redis的主从复制
概念.
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(mster/leader),后者称为从节点(slave/follower);数据的复制是单向的,只能由主节点到从节点。
Master以写为主,Slav以读为主。
默认情况下,每台Redis服务器都是主节点(就是你没有设置配置文件直接新开一个redis服务端)
且一个主节点可以有多个从节点(或者没有从节点),但是一个从节点只能有一个主节点。
主从复制的作用主要包括:
- 数据冗余:主从复制实现了数据的热备份(主机崩掉,数据在从机当中),是持久化之外的一种数据冗余方式。
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。(从节点来进行查)
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
一般来说,要将Redis运用于工程项目中,是不可能只用一台Redis服务端的:
- 从结构上说,单个Redis服务器会发生单点故障,并且一台服务器需要处理所有的请求负载,压力较大;
- 从容量上说,单个Redis服务器内存容量优先,就算一台Redis服务器内存容量为256G(我的是16G 运行内存 服务器是2G运行内存 不是物理内存),也不能将所有内存用作Redis存储内存,一般来说,单台Redis最大使用内存不应该超过20G。
电商网站上的商品 ,一般都是一次上传,无数次浏览的,说专业点也就是“多度少写“。
对于这种场景,我们可以使用如下这种架构:

环境配置
只配置从库,不用配置主库
info replication # 查看当前库的信息
127.0.0.1:6379> info replication
# Replication
role:master # 角色
connected_slaves:0 # 从机数量
master_replid:2deb59f58bd7d8f72add71781b3a15f1ba1728ec
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
master_repl_meaningful_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
复制配置文件,然后修改对应的信息
- bind 修改ip 本机测试默认为127.0.0.1
- port 修改端口号
- logfile “日志文件名.log” 修改输出日志文件名 默认在当前文件夹下
- dbfilename “rdb文件名.rdb” 修改备份文件名 默认在当前文件夹下
- 开启守护进行,可以在后台运行服务端

一主二从
==默认情况下,每台Redis服务器都是主节点;我们一般情况下只用配置从机就好了!
一主(201),二从(202,203)
命令行配置主从,(练习中使用,因为只是暂时的)
slaveof host port # 找谁当自己的老大
# 老大的角色信息是master 小弟的角色信息是slave
配置文件配置主从
只需要在从服务器上进行配置
replicaof <masterip> <masterport> # 配置文件中写
如果有密码的话
masterauth <master-password> # 进行配置
细节
主机可以写,从机只能读不能写,主机中写入的所有信息和数据,都会被从机自动同步!
==如果主机断开连接(退出或者崩掉),从机依旧连接到主机,但是还是没有写的操作,这个时候主机如果上线成功,从机依旧可以直接获取到主机写的信息!
复制原理
Slave启动成功连接到master后会发送一个sync同步命令
Master接受到命令后,启动后台的存盘进程,同时收集接受到的用于修改数据集的命令,在后台进程执行完毕后,master将传送整个数据文件到slave,并完成一次完全同步
全量复制:slave服务端在接受到数据库文件数据后,将其存盘并加重到内存中(启动slave服务端的时候进行全量复制)
增量复制:Mater继续将新的所有收集到的修改命令依次传给slave,完成同步(也就是主从都在线的时候,主机写入数据,从机同步这次写入的数据)
只要重新连接master,一次完全同步(全量复制)将会被自动执行!数据一定可以在从机中看到
问题
如果主机崩掉,就不能写入数据了,只能读取,不灵活且容错率太低,接下来引入哨兵模式的概念来解决这个问题
哨兵模式
概述
- 主从切换技术的方法是:
- 当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费时费力,还会造成一段时间内服务的不可用,是个大问题
- 哨兵模式的主从切换方式为:
- 哨兵是一个独立的进程,作为进程,它会独立运行,其原理是**哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Reids服务
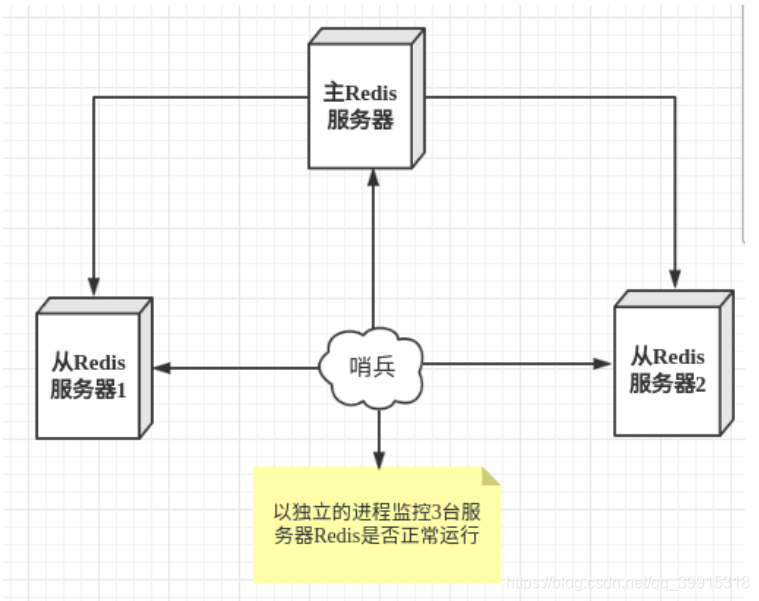
- 这里的哨兵有两个作用
- 通过发送命令,让Redis服务器返回响应,完成对运行状态的监控,包括主服务器和从服务器。
- 当哨兵检测到master宕机,会自动将数据量最多的slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改其配置文件,让他们切换主机,如果这时之前的master上线了,那么他将会变为slave
- 但是一个哨兵进行对Redis服务器进行监控,还是有可能会出现问题(如果哨兵进程蹦了呢?),为此我们就需要使用多个哨兵进行,此时的哨兵集群不止监控主从服务器还要进行互相监控,这样就形成了多哨兵模式
- 多哨兵模式
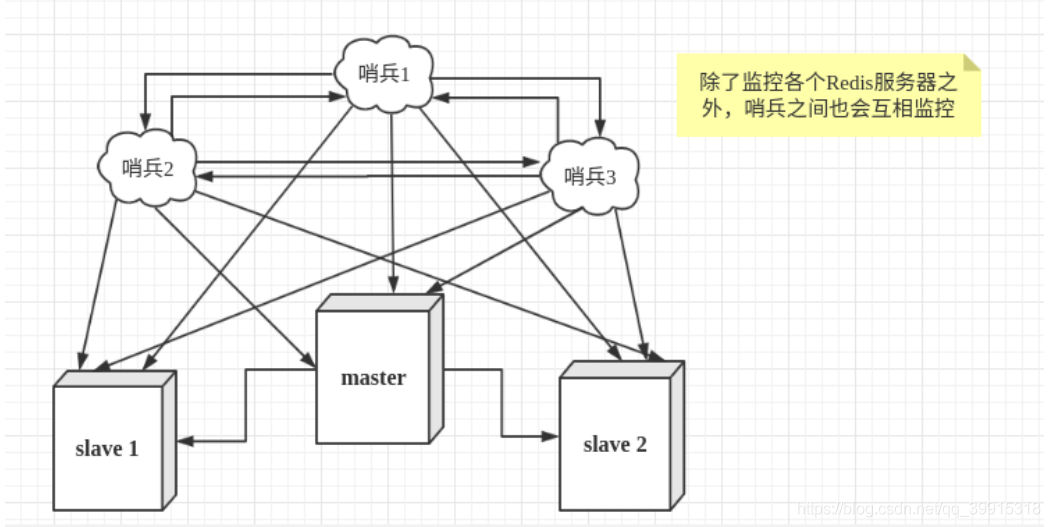
- 当主服务器宕机,如果哨兵1先检测到这个结果(通过每隔一段时间向服务器发送命令,查看响应的方式进行检测),这时候并不会马上执行failover(故障切换),仅仅是哨兵1主观的认为主服务器不可用,这个现象称为主观下线。当后面的哨兵也检测到主服务器不可用,并且发现情况的哨兵数量达到一定值时,哨兵之间就会进行一次投票(redis底层的算法),投票的结果由一个哨兵发起,进行failover操作。主服务器转移成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线
哨兵配置文件
sentinel monitor 被监控的名称 host port 有几个哨兵进程写几(用于客观下线) # 在哨兵配置文件名.conf 中配置 如果不存在则新建
sentinel monitor myredis 127.0.0.1 201 3
# 哨兵sentinel实例运行的端口 默认26379
port 26379 # 哨兵集群要配置端口
# 哨兵sentinel的工作目录
dir /tmp
# 开启守护进程 用于后台运行
daemonize yes
# 哨兵sentinel监控的redis主节点的 ip port
# master-name 可以自己命名的主节点名字 只能由字母A-z、数字0-9 、这三个字符".-_"组成。
# quorum 配置多少个sentinel哨兵统一认为master主节点失联 那么这时客观上认为主节点失联了
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
sentinel monitor mymaster 127.0.0.1 201 3 # 重点,学习中只写这个就可以了
# 当在Redis服务端中开启了requirepass foobared 授权密码 这样所有连接Redis实例的客户端都要提供 密码# 设置哨兵sentinel 连接主从的密码 注意必须为主从设置一样的验证密码 # sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster MySUPER--secret-0123passw0rd
# 指定多少毫秒之后 主节点没有应答哨兵sentinel 此时 哨兵主观上认为主节点下线 默认30秒
# sentinel down-after-milliseconds <master-name> <milliseconds>
sentinel down-after-milliseconds mymaster 30000
# 这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同步,
这个数字越小,完成failover所需的时间就越长, 但是如果这个数字越大,就意味着越多的slave因为replication而不可用。可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。
# sentinel parallel-syncs <master-name> <numslaves>
sentinel parallel-syncs mymaster 1
# 故障转移的超时时间 failover-timeout 可以用在以下这些方面:
1. 同一个sentinel对同一个master两次failover之间的间隔时间。
2. 当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那 里同步数据时。
3.当想要取消一个正在进行的failover所需要的时间。
4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时, slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了
# 默认三分钟
# sentinel failover-timeout <master-name> <milliseconds>
sentinel failover-timeout mymaster 180000
#配置当某一事件发生时所需要执行的脚本,可以通过脚本来通知管理员,例如当系统运行不正常时发邮件通知 相关人员。 #对于脚本的运行结果有以下规则:
#若脚本执行后返回1,那么该脚本稍后将会被再次执行,重复次数目前默认为10 #若脚本执行后返回2,或者比2更高的一个返回值,脚本将不会重复执行。
#如果脚本在执行过程中由于收到系统中断信号被终止了,则同返回值为1时的行为相同。
#一个脚本的最大执行时间为60s,如果超过这个时间,脚本将会被一个SIGKILL信号终止,之后重新执行。
#通知型脚本:当sentinel有任何警告级别的事件发生时(比如说redis实例的主观失效和客观失效等等),将会去调用这个脚本,这时这个脚本应该通过邮件,SMS等方式去通知系统管理员关于系统不正常运行的信息。调用该脚本时,将传给脚本两个参数,一个是事件的类型,一个是事件的描述。如果sentinel.conf配 置文件中配置了这个脚本路径,那么必须保证这个脚本存在于这个路径,并且是可执行的,否则sentinel无 法正常启动成功。
#通知脚本 # shell编程 # sentinel notification-script <master-name> <script-path>
sentinel notification-script mymaster /var/redis/notify.sh
# 客户端重新配置主节点参数脚本
# 当一个master由于failover而发生改变时,这个脚本将会被调用,通知相关的客户端关于master地址已 经发生改变的信息。
# 以下参数将会在调用脚本时传给脚本:
# <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>
# 目前<state>总是“failover”, # <role>是“leader”或者“observer”中的一个。
# 参数 from-ip, from-port, to-ip, to-port是用来和旧的master和新的master(即旧的slave)通信的
# 这个脚本应该是通用的,能被多次调用,不是针对性的。
# sentinel client-reconfig-script <master-name> <script-path> sentinel client-reconfig-script mymaster /var/redis/reconfig.sh
# 一般都是由运维来配置!
Redis(高级)缓存穿透,缓存击穿和雪崩
服务器的高可用问题引发
在MySQL的基础上移入了Redis缓存的使用,极大的笛声了应用程序的性能和效率,特别是数据查询方面。但是也带来了一些问题,其中==最要害的问题就是,数据的一致性问题,从严格意义上讲,这个问题无解。==如果对数据的一致性要求很高,那么就不能使用缓存。另外的一些典型问题就是,缓存穿透、缓存雪崩和缓存击穿。
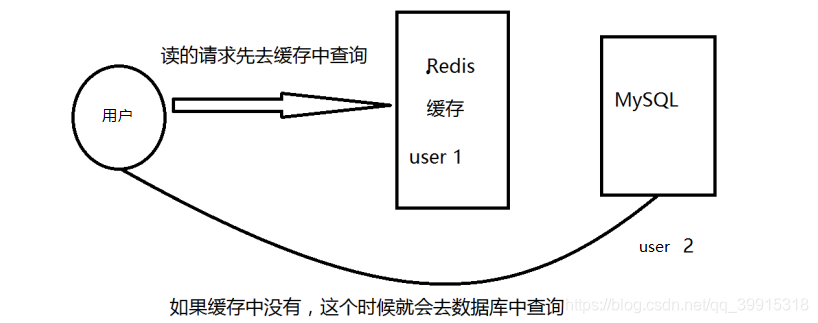
缓存穿透(没有命中)
概念
缓存穿透的概念很简单,用户想要查询一个数据,发现redis内存数据库中没有,这就是缓存没有命中,于是向存储(mysql)数据库查询。发现也没有,于是本次查询失败。当用户很多的时候,缓存都没有命中(秒杀场景),于是同一时间大量请求都前往存储层数据库。这就会给持久层数据库造成很大的压力。这种情况就向东与出现了缓存穿透
解决方案
-
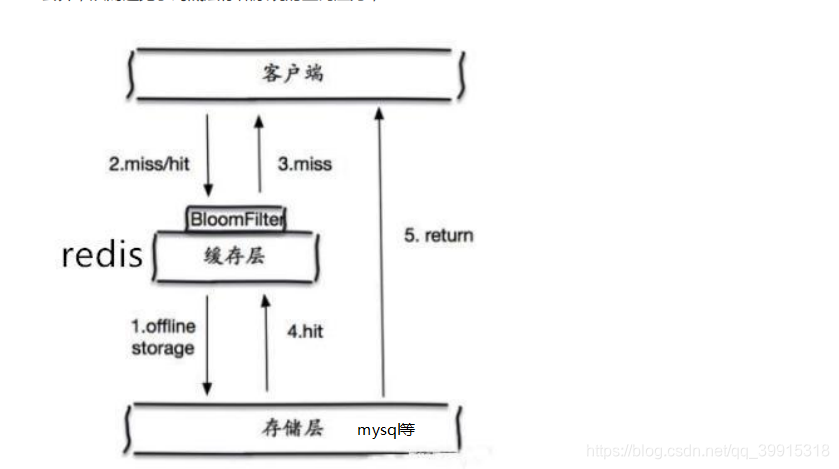
布隆过滤器
布隆过滤器是一种数据结构,对所有可能查询的参数以hash形式存储,在控制层(redis缓存层之前设立的一个层)进行校验,不符合则丢弃(比如缓存层中没有要查询的数据,或者存储层中也同样没有就丢弃),从而避免了对地缝数据系统的查询压力;
-
存储空对象
当存储层查询不到数据,返回空响应时(不命中),将返回的空对象也将其缓存起来,同时设置一个过期时间,之后再访问这个数据时将会从缓存中获取(虽然是空的),保护了后端数据源;
- 存在两个问题:
- 如果空值被缓存起来,这就意味着要用更多的空间存储更多的键,这当中会有大量的空值的键,而redis内存数据库是有限的,虽然会定期清理一批过期的数据,但是没清理之前还是有可能造成内存满了的情况。
- 即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口不一致(比如缓存的是key:null,但是存储层这个key的值有了,这个时候这个key 在缓存层中还没有过期,就会造成窗口不一致)这对于需要保持一致性的业务会有影响。
- 存在两个问题:
缓存击穿(缓存过期时大量查询进入)
概述
注意缓存击穿和缓存穿透的区别:
- 缓存击穿,是指一个key非常的热点(某某明星出轨,X战等新闻)在不听的扛着大量的并发请求,大量并发集中在这一个点进行访问,当这个key在失效的瞬间,这个时候还没有进行会写缓存时,持续的大并发就击穿了缓存,直接请求存储层数据库,造成存储层数据库瞬间压力过大
- 缓存穿透,是指在缓存层中查询不到该key,然后大量的数据穿过缓存层直接进入存储层查询的情况。
解决方案
-
设置热点数据永不过期
从缓存层面来看,没有设置过期时间,所以不会出现热点key过期后产生击穿问题,但是也不够灵活,产生了其他问题
-
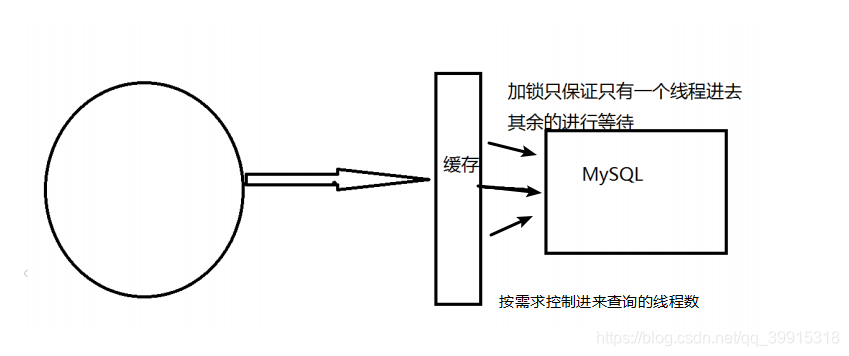
加分布式锁
分布式锁:使用分布式锁,保证对于每个的key同时只有一个线程去查询后端服务,其他线程没有获得分布式锁的权限,因此只需要等待即可。这种方式将高并发的压力转移到了分布式锁,因此对分布式锁的设计等考验很大。
缓存雪崩
概念
缓存雪崩,是指在某一个时间段,缓存集中过期失效。(key过期时间相同了,或者redis宕机),大量数据进入存储层,造成存储层压力过大甚至也宕机的情况
产生雪崩的可能之一:
比如当双十一零点,马上迎来一波商品抢购,这波商品时间比较集中的放入了缓存层中,假设缓存了一个小时,那么到了凌晨一点的时候,这批商品的缓存就同时都过期了。而对这批商品的查询请求就都落到了存储层上面,对于存储层数据库而言,会产生周期性的压力波峰。当大量波峰集中在一起时,存储层也挂掉,然后整个服务链挂掉

其实集中过期倒不是特别致命,比较致命的缓存雪崩,是缓存服务器某个节点宕机或者断网断电。因为同时过期形成的缓存雪崩,一定是在某个时间段集中创建缓存导致的,这个时候就算进入存储层,数据库也是可以顶住压力的。无非就是对数据库产生周期性压力波峰而言(大量波高波峰集中不考虑)。而存储服务器节点的宕机,对于存储层造成的压力是不可预知的,非常有可能瞬间就把数据库压垮
解决方案
-
redis高可用
这个思想的含义是,既然redis有可能挂掉,那么我就多增设几台redis,这样一台挂掉之后其他的还可以继续工作,这个其实就是搭建集群(异地多活,哨兵模式)
-
限流降级
这个解决方案的思想是,在缓存失效后,通过加锁或者队列来控制读取数据库写缓存的线程数量。比如对某个个key只允许一个线程查询数据和写缓存,其他线程等待。(分布式锁)
-
数据预热
数据预加热的含义就是在正式部署之前,我们先把可能的数据预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中。在即将发生大并发请求之前就手动加载缓存不同的key,设置不同的过期时间,让数据失效时间尽可能的均匀