【机器学习】从随机过程到蒙特卡罗方法
1 理解随机过程
人类的主观能动性决定,为了改造世界,必须认识世界的发展规律。而所谓发展,实质上就是各种事物随着时间推移,不断运动变化的过程——从宏观的天体运动到微观的分子运动。在古典时期,牛顿的经典物理分析方法成功地描述了宏观运动世界,确定性是牛顿体系最大的特征——给定速度和加速度,运动轨迹随即可以建模确立。
在近代物理时期,牛顿体系的确定性似乎不够适用,因为真实世界的更多情况,是充满复杂而未知因素的运动。这些不确定的因素——噪音,对事物变化至关重要,例如微观世界的分子热运动、不确定性关系等。由于牛顿方法的确定性,这些不确定性领域的问题难以或不能应用经典物理方法。
因此,为了描述不确定性,引入了概率论与数理统计的一套方法。牛顿体系研究的经典过程指的是一个量随时间确定的变化;相应地,随机过程指的是一个量随时间可能的变化。在随机过程里,每一个时刻变化的方向都不确定,换言之,随机过程由一系列随机变量组成,每个时刻的系统状态都由一个或一组随机变量表述,整个随机过程的实现构成了概率空间的一个轨迹。在随机过程中,也有一套类似于经典过程中牛顿方法的理论武器,下面分点阐明。
1.1 概率空间
在不确定性领域,无非关心两件事:①有哪些可以实现的可能;②每种可能的数值大小。用概率空间(或称事件空间、态空间)描述①,用概率描述②。

所谓概率空间,是人类现有知识总和的近似。把我们用它描述已知的未知,而无法描述未知的未知,因为只有经过人类实践,能动地转化为知识后,才能对概率空间进行补充。通俗来讲,概率空间相当于“过往经验”。事实上,对未来的预测来源于过往经验,而沟通经验与未来的工具就是概率——所谓一件事发生可能性大小,就是这件事在历史中发生的频率大小。通过经验加上已知信息实现对未来预测的方式,就是贝叶斯方法。
1.2 分布函数
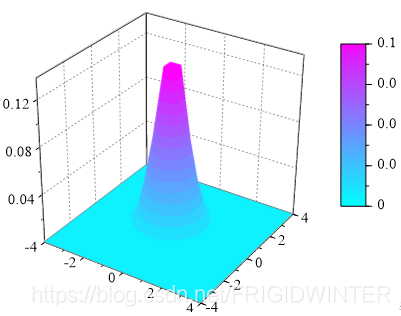
分布函数描述了概率空间与概率的对应关系,概率空间和概率是不确定性领域研究的关键和基础,因此分布函数的引入也具有深远意义:分布函数是提取随机过程内有效信息的第一手段和入口,而蒙特卡洛方法就是研究分布函数的武器。
例如图2所示的高斯分布 z ( x , y ) = 1 2 π e − ( x 2 + y 2 ) z\left( x,y \right) =\frac{1}{2\pi}e^{-\left( x^2+y^2 \right)} z(x,y)=2π1e−(x2+y2),其描述的概率空间为 Σ = { ( x , y ) ∣ x , y ∈ R } \varSigma =\left\{ \left( x,y \right) \,\,| x,y\in \mathbb{R} \right\} Σ={
(x,y)∣x,y∈R},将概率空间中的数据点代入分布函数,得到的值即为此数据点的实现概率,所以说分布函数指出了概率空间与概率的对应。
2 蒙特卡罗方法
随机过程问题中经常要研究一些随机变量的分布规律,比如分布函数的形式、分布参数估计等。利用解析方法来求解或利用大量实验来研究分布情况,通常耗资巨大或根本无法测量。为了解决这个难点,引入了蒙特卡洛方法(也称统计模拟方法)。
蒙特卡洛方法是利用随机数进行数值模拟的方法,它根据待求随机问题的变化规律和物理现象本身的统计规律人为地构造出一个合适的概率模型来模拟实际过程,并按照此概率模型进行大量的随机统计实验,使实验得出的某些统计参数正好是待求问题的解。
例1 求解积分 θ = ∫ a b f ( x ) d x \theta =\int\limits_a^b{f\left( x \right) dx} θ=a∫bf(x)dx
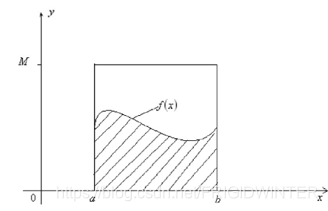
如图3所示,假设此积分的解析方法十分繁琐,借助蒙特卡洛方法来近似此积分数值。设在区间 [ a , b ] \left[ a,b \right] [a,b]上 x x x的概率密度函数是 p ( x ) p(x) p(x),则:
θ = ∫ a b f ( x ) p ( x ) p ( x ) d x = E [ f ( x ) p ( x ) ] a b = lim n → ∞ 1 n ∑ i = 1 n f ( x i ) p ( x i ) \theta =\int\limits_a^b{\frac{f\left( x \right)}{p\left( x \right)}\begin{array}{c} p\left( x \right) dx\\\end{array}}\\=E\left[ \frac{f\left( x \right)}{p\left( x \right)} \right] _{a}^{b}\\=\underset{n\rightarrow \infty}{\lim}\frac{1}{n}\sum_{i=1}^n{\frac{f\left( x_i \right)}{p\left( x_i \right)}} θ=a∫bp(x)f(x)p(x)dx=E[p(x)f(x)]ab=n→∞limn1i=1∑np(xi)f(xi)
基于概率密度函数 p ( x ) p(x) p(x)进行大量的随机抽样,将样本代入上面的求和式子中即可得到积分的近似解。其中 θ ≈ 1 n ∑ i = 1 n f ( x i ) p ( x i ) \theta \approx \frac{1}{n}\sum_{i=1}^n{\frac{f\left( x_i \right)}{p\left( x_i \right)}} θ≈n1∑i=1np(xi)f(xi), 称为蒙特卡洛方法的一般数学形式。
借助例1,阐明使用蒙特卡洛方法的几个关键点与步骤:
(i) 构造或描述概率过程
例1中的概率密度函数 p ( x ) p(x) p(x)就是所谓的概率过程,通常根据待求随机问题的变化规律和物理现象本身的统计规律人为构造,没有人为确定的先验分布将无法使用MC。
(ii) 从已构造的概率分布中抽样
按照步骤(i)构造的 p ( x ) p(x) p(x)进行随机抽样。最容易采样的分布是均匀分布 ,而其他的常见分布,无论离散还是连续(例如正态分布等),它们的随机样本都可以通过均匀分布 U ( 0 , 1 ) U\left( 0,1 \right) U(0,1)转换得到。
举例而言,Box-Muller变换实现了从均匀分布样本到标准二维正态分布样本的映射:
{ X = − 2 ln U 2 cos ( 2 π U 1 ) Y = − 2 ln U 2 sin ( 2 π U 1 ) 其中 U 1 , U 2 U ( 0 , 1 ) \left\{ \begin{array}{c} X=\sqrt{-2\ln U_2}\cos \left( 2\pi U_1 \right)\\ Y=\sqrt{-2\ln U_2}\sin \left( 2\pi U_1 \right)\\\end{array} \right. \,\, \text{其中}U_1, U_2~U\left( 0,1 \right) {
X=−2lnU2cos(2πU1)Y=−2lnU2sin(2πU1)其中U1,U2 U(0,1)
则 X X X、 Y Y Y服从均值为0,方差为1的正态分布。
对于不常见的复杂分布 ,难以通过均匀分布来实现相互映射,此时采用拒绝采样(Reject Sampling):首先选定一个容易采样的概率分布 q ( x ) q\left( x \right) q(x)(例如高斯分布),再选定一个常数 k k k,使得在概率空间中的所有样本点都满足 p ( x ) ⩽ k q ( x ) p\left( x \right) \leqslant kq\left( x \right) p(x)⩽kq(x);对概率分布 q ( x ) q\left( x \right) q(x)进行随机采样;对采样样本 x i x_i xi进行如下处理:计算 α i = p ( x ) k q ( x ) \alpha _i=\frac{p\left( x \right)}{kq\left( x \right)} αi=kq(x)p(x),同时采样均匀分布 U ( 0 , 1 ) U\left( 0,1 \right) U(0,1)生成 u i u_i ui,若 u i ⩽ α i u_i\leqslant \alpha _i ui⩽αi则接收本次样本,否则拒绝。下面从定性与定量两个角度说明拒绝采样合理性。
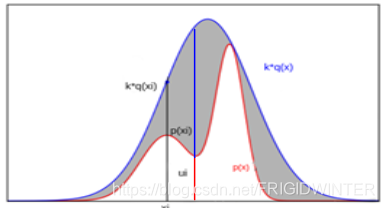
定性角度: α i = p ( x ) k q ( x ) \alpha _i=\frac{p\left( x \right)}{kq\left( x \right)} αi=kq(x)p(x)的意义是接受率,即基于分布 q ( x ) q\left( x \right) q(x)的采样样本 x x x被认为符合目标分布 p ( x ) p\left( x \right) p(x)的概率。如图4所示,若采样到样本值 x 0 x_0 x0则其接受率很低,因为直观地,分布 q ( x ) q\left( x \right) q(x)采样到 x 0 x_0 x0的概率高( x 0 x_0 x0处概率密度大)而分布 p ( x ) p\left( x \right) p(x)在此处概率密度并不大,因此 x 0 x_0 x0大概率被认为不符合分布 p ( x ) p\left( x \right) p(x)而拒绝采样。 u i u_i ui可以理解为均匀的概率因子, u i ⩽ α i u_i\leqslant \alpha _i ui⩽αi的条件可以理解为只有样本的接受概率足够大,才会被接受。几何上,如果样本落在灰色区域则拒绝本次样本,如果落在白色区域则接收本次样本。
定量角度:设目标分布为 π ( x ) \pi \left( x \right) π(x),简单采样分布为 q ( x ) q\left( x \right) q(x),且满足 π ( x ) ⩽ k q ( x ) \pi \left( x \right) \leqslant kq\left( x \right) π(x)⩽kq(x),需要证明 p ( x ∣ a c c e p t ) = π ( x ) p\left( x|accept \right) =\pi \left( x \right) p(x∣accept)=π(x),即被接受的采样样本符合目标分布情况。
由贝叶斯公式:
p ( x ∣ a c c e p t ) = p ( a c c e p t ∣ x ) p ( x ) p ( a c c e p t ) = x q ( x ) p ( a c c e p t ∣ x ) q ( x ) p ( a c c e p t ) p\left( x|accept \right) =\frac{p\left( accept|x \right) p\left( x \right)}{p\left( accept \right)}\xlongequal{x~q\left( x \right)}\frac{p\left( accept|x \right) q\left( x \right)}{p\left( accept \right)} p(x∣accept)=p(accept)p(accept∣x)p(x)x q(x)p(accept)p(accept∣x)q(x)
p ( a c c e p t ∣ x ) p\left( accept|x \right) p(accept∣x)是给定一个样本的条件下,被认为符合目标分布的概率,定性角度分析过,此条件概率即为接受率。先验概率 p ( a c c e p t ) p\left( accept \right) p(accept)由全概率公式展开:
p ( x ∣ a c c e p t ) = π ( x ) k q ( x ) q ( x ) ∫ π ( x ) k q ( x ) q ( x ) d x = π ( x ) ∫ π ( x ) d x = π ( x ) p\left( x|accept \right) =\frac{\frac{\pi \left( x \right)}{kq\left( x \right)}q\left( x \right)}{\int{\frac{\pi \left( x \right)}{kq\left( x \right)}q\left( x \right) dx}}\\=\frac{\pi \left( x \right)}{\int{\pi \left( x \right) dx}}\\=\pi \left( x \right) p(x∣accept)=∫kq(x)π(x)q(x)dxkq(x)π(x)q(x)=∫π(x)dxπ(x)=π(x)
综上所述,对于任意分布,我们就可以设计合适的 q ( x ) q\left( x \right) q(x)和参数 k k k,从而使得所有接受点都是该分布的样本。
(iii) 建立各种统计估计量实现对问题的求解
通过蒙特卡洛方法的一般数学形式 ,以及其他数理统计公式,建立各种统计估计量如期望、方差、协方差、变异系数等,实现对问题的求解。
综上所述,要想将MC方法作为一个通用的随机模拟方法,必须解决如何基于各种复杂概率分布进行采样这一问题,因为无法实现采样意味着无法建立统计估计,也无法证明人为构造的概率模型是否合适。但在实际应用中,对于常见的高维分布,即使通过拒绝采样也难以实现(无法找到合适的 q ( x ) q\left( x \right) q(x)和参数 k k k,或是 q ( x ) q\left( x \right) q(x)与目标分布差别太大导致接受率过低)。在这种情况下,将进一步引入马尔科夫链的概念。