用python爬取链家网成都房价信息(包括总价、均价、地址、描述等)
准备工作
链家网作为互联网房屋销售信息的大平台之一,拥有大量的二手房源信息,以成都为例,他的房源信息有120000+条以上,如果人工浏览过滤信息,过程比较繁琐,所以可以先使用爬虫技术,将房源信息爬取后在进行数据分析等后期工作。
本次爬虫使用的第三方库有requests,pandas,bs4等(re,time为python自带的库),如果没有,可以使用pip命令安装
1、网页分析
本次爬取的目标网页链接为https://cd.lianjia.com/ershoufang/rs/。 由于数据比较多,一个网页只能存放30条房源信息,在页面底部点击下一页后,出现的网页链接为https://cd.lianjia.com/ershoufang/pg2/,不难看出,‘cd’指的是目标城市的拼音简称,在原链接后接的‘/pg2’就是page2。所以我们将https://cd.lianjia.com/ershoufang作为原链接,通过一个简单的循环来生成后面需要的所有页的链接。lianjia_url='https://cd.lianjia.com/ershoufang/pg'
for i in range(1,101):
#url=lianjia_url+str(i)+'rs%E5%8C%97%E4%BA%AC/'
url=lianjia_url+str(i)+'rs成都/'
接下来我们需要进入网页观察其存放数据的方式
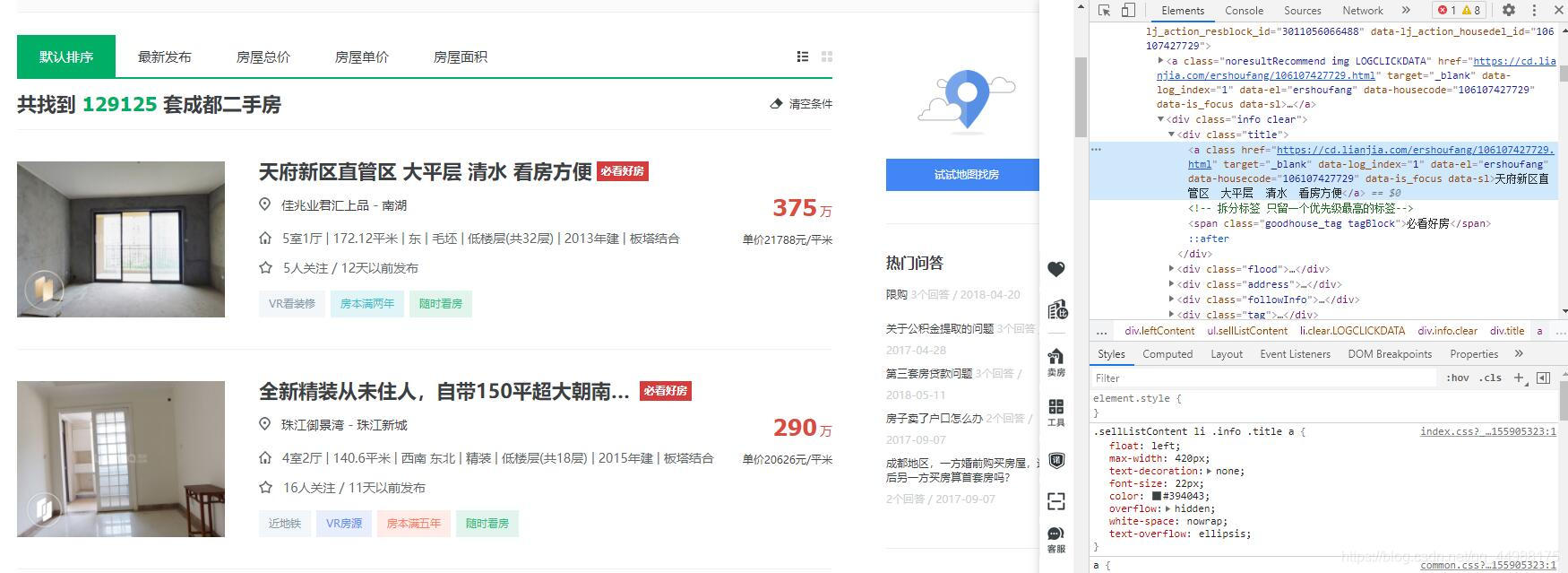
以标签信息为例(即标题),存放在名为‘title’的标签下。使用re库就能非常轻松的将title的信息分离出来。
2、获取HTML信息
def get_html(url):
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Cookie':'lianjia_uuid=9d3277d3-58e4-440e-bade-5069cb5203a4; UM_distinctid=16ba37f7160390-05f17711c11c3e-454c0b2b-100200-16ba37f716618b; _smt_uid=5d176c66.5119839a; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2216ba37f7a942a6-0671dfdde0398a-454c0b2b-1049088-16ba37f7a95409%22%2C%22%24device_id%22%3A%2216ba37f7a942a6-0671dfdde0398a-454c0b2b-1049088-16ba37f7a95409%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%7D; _ga=GA1.2.1772719071.1561816174; Hm_lvt_9152f8221cb6243a53c83b956842be8a=1561822858; _jzqa=1.2532744094467475000.1561816167.1561822858.1561870561.3; CNZZDATA1253477573=987273979-1561811144-%7C1561865554; CNZZDATA1254525948=879163647-1561815364-%7C1561869382; CNZZDATA1255633284=1986996647-1561812900-%7C1561866923; CNZZDATA1255604082=891570058-1561813905-%7C1561866148; _qzja=1.1577983579.1561816168942.1561822857520.1561870561449.1561870561449.1561870847908.0.0.0.7.3; select_city=110000; lianjia_ssid=4e1fa281-1ebf-e1c1-ac56-32b3ec83f7ca; srcid=eyJ0Ijoie1wiZGF0YVwiOlwiMzQ2MDU5ZTQ0OWY4N2RiOTE4NjQ5YmQ0ZGRlMDAyZmFhODZmNjI1ZDQyNWU0OGQ3MjE3Yzk5NzFiYTY4ODM4ZThiZDNhZjliNGU4ODM4M2M3ODZhNDNiNjM1NzMzNjQ4ODY3MWVhMWFmNzFjMDVmMDY4NWMyMTM3MjIxYjBmYzhkYWE1MzIyNzFlOGMyOWFiYmQwZjBjYjcyNmIwOWEwYTNlMTY2MDI1NjkyOTBkNjQ1ZDkwNGM5ZDhkYTIyODU0ZmQzZjhjODhlNGQ1NGRkZTA0ZTBlZDFiNmIxOTE2YmU1NTIxNzhhMGQ3Yzk0ZjQ4NDBlZWI0YjlhYzFiYmJlZjJlNDQ5MDdlNzcxMzAwMmM1ODBlZDJkNmIwZmY0NDAwYmQxNjNjZDlhNmJkNDk3NGMzOTQxNTdkYjZlMjJkYjAxYjIzNjdmYzhiNzMxZDA1MGJlNjBmNzQxMTZjNDIzNFwiLFwia2V5X2lkXCI6XCIxXCIsXCJzaWduXCI6XCIzMGJlNDJiN1wifSIsInIiOiJodHRwczovL2JqLmxpYW5qaWEuY29tL3p1ZmFuZy9yY28zMS8iLCJvcyI6IndlYiIsInYiOiIwLjEifQ=='
}
html=requests.get(url,headers=headers)
return html
同样需要我们的headers信息,谷歌浏览器是可以自己看到自己的headers信息的,'User-Agent’和’Cookie’表示请求头信息,建议根据自己的浏览器修改(当然不改也可以),只是向网站服务器证明是通过浏览器访问而不是爬虫脚本。
3、获取数据
def get_data():
houses_info=[]
location_info=[]
address_info=[]
tag_info=[]
totalPrice_info=[]
arr_price_info=[]
pic_box=[]
lianjia_url='https://cd.lianjia.com/ershoufang/pg'
for i in range(1,101):
#url=lianjia_url+str(i)+'rs%E5%8C%97%E4%BA%AC/'
url=lianjia_url+str(i)+'rs成都/'
html=get_html(url)
if html.status_code==200:
print('----------------')
print('第{}页爬取成功'.format(i))
html=html.text
bs=BeautifulSoup(html,'html.parser')
pic_link=bs.find_all(class_='lj-lazy')
links=re.findall('data-original="(.*?)" src=.*?',str(pic_link))
for link in links:
pic_box.append(link)
house=bs.find_all(class_='info clear')
for item in house:
item=str(item)
infomation=BeautifulSoup(item,'html.parser')
infos=infomation.find_all(class_='title')
info=re.findall('target="_blank">(.*?)</a>',str(infos))
houses_info.append(info)
location=infomation.find_all(class_='flood')
nerby=re.findall('target="_blank">(.*?)</a>',str(location))
location_info.append(nerby)
address=infomation.find_all(class_='address')
address=re.findall('"houseIcon"></span>(.*?)</div>',str(address))
address_info.append(address)
tag=infomation.find_all(class_='tag')
tag=re.findall('<span class=".*?">(.*?)</span>',str(tag))
tag_info.append(tag)
price_info=infomation.find_all(class_='priceInfo')
totalPrice=re.findall('"totalPrice"><span>(.*?)</span>(.*?)</div>',str(price_info))
totalPrice_info.append(totalPrice)
arr_price=re.findall('data-price=.*?"><span>(.*?)</span></div></div>',str(price_info))
arr_price_info.append(arr_price)
time.sleep(0.5)
return houses_info,location_info,address_info,tag_info,totalPrice_info,arr_price_info,pic_box
先只爬取前100页的信息(大概有30000+条左右),其中有难度的就是正则表达式匹配字符串的过程,我在这里举一个简单的例子:
<div class="info">金牛万达<span>/</span>3室1厅<span>/</span>76.6平米<span>/</span>东北<span>/</span>简装</div><div class="tag">
假设我们需要提取出‘金牛万达’这个类似的地址信息,可以用re库的findall函数先找出所有的<class=‘info’>的标签,之后再使用findall函数,就可以拿到‘金牛万达’的信息。
test_line='<div class="info">金牛万达<span>/</span>3室1厅<span>/</span>76.6平米<span>/</span>东北<span>/</span>简装</div><div class="tag">'
title=re.findall('class="info">(.*?)<span>',test_line)
#print(title)
4、保存文件到本地
整合各个列表的文件到本地csv文件,使用pandas的to_csv函数。
houses_info,location_info,address_info,tag_info,totalPrice_info,arr_price_info,pic_box=get_data()
data=pd.DataFrame({
'信息':houses_info,'位置':location_info,'介绍':address_info,'标签':tag_info,'总价':totalPrice_info,'均价':arr_price_info})
try:
data.to_csv('机器学习\爬虫\lianjia_cd.csv',encoding='utf_8_sig')
print("保存文件成功!")
except:
print("保存失败")
然后是爬取图片信息,注意一定设置等待时间,链家网频繁访问是一定会出现验证问题的,如果出现验证问题,可以等待十分钟再继续访问。
with open('机器学习\爬虫\house\img{:s}.jpg'.format(str(time.time())),'wb') as f:
f.write(s)
print('第{}张爬取成功'.format(i))
i=i+1
if i%5==0:
time.sleep(2)
5、完整代码
import requests
from bs4 import BeautifulSoup
import time
import re
import pandas as pd
def get_html(url):
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Cookie':'lianjia_uuid=9d3277d3-58e4-440e-bade-5069cb5203a4; UM_distinctid=16ba37f7160390-05f17711c11c3e-454c0b2b-100200-16ba37f716618b; _smt_uid=5d176c66.5119839a; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2216ba37f7a942a6-0671dfdde0398a-454c0b2b-1049088-16ba37f7a95409%22%2C%22%24device_id%22%3A%2216ba37f7a942a6-0671dfdde0398a-454c0b2b-1049088-16ba37f7a95409%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%7D; _ga=GA1.2.1772719071.1561816174; Hm_lvt_9152f8221cb6243a53c83b956842be8a=1561822858; _jzqa=1.2532744094467475000.1561816167.1561822858.1561870561.3; CNZZDATA1253477573=987273979-1561811144-%7C1561865554; CNZZDATA1254525948=879163647-1561815364-%7C1561869382; CNZZDATA1255633284=1986996647-1561812900-%7C1561866923; CNZZDATA1255604082=891570058-1561813905-%7C1561866148; _qzja=1.1577983579.1561816168942.1561822857520.1561870561449.1561870561449.1561870847908.0.0.0.7.3; select_city=110000; lianjia_ssid=4e1fa281-1ebf-e1c1-ac56-32b3ec83f7ca; srcid=eyJ0Ijoie1wiZGF0YVwiOlwiMzQ2MDU5ZTQ0OWY4N2RiOTE4NjQ5YmQ0ZGRlMDAyZmFhODZmNjI1ZDQyNWU0OGQ3MjE3Yzk5NzFiYTY4ODM4ZThiZDNhZjliNGU4ODM4M2M3ODZhNDNiNjM1NzMzNjQ4ODY3MWVhMWFmNzFjMDVmMDY4NWMyMTM3MjIxYjBmYzhkYWE1MzIyNzFlOGMyOWFiYmQwZjBjYjcyNmIwOWEwYTNlMTY2MDI1NjkyOTBkNjQ1ZDkwNGM5ZDhkYTIyODU0ZmQzZjhjODhlNGQ1NGRkZTA0ZTBlZDFiNmIxOTE2YmU1NTIxNzhhMGQ3Yzk0ZjQ4NDBlZWI0YjlhYzFiYmJlZjJlNDQ5MDdlNzcxMzAwMmM1ODBlZDJkNmIwZmY0NDAwYmQxNjNjZDlhNmJkNDk3NGMzOTQxNTdkYjZlMjJkYjAxYjIzNjdmYzhiNzMxZDA1MGJlNjBmNzQxMTZjNDIzNFwiLFwia2V5X2lkXCI6XCIxXCIsXCJzaWduXCI6XCIzMGJlNDJiN1wifSIsInIiOiJodHRwczovL2JqLmxpYW5qaWEuY29tL3p1ZmFuZy9yY28zMS8iLCJvcyI6IndlYiIsInYiOiIwLjEifQ=='
}
html=requests.get(url,headers=headers)
return html
def get_data():
houses_info=[]
location_info=[]
address_info=[]
tag_info=[]
totalPrice_info=[]
arr_price_info=[]
pic_box=[]
lianjia_url='https://cd.lianjia.com/ershoufang/pg'
for i in range(1,101):
#url=lianjia_url+str(i)+'rs%E5%8C%97%E4%BA%AC/'
url=lianjia_url+str(i)+'rs成都/'
html=get_html(url)
if html.status_code==200:
print('----------------')
print('第{}页爬取成功'.format(i))
html=html.text
bs=BeautifulSoup(html,'html.parser')
pic_link=bs.find_all(class_='lj-lazy')
links=re.findall('data-original="(.*?)" src=.*?',str(pic_link))
for link in links:
pic_box.append(link)
house=bs.find_all(class_='info clear')
for item in house:
item=str(item)
infomation=BeautifulSoup(item,'html.parser')
infos=infomation.find_all(class_='title')
info=re.findall('target="_blank">(.*?)</a>',str(infos))
houses_info.append(info)
location=infomation.find_all(class_='flood')
nerby=re.findall('target="_blank">(.*?)</a>',str(location))
location_info.append(nerby)
address=infomation.find_all(class_='address')
address=re.findall('"houseIcon"></span>(.*?)</div>',str(address))
address_info.append(address)
tag=infomation.find_all(class_='tag')
tag=re.findall('<span class=".*?">(.*?)</span>',str(tag))
tag_info.append(tag)
price_info=infomation.find_all(class_='priceInfo')
totalPrice=re.findall('"totalPrice"><span>(.*?)</span>(.*?)</div>',str(price_info))
totalPrice_info.append(totalPrice)
arr_price=re.findall('data-price=.*?"><span>(.*?)</span></div></div>',str(price_info))
arr_price_info.append(arr_price)
time.sleep(0.5)
return houses_info,location_info,address_info,tag_info,totalPrice_info,arr_price_info,pic_box
def main():
houses_info,location_info,address_info,tag_info,totalPrice_info,arr_price_info,pic_box=get_data()
data=pd.DataFrame({
'信息':houses_info,'位置':location_info,'介绍':address_info,'标签':tag_info,'总价':totalPrice_info,'均价':arr_price_info})
try:
data.to_csv('机器学习\爬虫\lianjia_cd.csv',encoding='utf_8_sig')
print("保存文件成功!")
except:
print("保存失败")
try:
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36'}
i=1
for j in range(len(pic_box)):
print(pic_box[j])
s=requests.get(pic_box[j],headers=headers).content
with open('机器学习\爬虫\house\img{:s}.jpg'.format(str(time.time())),'wb') as f:
f.write(s)
print('第{}张爬取成功'.format(i))
i=i+1
if i%5==0:
time.sleep(2)
print("爬取成功")
print(len(houses_info))
except:
print('爬取失败')
pass
if __name__ == "__main__":
main()
感谢大家的支持,如有错误,请大家多多指正!