文章目录
一、功能总览
1.1 项目介绍
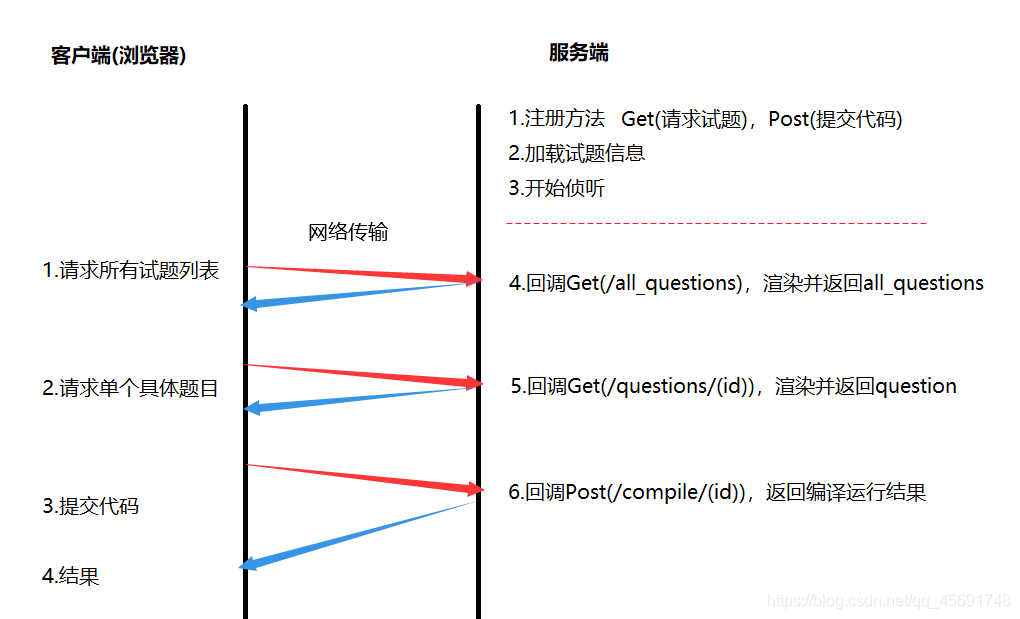
- 实现一个类似牛客、leetcode的在线OJ系统,用户可以选择试题,并提交代码,通过网络传输,上传到服务器后台,后台对代码进行编译运行,并把测试结果反馈给客户端浏览器
1.2 环境搭建
- 利用cpp-httplib开源库:搭建一个http服务,不需要关心 tcp 和 http 的建立和 url 解析过程,只要注册对应的方法。
克隆仓库:git clone https://gitee.com/iqxg/cpp-httplib.git
- 升级gcc,cpp-httplib库依赖 C++ 11 中的正则表达式,而 Centos7 自带的 gcc4.8 正则表达式有 bug。
1.下载高版本gcc:bash中输入以下命令
sudo yum -y install centos-release-scl
sudo yum -y install devtoolset-7-gcc devtoolset-7-gcc-c++ devtoolset-7-binutils
2.设置默认启动高版本gcc
打开文件
vim ~/.bash_profile
在最后添加:
scl enable devtoolset-7 bash
重启gcc
source ~/.bash_profile
- 下载Jsoncpp
yum install jsoncpp
yum install jsoncpp-devel
- 下载谷歌ctemplate,boost
sudo yum install -y snappy-devel boost-devel zlib-devel.x86_64 python-pip
sudo pip install BeautifulSoup4
git clone https://gitee.com/HGtz2222/ThirdPartLibForCpp.git
cd ./ThirdPartLibForCpp/el7.x86_64/
sh install.sh
1.3 cpp-httplib库测试
#include <iostream>
#include <string>
#include "httplib.h"
int main()
{
// 1.创建一个Server类对象
httplib::Server http_svr;
// 2.注册Get方法
http_svr.Get("/index", [](const httplib::Request& req, httplib::Response& resp){
std::cout << req.method << " " << req.path << " " << req.version << std::endl;
std::string html = "<html>this is Linux~~<html>";
resp.set_content(html, "text/html");
});
http_svr.listen("0.0.0.0", 17878);
return 0;
}
运行结果:打开浏览器输入IP:port
cpp-httplib源码分析:
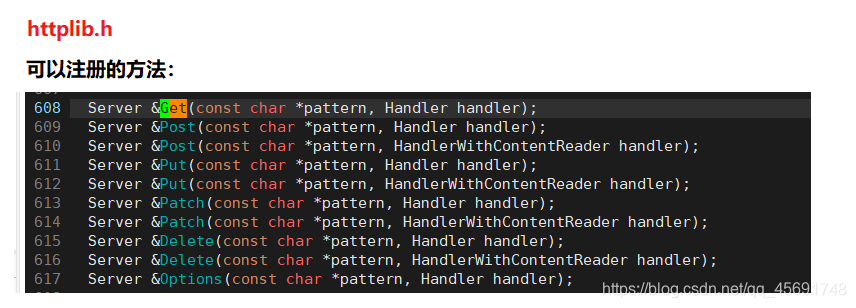
我们只用到了:Get:获取资源,Post:传输实体主体
Get方法具体:
Server &Get(const char *pattern, Handler handler);
pattern:注册的回调函数资源路径,只有资源路径相同才会回调该函数
Handler:函数指针
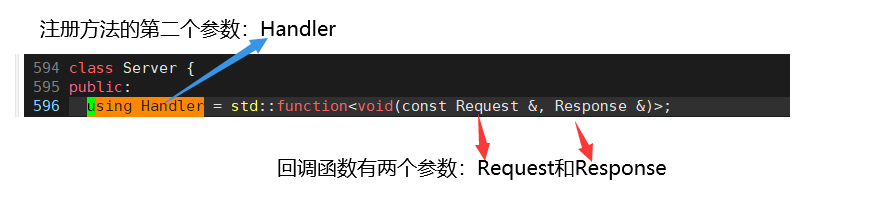
Resquset:客户端的请求
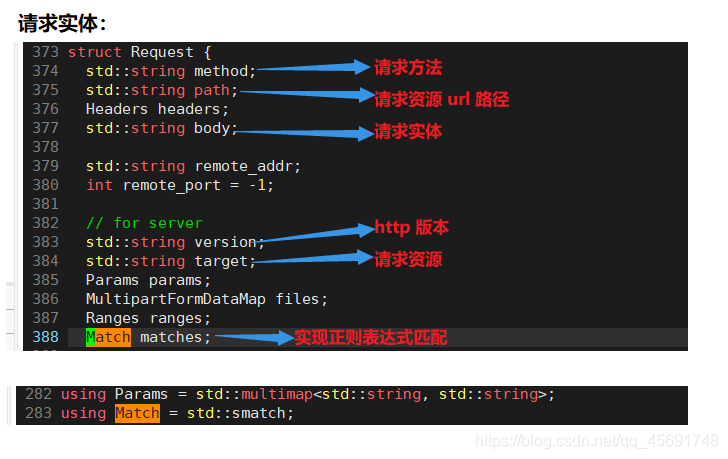
Response:服务端的响应
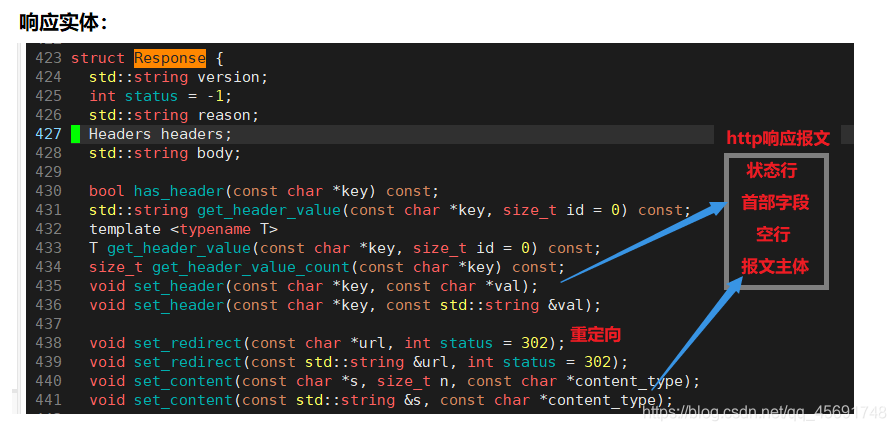
1.4 细分需求

二、核心模块
2.1 数据管理模块
-
题目存储:
- 题目数据存储在本地文件中,约定目录的格式为:id + 题名 + 难度 + 路径,目录存储在 ./oj_data/oj_config_cfg中。约定题目的 id 就是存储该试题的详细信息,详细信息:题目描述:desc.txt,预定义的头:header.cpp,测试用例:tail.cpp
-
对外提供接口:
oj_model.hpp:
struct Questions
{
std::string id_; // 题目id
std::string title_; // 题名
std::string comp_; // 题目难度
std::string path_; // 题目路径
std::string desc_; // 题目描述信息
std::string header_; // 预定义的头文件
std::string tail_; // 测试用例
};
// 从文件中加载数据到内存中,用unordereed_map组织数据
bool Load();
// 获取试题目录,出参用数组保存:vector<Questions>
bool GetAllQuestions();
// 获取单个试题详细信息,出参自定义类型Questions
bool GetOneQues();
源码:
2.2 html页面管理模块
- 浏览器接收到的数据如何展示?
- 用Google开源的html模板分离技术ctemplate
- 准备 html 模板,在回复 html响应时,对模板填充数据
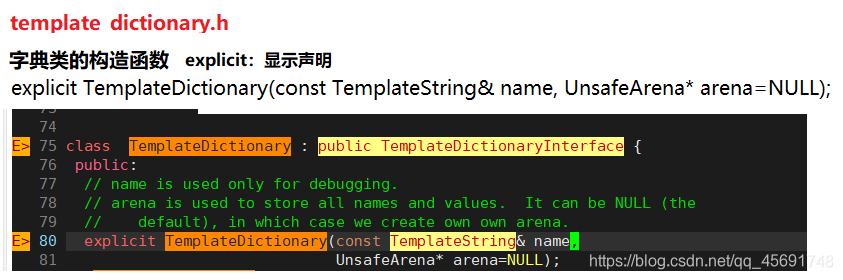
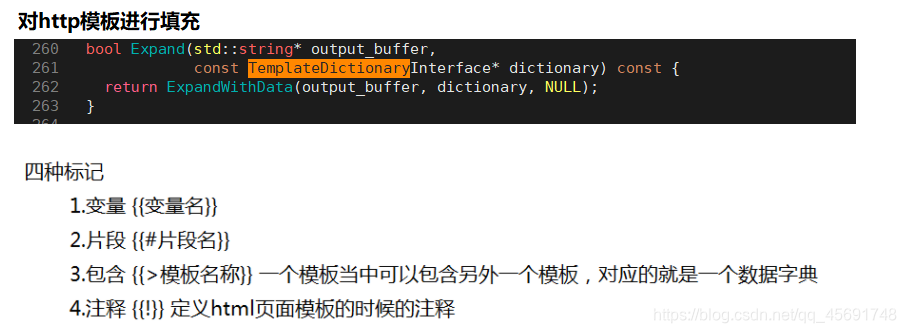
- ctemplate源码分析:

- 对外接口
oj_view.hpp:
//根据所有的题目列表信息,生成HTML, 供网站首页显示
static void FillInAllQuestions(const std::vector<Question>& all_questions,std::string* html);
//根据指定的question, 生成HTML
static void FillInOneQuestion(const Question& question,std::string* html);
//根据运行结果或编译出错的结果,构造生成HTML
static void FillInResponse(const Json::Value& Resp, std::string* html);
源码:
2.3 在线编译运行模块
- 设计思路:
- 将用户提交的代码和预定义的测试用例,写到文件中去
- 编译模块
- fork创建子进程
- 父进程进程等待,子进程程序替换:替换成g++程序编译code
- 获取编译结果:将标准错误重定向到文件中
- 运行模块
- 检查是否生成可执行程序
- fork创建子进程,子进程替换成编译出来的可执行程序
- 获取运行结果:将标准输出和标准错误重定向到文件中
- 将结果和预定义 html 模板结合,返回给客户端
- 对外接口
oj_compile.hpp
// 编译并运行
static void CompileAndRun(Json::Value Req, Json::Value* Resp)
// 编译模块
static bool Compile(const std::string& filename)
// 运行模块
static int Run(const std::string& filename)
// 清理创建出来的文件
static void Clean(const std::string& filename)
源码:
2.4 oj_server.cpp
#include <iostream>
#include <cstdio>
#include <json/json.h>
#include "httplib.h"
#include "oj_model.hpp"
#include "oj_view.hpp"
#include "oj_compile.hpp"
using namespace httplib;
int main()
{
Server svr;
OjModel model;
// 1.注册所有题目的资源路径
svr.Get("/all_questions", [&model](const Request &req, Response &resp){
std::vector<Questions> all_ques;
model.GetAllQuestions(&all_ques); // 获取所有题目信息
std::string html;
Oj_View::FillInAllQuestions(all_ques, &html); // 获取html页面
resp.set_content(html, "text/html"); // 设置响应体
});
// 2.注册单个题目的资源路径
svr.Get(R"(/question/(\d+))", [&model](const Request &req, Response &resp){
// 获取单个试题的信息
Questions question;
model.GetOneQues(req.matches[1], &question);
// 获取html页面
std::string html;
Oj_View::FillInOneQuestion(question, &html);
resp.set_content(html, "text/html");
});
// 3.注册提交代码并运行的路径
svr.Post(R"(/compile/(\d+))", [&model](const Request &req, Response &resp){
// 1.获取试题编号和内容
Questions question;
model.GetOneQues(req.matches[1], &question);
// 2.对浏览器的请求体进行切分,切分成key:value形式,再进行url解码
std::unordered_map<std::string, std::string> kv_map;
Urlcode::PraseBody(req.body, &kv_map);
//for (const auto it : kv_map)
//{
// std::cout << it.first << std::endl << it.second << std::endl;
//}
// 3.把code和预定义的头结合,创建出一个新的文件
std::string code = kv_map["code"];
std::string stdin = kv_map["stdin"];
Json::Value Req_Js;
Json::Value Resp_Js;
Req_Js["code"] = code + question.tail_;
Req_Js["stdin"] = stdin;
// 4.编译并运行用户提交的代码
Compiled::CompileAndRun(Req_Js, &Resp_Js);
// 5.根据不同的编译运行结果,返回响应
std::string html;
Oj_View::FillInResponse(Resp_Js, &html);
resp.set_content(html, "text/html");
});
// 设置逻辑根目录
svr.set_base_dir("./wwwroot");
// 打印日志信息
LOG(INFO, "listen_port") << ":18888" << std::endl;
svr.listen("0.0.0.0", 18888);
return 0;
}
源码:
三、其他模块
3.1 如何支持高并发?
- 会产生高并发嘛?
- cpp-httplib 底层用到了创建线程,接收不同浏览器的请求
- 如何保证高并发下线程安全?
- 整个程序中写文件时,文件的命名不能保证线程安全
- 因此用C++中线程安全的atomic
static std::string WriteTmpFile(const std::string& code)
{
// 1.为了区分不同客户端发来的代码,我们应按时间生成不同的文件名
// 2.光按时间进行区分,不能保证线程安全,高并发情况下会出现问题
static std::atomic_uint id(0);
std::string filename = "tmp_" + std::to_string(TimeUtil::GetTimeStampMs()) + "." + std::to_string(id);
id++;
// 3.创建一个文件,并且把code写入文件
FileUtil::file_write(Compiled::SrcPath(filename), code);
return filename;
}