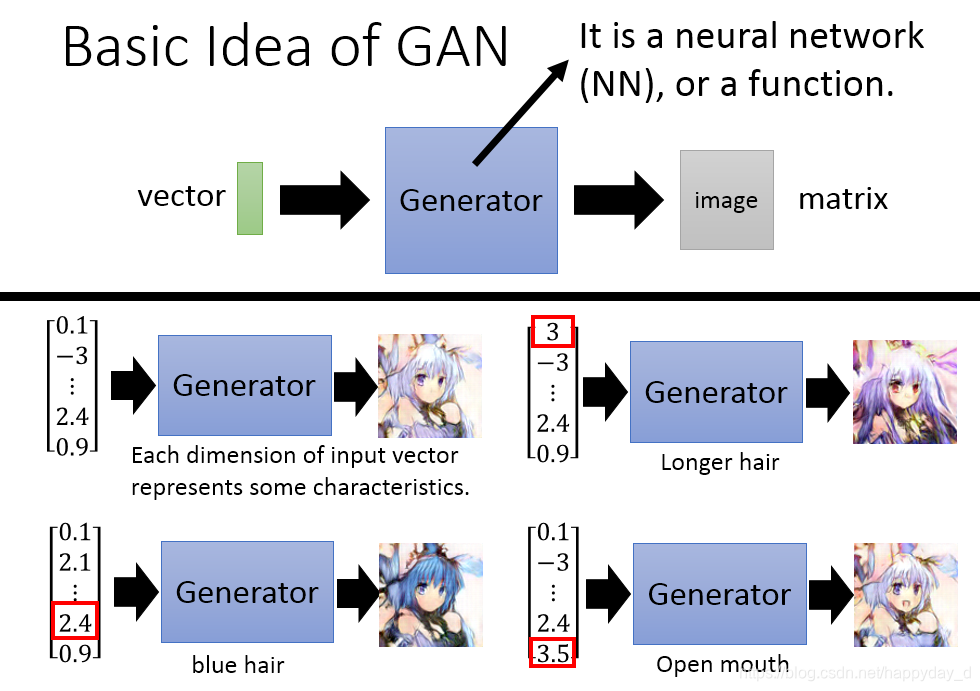
2.GAN网络训练?
以上面二次元图像生成为例说明,G(Generator)和D(Discriminator)
- G作用是接收一个向量Z(随机噪声),通过G生成图像,记做G(Z);
- D作用是判别一张图像是否是“真实的”。输入是X,X表示一张真实图像,则D(X)表示真实图像的概率,为1表示100%的真实的图像,而输出0,表示不是真实的图像。
训练过程中,固定一方,更新另一方的网络权重,交替迭代,在这个过程中,双方都极力的优化自己的网络,从而形成竞争对抗,直到双方达到一个动态的平衡。理想情况下,最后的结果是G生成的图像和真实的图像非常相似,D网络难以区分真实的图像和G生成的图像,此时D(G(Z)) = 0.5。

公式说明:
- x表示真实的图像,z表示输入的G网络噪声,G(z)表示G网络生成的图像。
- D(x)表示真实输入的概率,D(G(z))表示D网络判断G生成的图像是否真实的概率;
- G的目的:D(G(z))是D网络判断G生成的图片是否真实的概率,G应该希望自己生成的图片“越接近真实越好”。也就是说,G希望D(G(z))尽可能得大,这时V(D, G)会变小。因此我们看到式子的最前面的记号是min_G。
- D的目的:D的能力越强,D(x)应该越大,D(G(x))应该越小。这时V(D,G)会变大。因此式子对于D来说是求最大(max_D)。
论文中给出了利用随机梯度下降法如何训练网络D和G:
- 先训练D,利用梯度上升,使损失函数越大越好,
- 再训练G,利用梯度下降算法,使损失函数越小越好。
3.Auto-encoder VAE 和GAN
auto-encoder(自编码器)
结构如下,训练一个 encoder,把 input 转换成 code,然后训练一个 decoder,把 code 转换成一个 image,然后计算得到的 image 和 input 之间的 MSE(mean square error),训练完这个 model 之后,取出后半部分 NN Decoder,输入一个随机的 code,就能 generate 一个 image。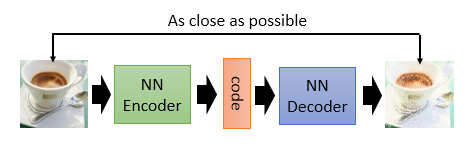
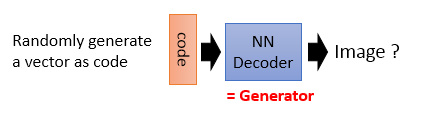
将Auto-encoder的后一部分拿出来,随机输入向量,即上述描述的Generator,但输入向量怎么设定?没有什么标准。

针对上述问题,提出了VAE,如下:
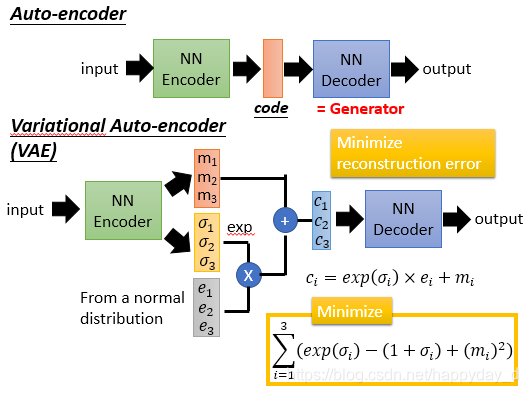
上述的两个生成模型,其实有一个非常严重的弊端。比如 VAE:Variational Auto-encoder(变分自编码器),它生成的 image 是希望和 input 越相似越好,但是 model 是如何来衡量这个相似呢?model 会计算一个 loss,采用的大多是 MSE,即每一个像素上的均方差。loss 小真的表示相似嘛?
如下图,上述一行只相差一个像素,得到的MSE最小,但结果并不是我们满意的。
上述两种生成网络之所以对产生图像不能达到满意效果是由于网络只关注局部信息而未考虑全局的信息,若需要考虑全局信息需要更深的网络结构;
GAN网络的优缺点:
Generator:可以产生局部图像,但不能顾及图像的不同部分之间的关系;
Disciminator:考虑的是全局图像,但不能产生图像
原文:https://blog.csdn.net/happyday_d/article/details/85406134