Redis发布与订阅
订阅一个频道
127.0.0.1:6379> subscribe zzf
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "zzf"
3) (integer) 1
在另一个连接向频道发布消息
127.0.0.1:6379> publish zzf "hello,zzf"
(integer) 1
订阅那边会受到相应的信息
127.0.0.1:6379> subscribe zzf
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "zzf"
3) (integer) 1
1) "message"
2) "zzf"
3) "hello,zzf"
使用场景
1、简单的实时聊天
2、发布订阅模型
Redis主从复制
概念
主从复制是指将一台Redis服务器的数据复制到其他的Redis服务器,前者称为主节点(master/leader),后者称为从节点(slave/follower);数据的复制是单向的,只能由主节点到从节点,Master以写为主,Slave以读为主。
默认情况下,每台Redis服务器都是主节点;且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
主从复制的作用主要包括:
1、数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式
2、故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余
3、负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量
4、高可用基石:除了上述作用,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础
一般来说,要将Redis运用于工程项目中,只使用一台Redis不够,原因如下:
1、从结构上,单个Redis服务器会发生单点故障,并且一台服务器需要处理所有的请求负载,压力较大
2、从容量上,当个Redis服务器内存容量有限,就算一台Redis服务器内存容量为256G,也不能将所有内存用作Redis存储内存,一般来说,单台Redis最大使用内存不应该超过20G
环境配置(主从复制集群测试)
查看Redis服务器信息
127.0.0.1:6379> info replication
# Replication
role:master #角色
connected_slaves:0 #连接的从机数
master_replid:8dc2e8e176e7efa3d0a21afbdc67f19f0ea9545a
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
复制三个redis配置文件用于测试
cp /www/server/redis/redis.conf /www/server/redis/zzfconf/redis80.conf
cp /www/server/redis/redis.conf /www/server/redis/zzfconf/redis81.conf
cp /www/server/redis/redis.conf /www/server/redis/zzfconf/redis82.conf
修改配置文件中的对应信息
1、端口
2、pid名字
3、log文件名字
4、dump.rdb名字
修改完毕后启动服务,查看进程信息
redis-server /www/server/redis/zzfconf/redis80.conf
redis-server /www/server/redis/zzfconf/redis81.conf
redis-server /www/server/redis/zzfconf/redis82.conf
利用这三个新增的redis服务进行主从复制的一主二从操作
默认都是主节点,我们将6380端口的作为主服务器,6381、6382端口的作为从服务器,在从服务器输入命令
slaveof 127.0.0.1 6380
再次查看各个服务器的信息
6380
127.0.0.1:6380> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6381,state=online,offset=56,lag=1
slave1:ip=127.0.0.1,port=6382,state=online,offset=56,lag=1
master_replid:452e335dd36c2d75bf664ca043b0074e678fbca3
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:56
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:56
6381
127.0.0.1:6381> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6380
master_link_status:up
master_last_io_seconds_ago:4
master_sync_in_progress:0
slave_repl_offset:14
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:452e335dd36c2d75bf664ca043b0074e678fbca3
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:14
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:14
6382
127.0.0.1:6382> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6380
master_link_status:up
master_last_io_seconds_ago:6
master_sync_in_progress:0
slave_repl_offset:42
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:452e335dd36c2d75bf664ca043b0074e678fbca3
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:42
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:43
repl_backlog_histlen:0
这是通过命令配置,是暂时的
永久配置须在配置文件中配置,将这个地方去掉注释,输入主机的ip和端口

测试一下
127.0.0.1:6380> set k1 v1
OK
127.0.0.1:6381> set k2 v2
(error) READONLY You can't write against a read only replica.
127.0.0.1:6381> get k1
"v1"
127.0.0.1:6382> set k1 v1
(error) READONLY You can't write against a read only replica.
127.0.0.1:6382> get k1
"v1"
可以看出现在主机可以写,从机不能写只能读
如果主机断开,从机仍然能进行读操作,但整个系统不能写操作
只有从机才能读取主机写入的数据
复制原理
slave(从机)启动成功连接到master(主机)后会发送一个sync命令,master接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集的命令,在后台进程执行完毕后,master将传送整个数据文件到slave,并完成一次完全同步
全量复制:slave服务在接收到数据库文件数据后,将其存盘并加载到内存中
增量复制:master继续将新的所有收集到的修改命令依次传给slave,完成同步,但是只要是重新连接master,依次完全同步(全量复制)将被自动执行
上面主从复制模型是一台主机多台从机的一对多模型
还可以用另一种链式的模型,例如将6380端口的服务器作为主机,6381作为6380的从机,而6382作为6381的从机,形成一个链条,这样也能正常使用
如果主机断开了连接,可以使用slaveof no one让自己变成主机,其他节点可以手动连接到最新的主节点
哨兵模式
主从切换技术的方法是:当主服务器宕机后,需要手动把一台服务器切换为主服务器,这就需要人工干预,费时费力,还会造成一段时间内服务不可用,所以更多时候考虑哨兵模式,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库。
实际生产常用多哨兵模式
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象称为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover故障转移操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换为主机,称为客观下线。
哨兵配置文件
vim sentinel.conf
sentinel monitor myredis 127.0.0.1 6380 1
myredis是被监控的名称,可自定义
数字1代表主机挂了,有一个哨兵认为主服务器宕机,就进行failover,从机投票选出新的主机
如果主机回来了,只能归并到新的主机下,当作从机
开启监控
redis-sentinel sentinel.conf
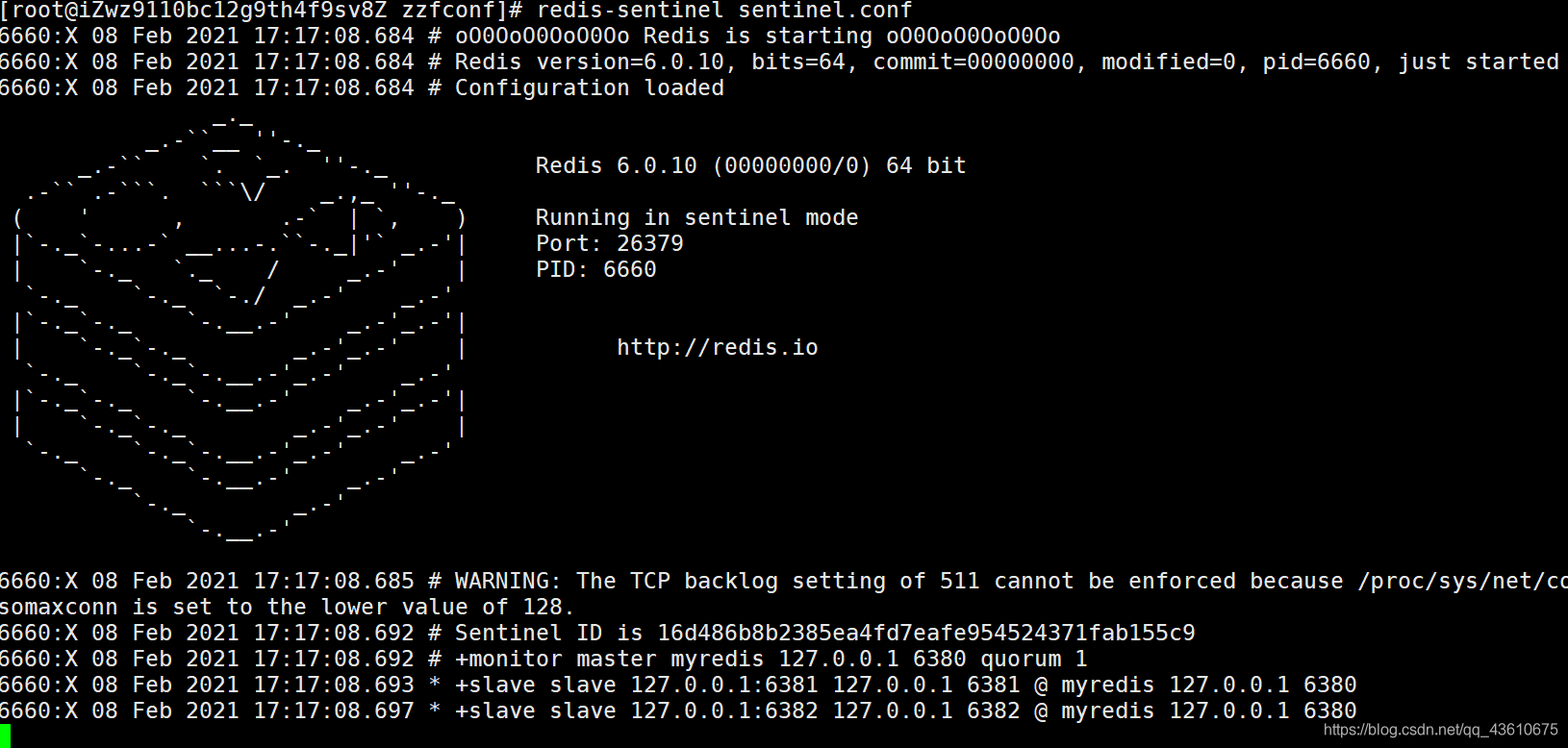
将6380端口的服务器shutdown,那边过一段时间会发出信息
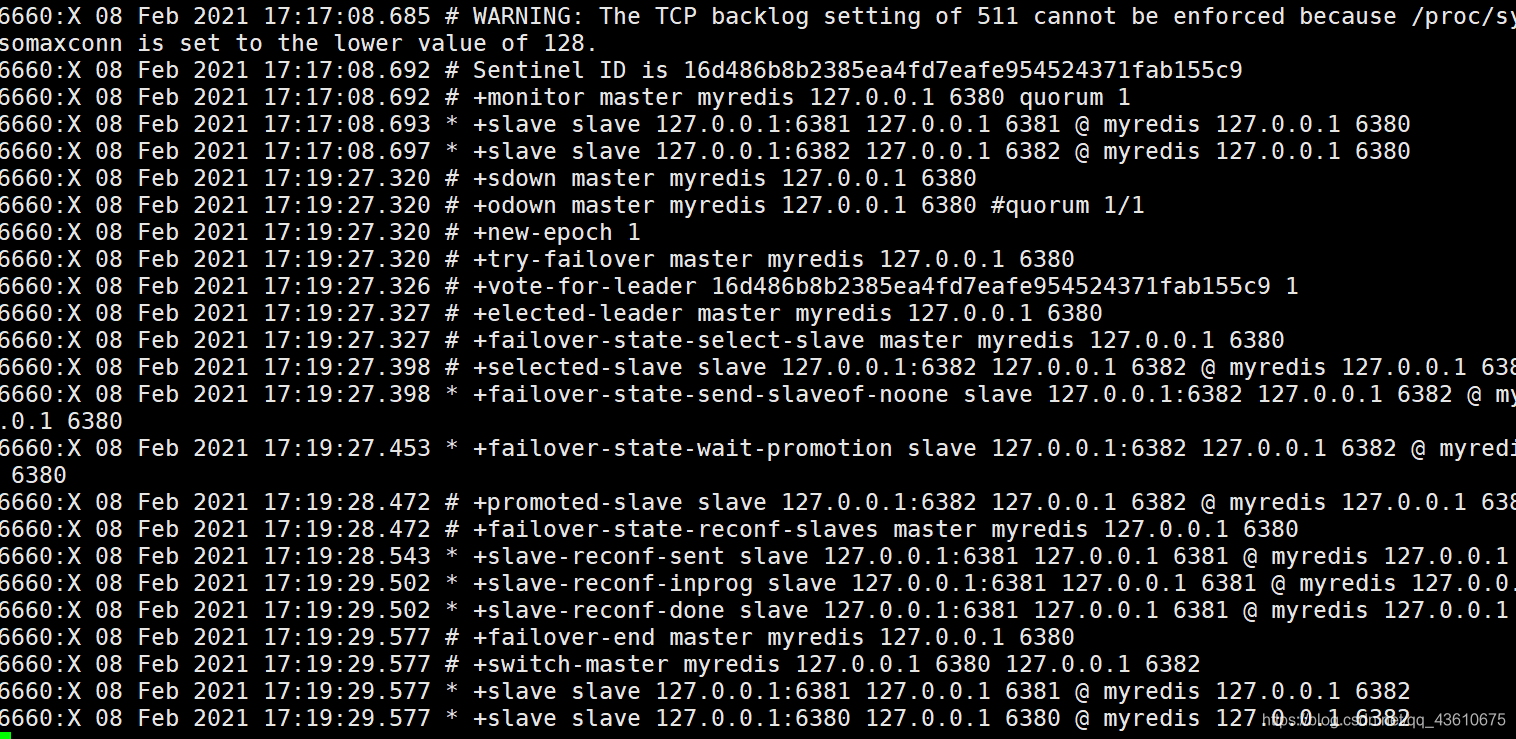
此时剩余两台从机中有一台会被切换成主机,这里是6382端口的服务器成为了主机
127.0.0.1:6382> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6381,state=online,offset=15160,lag=0
master_replid:9b5d53c80a86c60b9018bae00d4666b62c0f9902
master_replid2:c6216c491387c038802f20d011432f64bcb12c72
master_repl_offset:15160
second_repl_offset:7314
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:15160
优点:
1、哨兵集群,基于主从复制模式,所有的主从配置优点,它全有
2、主从可以切换,故障可以转移,系统的可用性就会更好
3、哨兵模式就是主从模式的升级,手动到自动,更加健壮
缺点:
1、Redis不好实现在线扩容,集群数量一旦到达上限,在线扩容十分麻烦
2、实现哨兵模式的配置其实很麻烦
Redis缓存穿透和雪崩
缓存穿透
当用户想要查询一个数据,发现redis内存数据库没有,也就是缓存没有命中,于是向持久层数据库查询。发现也没有,于是本次查询失败。当用户很多的时候,缓存都没有命中,就会都去请求持久层数据库,给它造成很大的压力,这时候就相当于出现了缓存穿透
解决方案
布隆过滤器
布隆过滤器是一种数据结构,对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃,从而避免了对底层存储系统的查询压力
缓存空对象
当存储层不命中,将返回的空对象也将其缓存起来,同时会设置一个过期时间,之后再访问这个数据将会从缓存中获取,保护了后端数据源
但这种方法会存在两个问题:
1、如果空值能够被缓存起来,会需要更多的空间存储更多的键
2、即时对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间不一致,可能会对业务造成影响
缓存击穿
指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点访问,在key失效的一瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞
当某个key在过期的瞬间,有大量的请求并发访问,这类数据一般是热点数据,由于缓存过期,会同时访问数据库来查询最新数据,并且回写缓存,会导致数据库瞬间压力过大
解决方案
设置热点数据永不过期
从缓存层面来看,没有设置过期时间,就不会出现热点key过期产生的问题
加互斥锁
分布式锁:使用分布式锁,保证对于每个key同时只有一个线程去查询后端服务,其他线程没有获得分布式锁的权限则等待。这种方式将高并发的压力转移到了分布式锁
缓存雪崩
指在某一个时间段,缓存集中过期失效
缓存服务器宕机或断网,会自然形成雪崩
解决方案
redis高可用
即多增设几台redis,搭建集群
限流降级
在缓存失效后,通过加锁或者队列来控制都数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待
数据预热
在正式部署之前,先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中。在即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀
参考
https://www.bilibili.com/video/BV1S54y1R7SB