HPA示例
参考
可以根据 CPU 利用率自动扩缩 ReplicationController、 Deployment、ReplicaSet 或 StatefulSet 中的 Pod 数量
# 运行 php-apache 服务器并暴露服务
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
replicas: 1
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
创建 Horizontal Pod Autoscaler
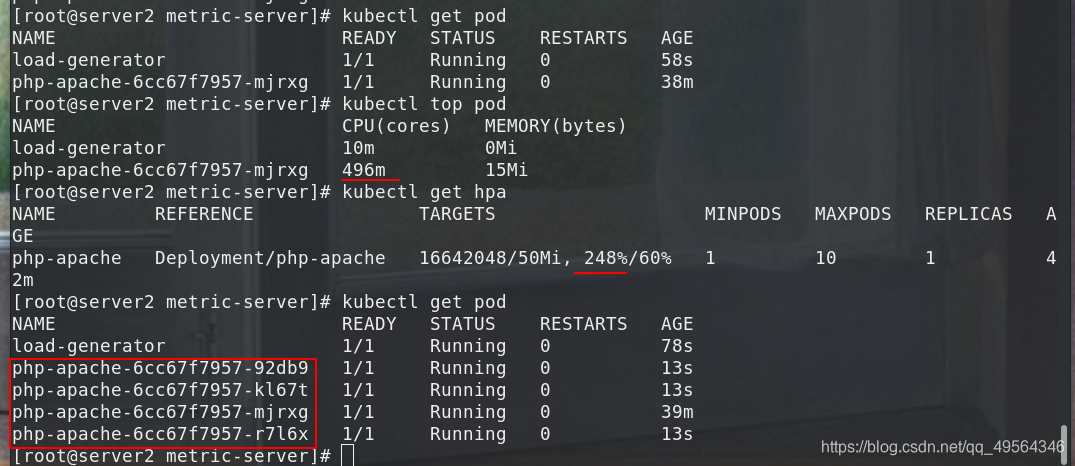
HPA 将(通过 Deployment)增加或者减少 Pod 副本的数量以保持所有 Pod 的平均 CPU 利用率在 50% 左右(由于每个 Pod 请求 200 毫核的 CPU,这意味着平均 CPU 用量为 100 毫核)
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
kubectl get hpa

增加负载
启动一个容器,并通过一个循环向 php-apache 服务器发送无限的查询请求
kubectl run -i --tty load-generator --rm --image=busybox --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
容器内存使用到达上限,开始扩容,Hpa会根据Pod的CPU使用率动态调节Pod的数量
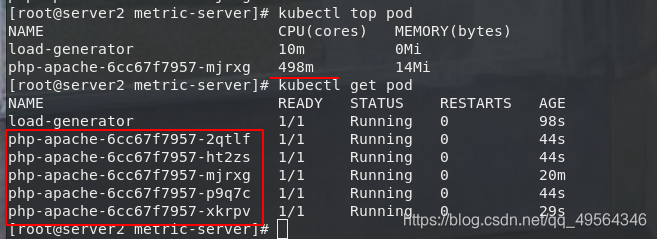
停止负载
终止load-generator
1.HPA伸缩过程:
收集HPA控制下所有Pod最近的cpu使用情况(CPU utilization)
对比在扩容条件里记录的cpu限额(CPUUtilization)
调整实例数(必须要满足不超过最大/最小实例数)
每隔30s做一次自动扩容的判断
CPU utilization的计算方法是用cpu usage(最近一分钟的平均值,通过metrics可以直接获取到)除以cpu request(这里cpu request就是我们在创建容器时制定的cpu使用核心数)得到一个平均值,这个平均值可以理解为:平均每个Pod CPU核心的使用占比。
2.HPA进行伸缩算法:
计算公式:TargetNumOfPods = ceil(sum(CurrentPodsCPUUtilization) / Target)
ceil()表示取大于或等于某数的最近一个整数
每次扩容后冷却3分钟才能再次进行扩容,而缩容则要等5分钟后。
当前Pod Cpu使用率与目标使用率接近时,不会触发扩容或缩容:
触发条件:avg(CurrentPodsConsumption) / Target >1.1 或 <0.9

# 多项度量指标
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
maxReplicas: 10
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
metrics:
- type: Resource
resource:
name: cpu
target:
averageUtilization: 60
type: Utilization
- type: Resource
resource:
name: memory
target:
averageValue: 50Mi
type: AverageValue