如何从调优小白走向调优高手
说起JVM调优,大伙儿可能瞬间头皮发麻。"好家伙,和调优沾边儿的事儿,不是我这个段位的小新手能解决的"。
于是赶紧找来了技术大拿,看大拿三下五除二排查出了问题原因,给出了优化方案。此时,我们的眼里放着光,一脸崇拜的望着大拿,幻想着哪天能成为他这样出色的大佬。
这篇文章,就是让你学会调优,掌握一个属于自己的调优节奏与思路。
快速了解调优
如果你对调优没有什么概念,那么我们先说说调优是什么。
所谓调优,就是你的系统生病了。此时,我们就是一个诊所。系统找我们来治治病。
我们去医院做体检时,医院都会给我们看一个体检单子。这个单子会列举许多检查项目。调优亦是如此,我们也需要给我们的系统开一个检查单,给运行时数据区做一个全方位体检。这段话说明什么呢?说明其实问题的排查往往没我们想的那么复杂。而是有章法的。按照一个固定的套路和习惯,就能把问题差不多定位出来。
那么,本文我会把我们每一个开发人员比喻成为一个个诊所。让我们来一起诊治我们的病人吧!
小区医务所——JDK自带指令
用jvm自带的命令可以方便的在生产监控和打印堆栈的日志信息帮忙我们来定位问题!虽然jvm调优成熟的工具已经有很多:jconsole、大名鼎鼎的VisualVM,IBM的Memory Analyzer等等,但是在生产环境出现问题的时候,一方面工具的使用会有所限制,另一方面喜欢装X的我们,总喜欢在出现问题的时候在终端输入一些命令来解决。所有的工具几乎都是依赖于jdk的接口和底层的这些命令,如果站在我们诊所的角度来看,就好比是一个仅仅具备比较基础设施的医院。但研究这些命令的使用也让我们更能了解jvm构成和特性,才能将其他强大的工具玩的更转。
Sun JDK监控和故障处理命令有jps jstat jmap jhat jstack jinfo下面做一一介绍,最后再附带一个调优案例。新手在刚接触这些生涩的指令时,可以先记住这些调优的死套路。其实调优未必像我们想的那么高大上或苦难。往往我们需要调优时,系统中的某些指标一定已经出现了较为明显的异常了。我们只需要通过这些简单的命令,给系统按部就班的做一套"体检",就能清晰地找到问题。然后对JVM的基础知识掌握牢固的你,自然可以有千百种方法"对症下药"。
JVM调优基础命令
jps(查看进程号)
用来显示本地的java进程,可以查看本地运行着几个java程序,并显示他们的进程号。即时我们的诊所不大,也有眼科,耳鼻喉科等等。在我们的诊所里有Java程序科,专门负责查找有关Java的病人,并获取他们的进程号。
一个计算机上,可能运行了相当多的进程。而作为Java开发的我们,只需要去排查我们虚拟机进程是否出现问题。因此往往此命令作为调优的第一步。帮我们筛选出虚拟机进程。
格式
jps -[ options ] [ hostid ] (运行的进程不多时,直接打JPS就行)
参数说明
options
-q 只输出java进程的进程id
-l 输出java进程的进程id和main方法的类全名
-m 输出java进程的进程id和main方法的入参
-v 输出java进程的进程id和jvm的入参
-V 输出java进程的进程id和通过flag文件传入jvm的参数
hostid
命令对应的服务器ip,默认不加参数,代码查看本机
jstat(贴心的护工,实时监控病人信息)
我们都知道,如果家人朋友得了重病,往往需要一个一直照顾他。
反映到程序中依旧是这个道理。我们往往获取一个时间点的信息,是无法判断病人的状况的。最差的情况就是一个病人头疼,排了几天的队到了医院,医生问,您哪儿不舒服啊?这时候你头正好不疼。于是没办法只能回家。刚一到家,头疼的问题再次降临。。。。。。
在我们对程序进行问题排查时,依旧会遇到这种问题。或许在多个时间点排查问题都是正常的。那么就需要用到这个指令,在一段时间内持续反馈病人的各项指标数据。
格式
jstat -[ options ] [ hostid ] [ 时间/毫秒 ] [ 统计次数 ]
例子:jstat -gc 4700 5000 20
参数说明
options
-class(类加载器)
-compiler(JIT)
-gc (GC堆状态)
-gccapacity(各区大小)
-gcnew(新区统计)
-gcnewcapacity(新区大小)
-gcold (老区统计)
-gcoldcapacity (老区大小)
-gcpermcapacity (永久区大小)
-gcutil (GC 统计汇总)
-printcompilation (HotSpot 编译统计)
hostid
命令对应的服务器ip,默认不加参数,代码查看本机
使用小技巧
可以看到,这个指令的核心正是,把时间点的统计变为了时间片的统计。由此我们可以大概估测一下,未来更强大的排查工具可以以此绘制出数据变化趋势图。在此,我们依然使用基础的指令来做一个小例子。
第一步,我们先根据JPS指令,获取到我们的Java进程号为4700。
假设需要250毫秒查询一次此进程的垃圾收集状况,一共查询10次。那么命令应当是jstat -gc 4700 250 10。查询结果如下: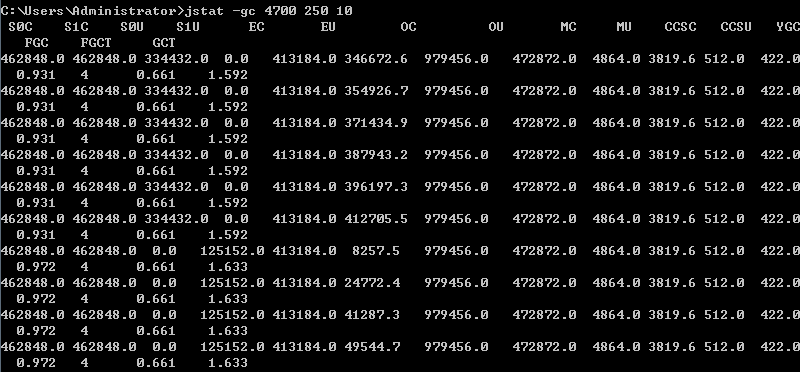
-gc 指令参数解释
S0C:第一个幸存区(From 区)的大小
S1C:第二个幸存区(To 区)的大小
S0U:第一个幸存区的使用大小
S1U:第二个幸存区的使用大小
EC:伊甸园(Eden)区的大小
EU:伊甸园(Eden)区的使用大小
OC:老年代大小OU:老年代使用大小
MC:方法区大小
MU:方法区使用大小
CCSC:压缩类空间大小
CCSU:压缩类空间使用大小
YGC:年轻代垃圾回收次数
YGCT:年轻代垃圾回收消耗时间
FGC:老年代垃圾回收次数
FGCT:老年代垃圾回收消耗时间
GCT:垃圾回收消耗总时间
jstat显示的参数太多,眼都看花了怎么办
当然,这么一堆数据,看着也不方便。我们的工具还提供了筛查部分参数的功能。例如我们只想看垃圾回收的次数,就可以使用命令:
jstat -gc 4700 5000 20 | awk '{print $13,$14,$15,$16,$17}'
jinfo(查看/修改虚拟机参数)
我们知道,许多时候,我们的Java进程出现了问题,并非一定是代码出现了问题。
实际上我们的JVM有许许多多的功能,但平常我们却很少使用。而在程序运行期间,我们往往需要临时开启这些功能,协助我们排查问题,或加强一些功能。
- 来看看我们我们虚拟机的参数设置情况,包括Java System属性和JVM命令行参数。
- 也可以动态的修改正在运行的 JVM 一些参数.(打破限制器)
- 当系统崩溃时,jinfo可以从core文件里面知道崩溃的Java应用程序的配置信息
格式
jinfo -[ options ] [ hostid ]
例子:jinfo -flag PrintGC 13528
参数说明
-flags pid :打印当前VM的参数
-flag <name> pid:打印指定JVM的参数值
-flag [+|-]<name> pid:设置指定JVM参数的布尔值
-flag <name>=<value> pid:设置指定JVM参数的值
-sysprops pid : 获取当前系统参数包括-D设置的参数
当然并不是所有的参数都是允许修改的,只允许修改其中部分参数。(医生说有些病现在活着能治。有些病不行了,下辈子好好珍惜身体吧)。
如何查看哪些参数可修改
在 windows 上可以通过以下 java -XX:+PrintFlagsFinal –version 查询所有-XX 的参数
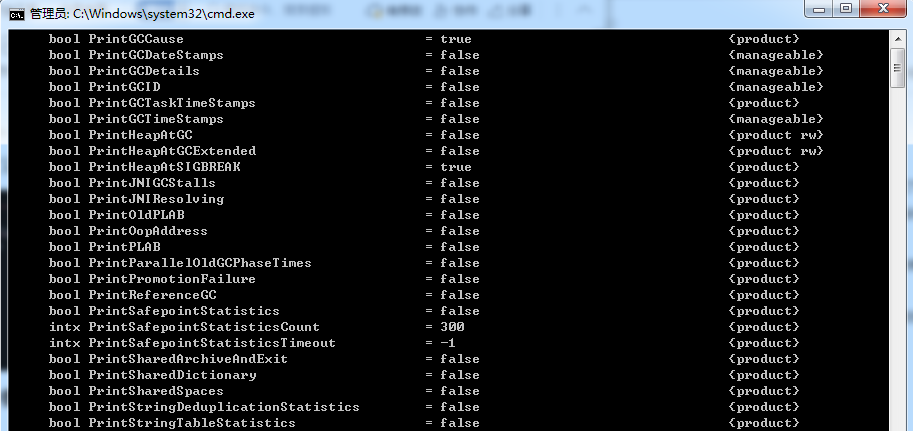
注意:manageable 的参数,代表可以运行时修改。

使用小技巧
首先我们由上图得知PrintGC这个XX参数是可以运行时修改的。
jinfo –flag [+/-][参数] pid 可以修改参数
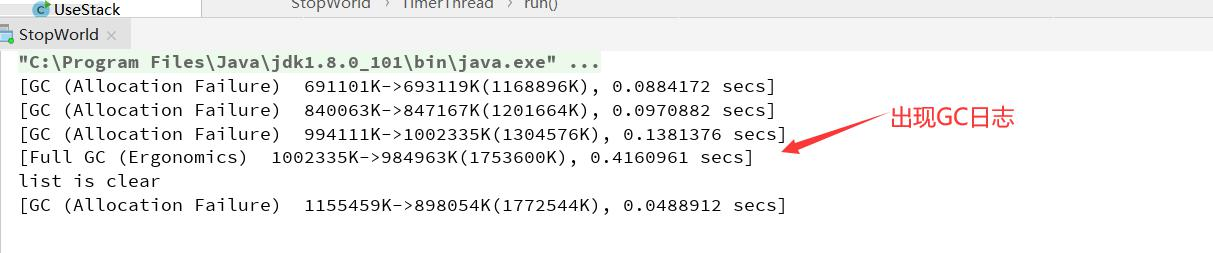
还是这段程序,我们的关注点在于,启动程序后,控制台并没有任何打印。此时,我们通过jinfo命令让其在不关闭程序的状态下显示出GC打印信息。
我们打开命CMD窗口,通过jps定位到相关进程,再通过jinfo -flag PrintGC 13528查看PrintGC这个参数的当前状态。

可以很明显看到。我们查到的该参数前面有个减号。这说明,此时这个参数是关闭的。此时,我们用jinfo -flag +PrintGC 13528指令。打开该参数。
此时,我们再返回控制台,发现GC日志已经打开了。
总结
通过jinfo命令,我们可以再生产环境上临时打开GC日志,或者进行一些数据的配置。(不需要重启应用的条件下),也是我们去排查问题的关键命令。
jmap(堆,对象详情,导出dump日志)
我们都知道,堆内存往往使我们调优的重中之重。无论是OOM,还是垃圾回收的回收频率,都与堆内存有着千丝万缕的联系。而堆内存中说白了就存了一个玩意儿,那就是对象。那么jmap就可以给我们提供所有对象的信息,以及堆的各项数据信息。放在医院的案例中,就类似医生让病人去拍一个CT片子。
同时,我们知道对象信息是相当多的。仅仅是CMD窗口是无法显示完的。因此,我们也可以到成dump日志,来仔细分析。(此处,我们完全可以发现这个命令的强大与不便性。因此,未来必然会有工具为我们提供更简单方便的使用机制来替代该命令)。
格式(具体使用例子看options说明)
jmap [option] <pid>
(to connect to running process) 连接到正在运行的进程
jmap [option] executable <core>
(to connect to a core file) 连接到核心文件
jmap [option] [server_id@]<remote server IP or hostname>
(to connect to remote debug server) 连接到远程调试服务
命令中的连接参数说明
(一般我们自己本机使用jmap [option] <pid>指令即可):
executable 可能是产生core dump的java可执行程序
core 将被打印信息的core dump文件
remote-hostname-or-IP 远程debug服务的主机名或ip
server-id 唯一id,假如一台主机上多个远程debug服务
常用options说明
由于jmap的使用较为复杂,因此提供每一个指令的具体写法,方便在开发中直接使用。
-dump:[live,]format=b,file=<filename>(重点使用)
使用hprof二进制形式,输出jvm的heap(堆)内容到文件,[live]子选项是可选的,假如指定live选项,那么只输出活的对象到文件。整个dump日志导出了Java进程在某一时刻的所有堆内存信息。
带live的输出格式:
jmap -dump:live,format=b,file=myjmapfile.txt 19570
全部输出格式:
jmap -dump:format=b,file=myjmapfile.txt 19570
运行结果:

即可在/root目录打开myjmapfile.txt文件。
当然,file=后面也可以指定文件存放的目录,就可以在指定目录查看文件了。
-finalizerinfo
打印正等候回收的对象的信息.
输出格式:
jmap -finalizerinfo 19570
运行结果:
Number of objects pending for finalization: 0 (等候回收的对象为0个)
-heap(重点使用)
打印heap的概要信息,GC使用的算法,heap的配置及wise heap的使用情况。整个堆的概要信息就可以从上帝视角一览无遗。
输出格式:
jmap -heap 19570
运行结果:

-histo[:live] (重点使用)
打印每个class的实例数目,内存占用,类全名信息. VM的内部类名字开头会加上前缀”*”. 如果live子参数加上后,只统计活的对象数量。
采用jmap -histo pid>a.log日志将其保存,在一段时间后,使用文本对比工具,可以对比出GC回收了哪些对象。
jmap -dump:format=b,file=outfile 19570可以将19570进程的内存heap输出出来到outfile文件里,再配合MAT(内存分析工具)。
带live输出格式:
jmap -histo:live 19570
全部输出格式:
jmap -histo 19570
-permstat
打印classload和jvm heap长久层的信息. 包含每个classloader的名字,活泼性,地址,父classloader和加载的class数量. 另外,内部String的数量和占用内存数也会打印出来.
输出格式:
jmap -permstat 19570
jhat(查看jmap导出的dump日志)
jmap导出的dump日志,我们形容相当于医生让我们去拍的CT片子。dump日志往往相当大,我们无法直接对其进行分析。因此,jhat指令正是为分析dump日志而存在的。
格式
jhat [ options ]<dump>
例子:jhat D:/tomcat.bin
有时你dump出来的堆很大,在启动时会报堆空间不足的错误,可以使用如下参数:
jhat -J-Xmx512m <dump>
jhat -J-Xmx1024m D:/tomcat.bin
参数设置
-J< flag > 因为 jhat 命令实际上会启动一个JVM来执行, 通过 -J 可以在启动JVM时传入一些启动参数. 例如, -J-Xmx512m 则指定运行 jhat 的Java虚拟机使用的最大堆内存为 512 MB. 如果需要使用多个JVM启动参数,则传入多个 -Jxxxxxx
-stack false|true 关闭跟踪对象分配调用堆栈。如果分配位置信息在堆转储中不可用. 则必须将此标志设置为 false. 默认值为 true.
-refs false|true 关闭对象引用跟踪。默认情况下, 返回的指针是指向其他特定对象的对象,如反向链接或输入引用(referrers or incoming references), 会统计/计算堆中的所有对象。
-port port-number 设置 jhat HTTP server 的端口号. 默认值 7000。
-exclude exclude-file 指定对象查询时需要排除的数据成员列表文件。 例如, 如果文件列出了 java.lang.String.value , 那么当从某个特定对象 Object o 计算可达的对象列表时, 引用路径涉及 java.lang.String.value 的都会被排除。
-baseline exclude-file 指定一个基准堆转储(baseline heap dump)。 在两个 heap dumps 中有相同 object ID 的对象会被标记为不是新的(marked as not being new). 其他对象被标记为新的(new). 在比较两个不同的堆转储时很有用。
-debug int 设置 debug 级别. 0 表示不输出调试信息。 值越大则表示输出更详细的 debug 信息。
-version 启动后只显示版本信息就退出。
使用小技巧
首先先找到dump文件的目录,使用指令:jhat -J-Xmx1024m D:/tomcat.bin
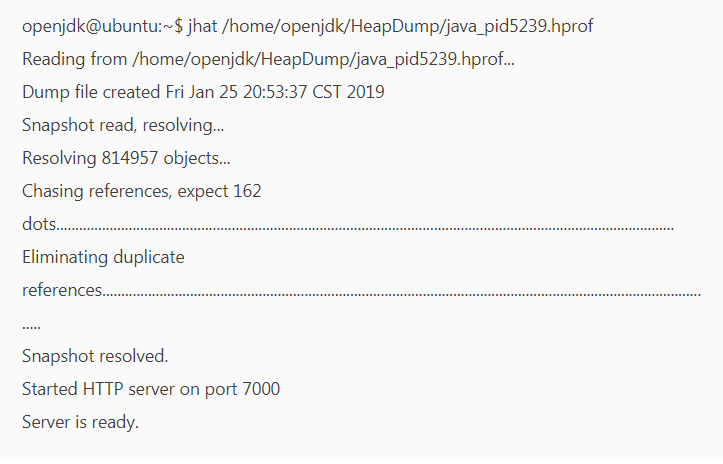
这样就启动起来了一个简易的HTTP服务,端口号是7000,尝试一下用浏览器访问一下它,本地的可以通过http://localhost:7000,就可以得到这样的页面:
jstack(栈详情,排查死锁,死循环,请求资源超时神器)
我们学了jmap,知道它主要负责堆和对象的信息管理。而运行时数据区中的栈区,同样占有不可忽略的地位。
jstack是jdk自带的线程堆栈分析工具,使用该命令可以查看或导出 java 应用程序中线程堆栈信息。
jstack用于生成java虚拟机当前时刻的线程快照。线程快照是当前java虚拟机内每一条线程正在执行的方法堆栈的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等。 线程出现停顿的时候通过jstack来查看各个线程的调用堆栈,就可以知道没有响应的线程到底在后台做什么事情,或者等待什么资源。 如果java程序崩溃生成core文件,jstack工具可以用来获得core文件的java stack和native stack的信息,从而可以轻松地知道java程序是如何崩溃和在程序何处发生问题。另外,jstack工具还可以附属到正在运行的java程序中,看到当时运行的java程序的java stack和native stack的信息, 如果现在运行的java程序呈现hung的状态,jstack是非常有用的。
由此总结出,这个指令如果派上用场了,那多半是你的代码有问题,该挨板子了!
格式
jstack [ option ] pid
查看当前时间点,指定进程的dump堆栈信息。
jstack [ option ] pid > 文件
将当前时间点的指定进程的dump堆栈信息,写入到指定文件中。注:若该文件不存在,则会自动生成;若该文件存在,则会覆盖源文件。
jstack [ option ] executable core
查看当前时间点,core文件的dump堆栈信息。
jstack [ option ] [server_id@]<remote server IP or hostname>
查看当前时间点,远程机器的dump堆栈信息。
参数说明
options
-F 当进程挂起了,此时'jstack [-l] pid'是没有相应的,这时候可使用此参数来强制打印堆栈信息,强制jstack),一般情况不需要使用。
-m 打印java和native c/c++框架的所有栈信息。可以打印JVM的堆栈,以及Native的栈帧,一般应用排查不需要使用。
-l 长列表. 打印关于锁的附加信息。例如属于java.util.concurrent的ownable synchronizers列表,会使得JVM停顿得长久得多(可能会差很多倍,比如普通的jstack可能几毫秒和一次GC没区别,加了-l 就是近一秒的时间),-l 建议不要用。一般情况不需要使用。
-h or -help 打印帮助信息。
使用小技巧
jps查看java进程:
临时查看:jstack查看指定进程的当前堆栈情况: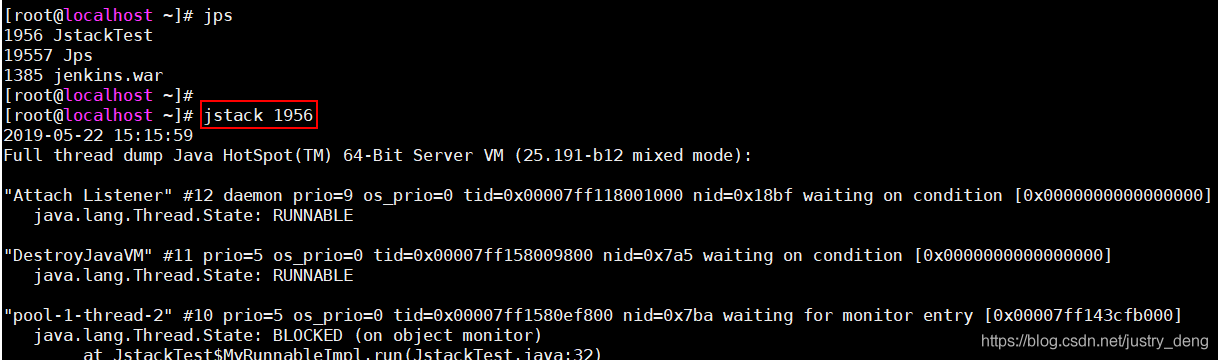
持久化查看:将指定进程的当前堆栈情况记录到某个文件中:

调优思路
小白进阶调优大神——OOM导致的CPU占有率过高调优实战
讲了这么多指令,但是不经过实战的融汇贯通,我们是无法运用自如的。因此,我们举一些小的实战例子,并归纳调优的思路。
案例分析
现有以下程序。
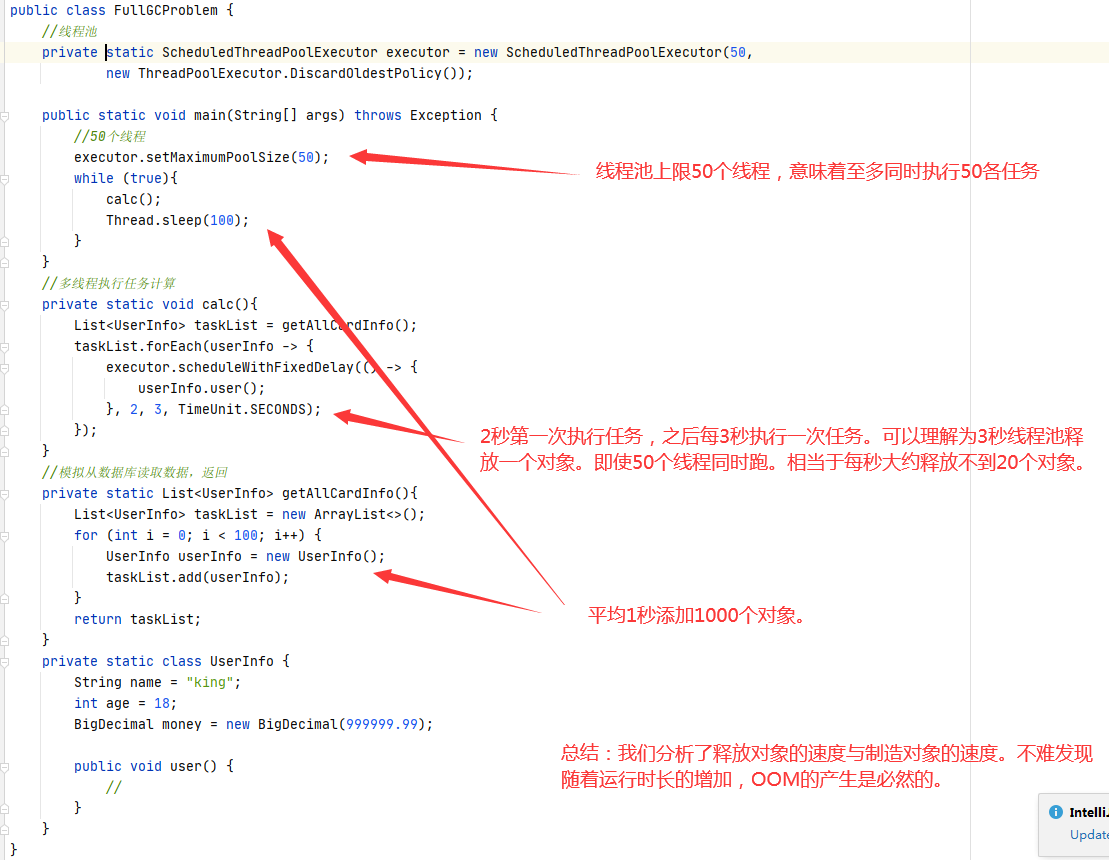
在本案例中,我们自己模拟了一个OOM的场景。具体的代码分析在图中解释已经较为详细了。那么,假设我们的工程非常庞大,这个问题出现了无法通过代码排查,此时我们就可以撸起袖子进入我们的调优环节了。
步骤一:启动程序
在 Linux 服务跑起来
使用命令:java -cp JVMOTHERS-1.0-SNAPSHOT.jar -XX:+PrintGC -Xms200M -Xmx200M JVM调优/FullGCProblem
步骤二:发现程序卡顿,定位责任人
一段时间后会发现整个操作系统逐渐变得卡顿。此时,作为Java程序员的我们第一步是要排查是否是我们的Java进程导致的操作系统卡顿。
top 命令是我们在 Linux 下最常用的命令之一,它可以实时显示正在执行进程的 CPU 使用率、内存使用率以及系统负载等信息。其中上半部分显示的是系统的统计信息,下半部分显示的是进程的使用率统计信息。
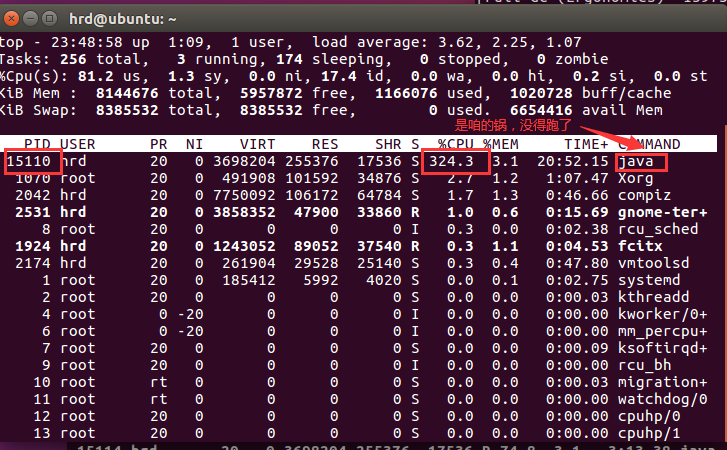
步骤三:监控该进程下的所有线程
输入命令top -Hp 15110),获取该进程下所有的线程信息,通过观察,我们找到线程编号为15112,15113,15114 , 15115的线程非常消耗CPU。(需要运行一段时间)
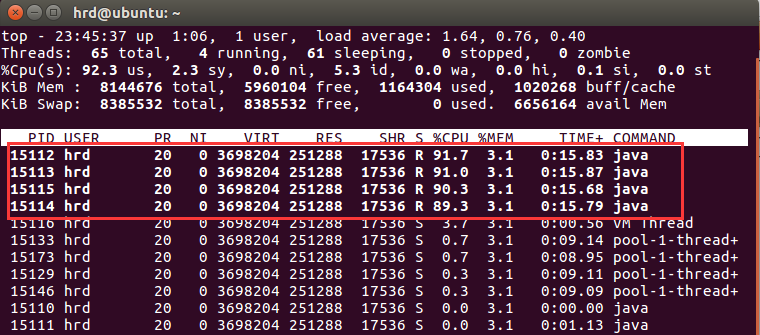
调优往往由简入难。我们知道jmap可以帮我们排查堆与对象的详细信息。但是这个分析起来较为繁琐复杂。我们在top指令中已经获取到了这些导致CPU飙升的线程号,于是我们联想到jstack可以为我们截取一个线程快照。在这个快照中,我们可以根据这些线程号,查看到这些线程的线程名(因此,阿里这些大厂都规定只要创建线程就必须起名。这样在排查问题时才不至于定位到了线程名你却不认识)。
那么定位线程名该如何操作呢?
步骤四:使用jstack,用线程ID定位线程名
首先,先剧透一下。在jstack中的线程号都是16进制的。因此,我们需要先把出问题的线程号从10进制转换为16进制。在此以线程号15112为例。
百度查找进制转换工具,轻松转换为不同进制值。
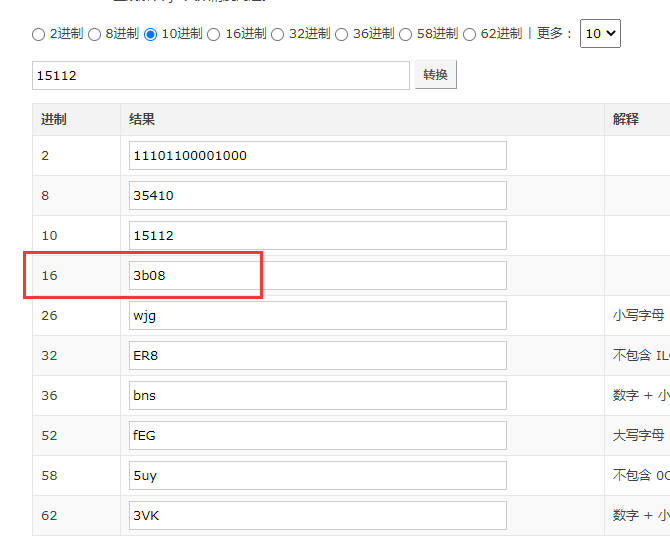
得到15112的16进制为3b08。
使用指令:jstack 15110查看线程信息。
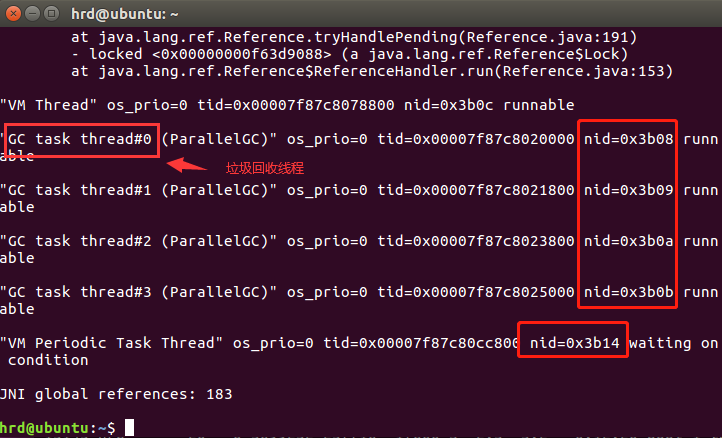
很轻松地定位到了,出问题的线程是GC线程。
步骤五:使用我们的贴心护工jstat,实时监控GC
既然定位到了是GC线程造成的异常,那么jstat每 2.5 s查询一次进程 15110 垃圾收集状况,一共查询 10 次,那命令应当是:jstat-gc 15110 2500 10
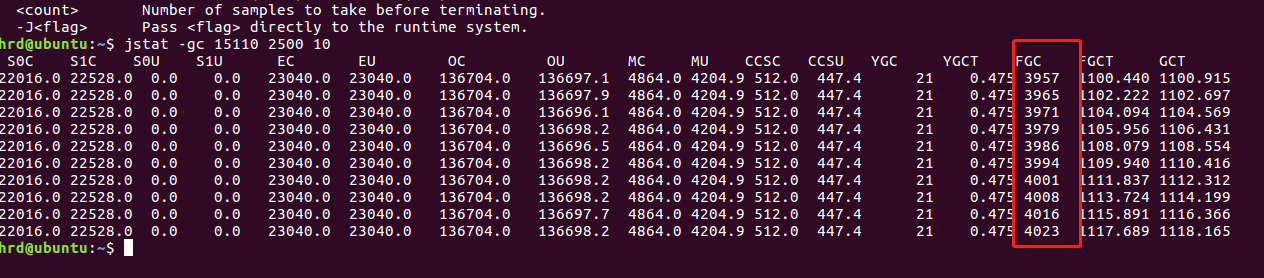
我们发现2.5s内 就能进行个7,8次。
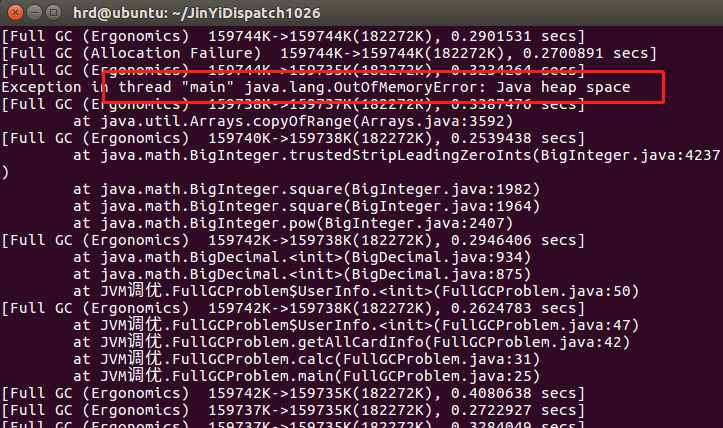
在程序运行界面也抛出了OOM异常
步骤六:问题原因分析
或许你第一次看到,会觉得GC线程不是我写的啊。为啥他能出问题呢?
虽然GC线程不是咱们自己写的。但是人家是帮我们扫垃圾的呀。如果你的垃圾生产的比人家清理的还快,那可不就出问题了嘛。
从我们的架构入手思考,我们可以参考下图:
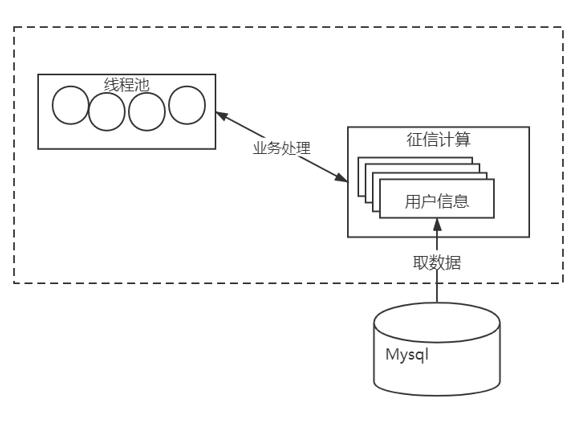
我们的程序属于典型的业务处理速度跟不上获取数据的速度。因此,产生了OOM。
以上案例就是说的三板斧,很简单却也使用。大部分简单的问题都可以排查的七七八八。当对命令有了更深刻的了解时,可以用出更多的花样。
省三甲医院——运维人员的福音Arthas
简介
首先,现在的进阶工具多到数不胜数。然而即使一个工具再过于强大,也一定是有它大概的使用定位。Arthas强大如斯,但它的使用场景更多适用于运维层面。
Arthas 是Alibaba开源的Java诊断工具。安装在系统所在服务器。可以帮助开发人员或者运维人员查找问题,分析性能,bug追踪。
解决的问题 & 适用场景
解决问题:
1、以全局视角来查看系统的运行状况、健康状况。
2、反编译源码,查看jvm加载的是否为预期的文件内容。
3、查看某个方法的返回值,参数等等。
4、方法内调用路径及各方法调用耗时。
5、查看jvm运行状况。
6、外部.class文件重新加载到jvm里。
等等.....
场景:
1)调用接口时,接口返回异常信息,如果该异常信息没有清晰的定位到代码,那么我们通常只能依靠大脑回忆代码,来估计错误发生地了,如果无法估计,一般情况下就会进入测试环境,模拟复现,如果无法复现 _。
2)这个查询,耗时20s,我们想要分析一下到底是哪些代码导致的。但是该方法内部又穿插调用了其它业务功能方法,难道手写System.currentTimeMillis()自己做减运算,还是guava的StopWatch亦或是commons的StopWatch?这几种方式需要我们手动嵌入代码,容易遗漏、费力还费时。
等等,就不一一举例了。
arthas可以为我们解决上述问题,帮助程序员尽早下班,尽早交代。
使用说明与简单的运用
安装
不需要安装,就是一个 jar 包
下载: wget https://alibaba.github.io/arthas/arthas-boot.jar
启动 java -jar arthas-boot.jar
启动
通过 jps 命令快速查找 java 进程,再次直接绑定 java -jar arthas-boot.jar pid启动 arthas 工具 attach 到目标进程
 进入 arthas 后命令行前面出现标识
进入 arthas 后命令行前面出现标识

常用命令
注意在 arthas 中,有 tab 键填充功能,所以比较好用。但是这个界面是实时刷新的,一般 5s 刷新一次,使用 q 键退出刷新(没有退出 arthasq)
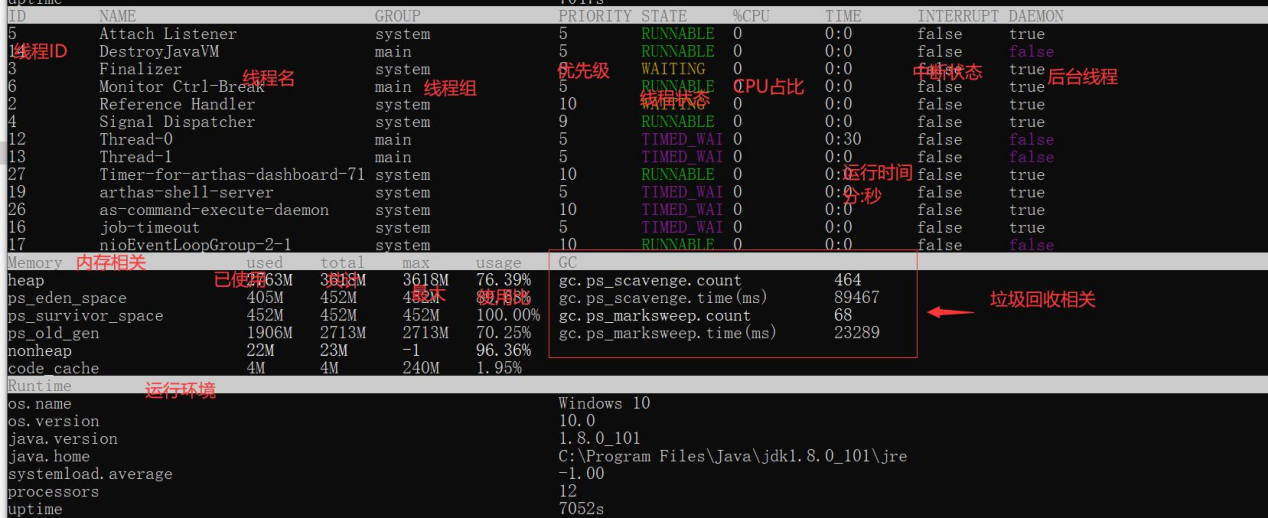
dashboard(主监控)
仪表盘显示当前进程相关信息。这个真的是神一样的命令。就是一个JVM的主监控。并且Arthas默认5s刷新一次,可以反馈出数据变化趋势。大拿只看这个界面就能定位出相当多的问题了。
thread(线程信息,检查死锁)
这个命令和 jstack 很相似,但是功能更加强大,主要是查看当前 JVM 的线程堆栈信息,同时可以结合使用 thread –b 来进行死锁的排查死锁。
参数解释
-h 显示帮助
-b 查找死锁
-n 指定最忙的前 n 个线程并打印堆栈-b 找出阻塞当前线程的线程
-i 指定 cpu 占比统计的采样间隔,单位为毫秒
--state 根据线程状态筛选线程
实战演示
thread -h 显示帮助
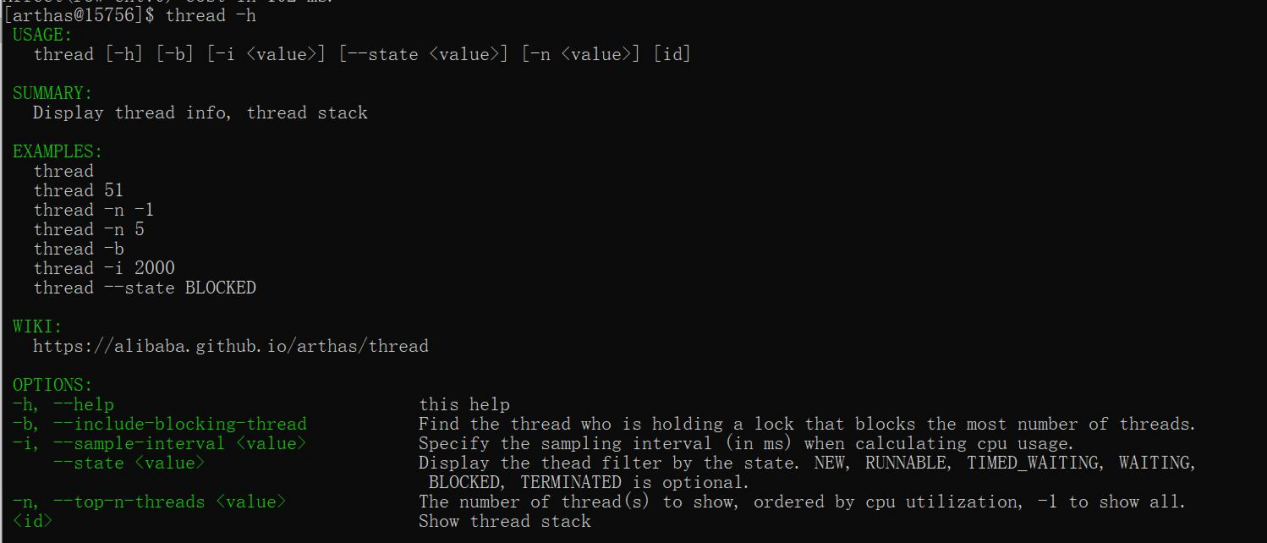
-h 的EXAMPLES中的示例是真的方便。记不清楚的指令提示你,配合tab填充,方便更加高效的打工。
thread -b 找出当前进程的阻塞线程
先来个找不到的例子

再来个找到的例子,如果有死锁也会显示的非常明确。

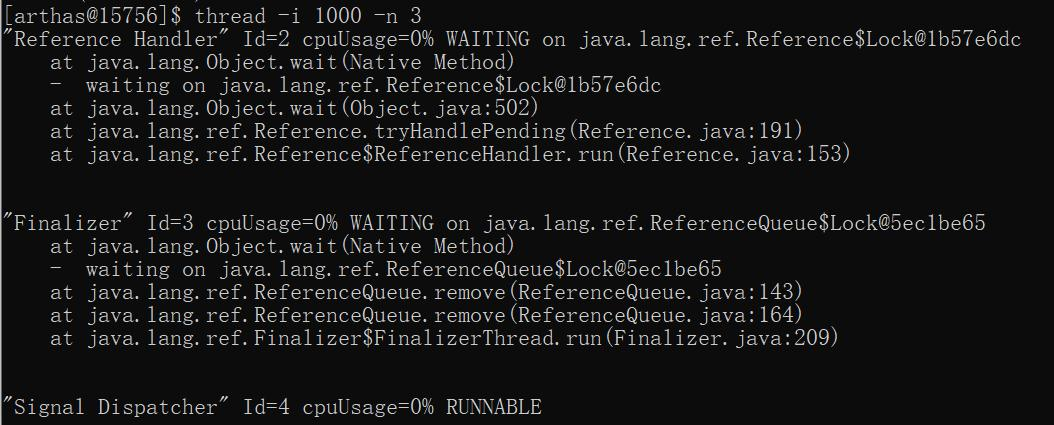
thread -i 1000 -n 3
每过 1000 毫秒进行采样,显示最占 CPU 时间的前 3 个线程
thread --state WAITING
查看处于等待状态的线程

jvm(查看当前JVM的信息)
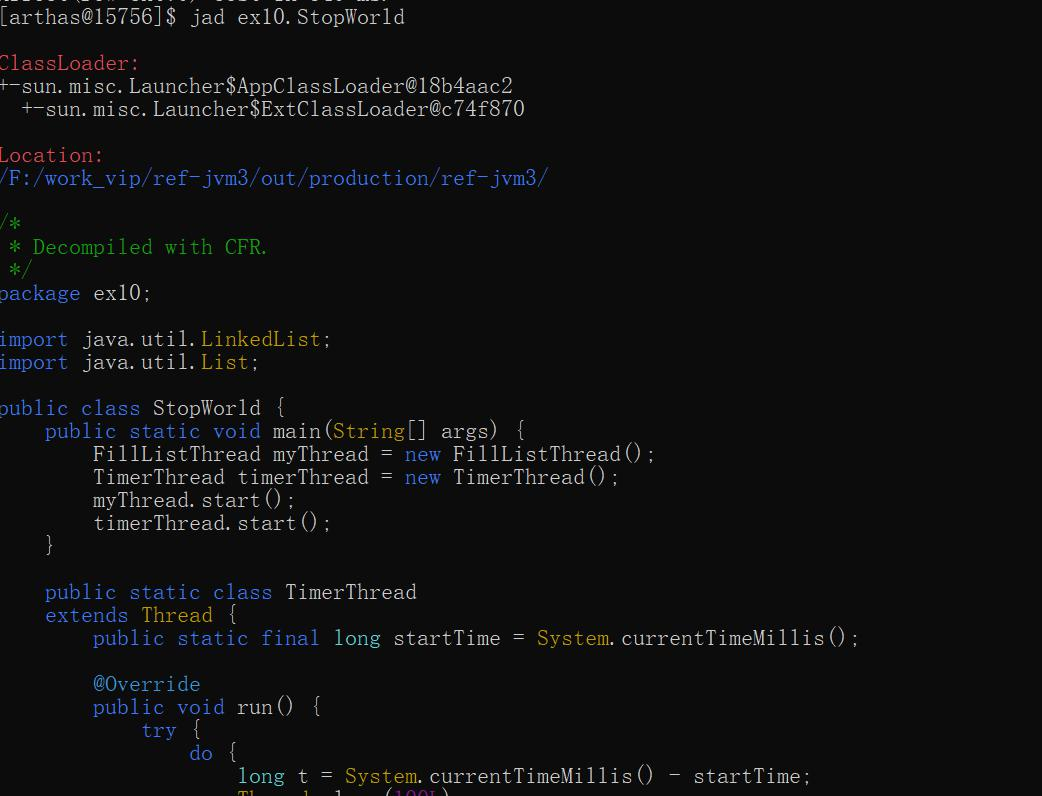
jad(反编译已加载类的源码)
这个功能实在是牛逼。直接把运行中的程序反编译成我们的java代码。如果我们用了语法糖,或者一些冷门语法,这个功能也可以帮我们查看原生程序的写法。前提是我们需要知道这个类的根路径。
trace(跟踪方法耗时)
比如使用一个 Springboot 项目(当然,不想 Springboot 的话,你也可以直接在 UserController 里 main 方法启动)控制层 getUser 方法调用了 userService.get(uid);,这个方法中分别进行 check、service、redis、mysql 等操作操作。就可以根据这个命令跟踪出来哪里的耗时最长,当然,一个方法中可能嵌套了许多方法。因此,我们还可以根据耗时时间进行筛查。
这让我们对问题的定位有了极大地提升,方法都是一层一层的调用的。因此很难定位到具体造成延迟的方法。trace将我们解决了这个难题。
基本用法
trace 类路径 方法名

按照时间过滤
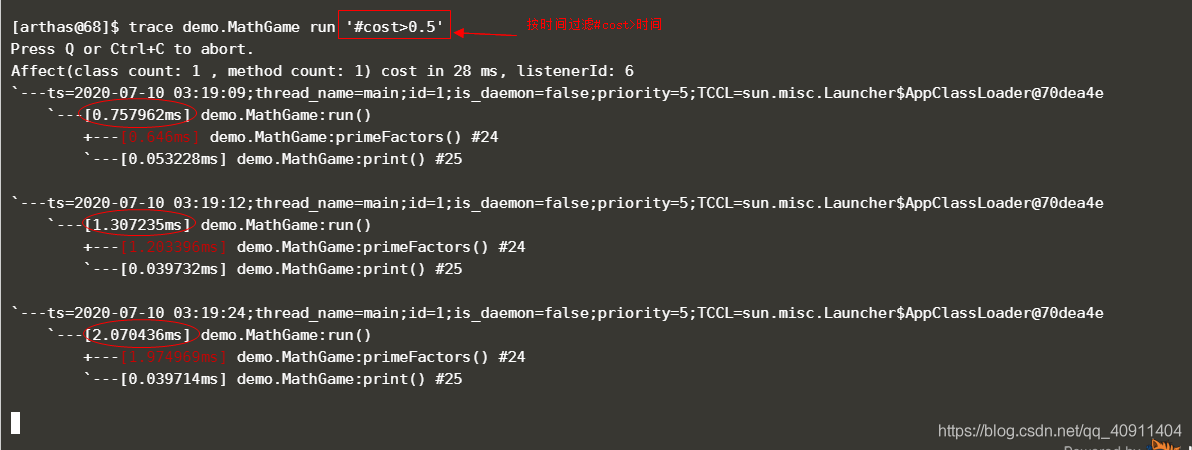
trace 类路径 方法名 '#cost>时间(ms)'
可以看到过滤以后,观察到的都是时间大于0.5ms的该方法的调用
monitor(定时统计一次方法的执行情况)
指令:monitor -c 5 cn.enjoyedu.demo.controller.DemoController
效果如下:

watch(观察方法的出/入参)
首先,我们需要明确方法的出入参数个数,在指令中用类似于占位符的形式填充。
第一步:输入指令 watch cn.enjoyedu.demo.controller.DemoController test '{params[0],returnObj}

第二步:触发该方法,就会捕获其出/入参数

第三步:观察参数

总结
Arthas的强大,我相信如果自信看到这里的朋友已经感受颇深了。但是Arthas在分析堆,分析对象这方面似乎略有欠缺。毕竟它再强大也仅仅是一个窗口运行的小程序。而我们要分析jmap导出的轻易几个G大小的dump文件,似乎依然不够方便。那么如果我们要分析堆和对象有没有对应的神器呢?
省三甲医院——开发人员的杀手锏MAT
简介
我们刚讲过Arthas,大家都已经很清楚它的强大了。对整个运行时数据区的监控,方法的监控,等都让其"省三甲医院"的称号稳如泰山。而即使这么强大的工具,在动辄几个G的dump日志也是难以分析的。
此时就诞生了强大的MAT工具。他相当于一个进阶版的jhat指令,协助我们去分析jmap导出的堆内存以及对象信息。
MAT 工具是基于 Eclipse 平台开发的,本身是一个 Java 程序,是一款很好的内存分析工具。
堆快照对比的前置条件
正如之前所说,MAT对比的dump日志往往是非常大的。如果你的堆快照过大的话,则需要一台内存比较大的分析机器,并给 MAT 本身加大初始内存,这个可以修改安装目录中的 MemoryAnalyzer.ini 文件。
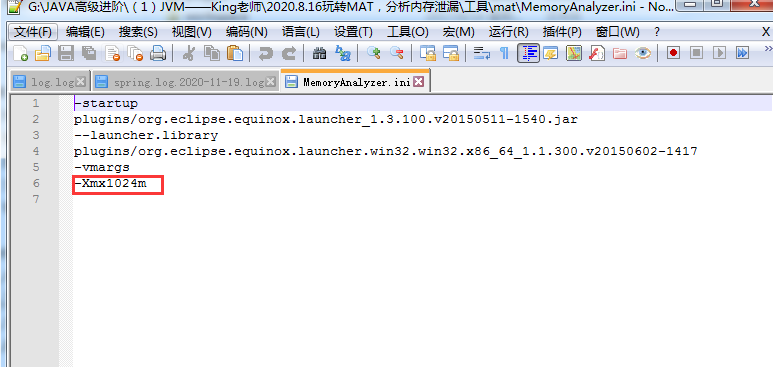
导入dump日志
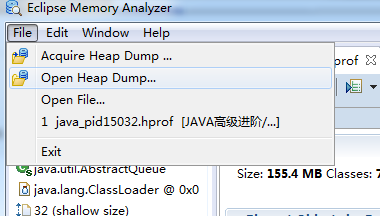
主页概览
Incoming/Outgoing
首先开启柱状图

在柱状图中,我们看到,其实它显示的东西跟 jmap –histo 非常相似的,也就是类、实例数量、空间大小。
但是 MAT 有一个专业的概念,这个可以显示对象的引入和对象的引出。
在 Eclipse MAT 中,当右键单击任何对象时,将看到下拉菜单。如果选择“ListObjects”菜单项,则会注意到两个选项:
1. with incoming references 对象的引入 (该类对象被哪些对象引入)
2. with outgoing references 对象的引出 (该类对象引入的其他对象)
是不是感觉怪怪的。后续我们会对括号中的结论进行验证。
概念理解
我们说两个类直接的关系除了继承之外,还可以是组合。
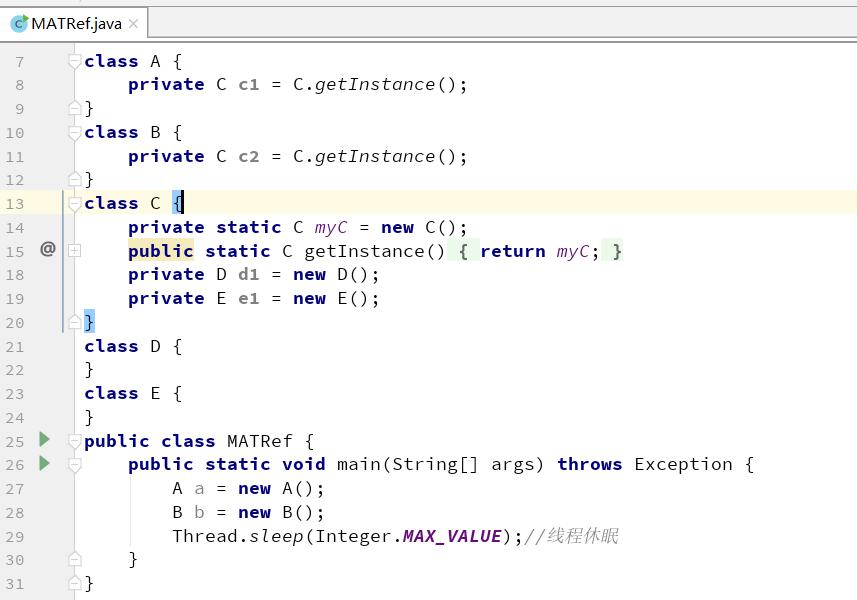
我们根据上述代码可以画出各类的组合关系图:
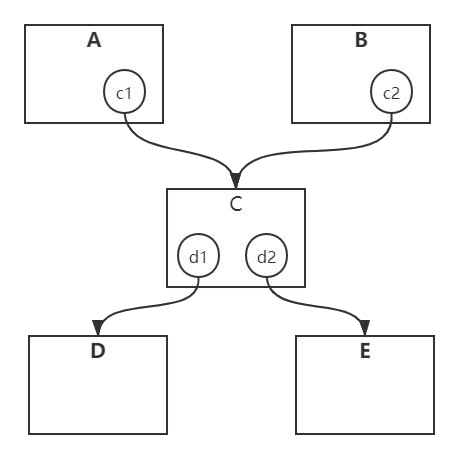
代码中对象和引用关系如下:
对象 A 和对象 B 持有对象 C 的引用。
对象 C 持有对象 D 和对象 E 的引用 。
引入用关系链的查看方式
第一步:动态获取运行中的程序的内存信息快照
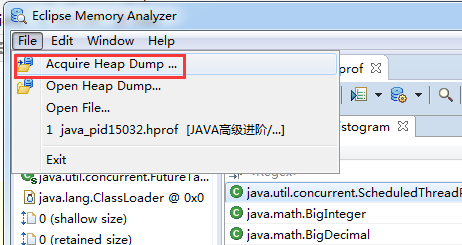
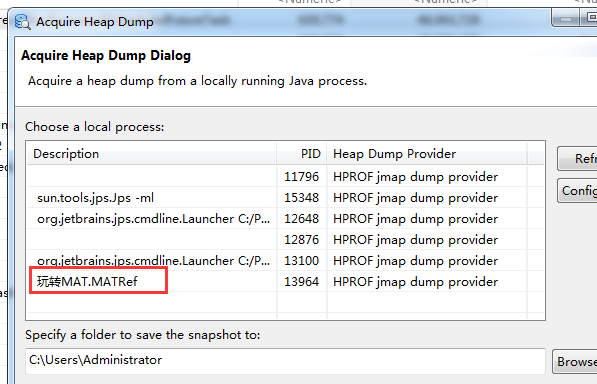
第二步:由于主页是随机的类的显示,我们选择根据包名归类,方便我们定位到我们自己的类。
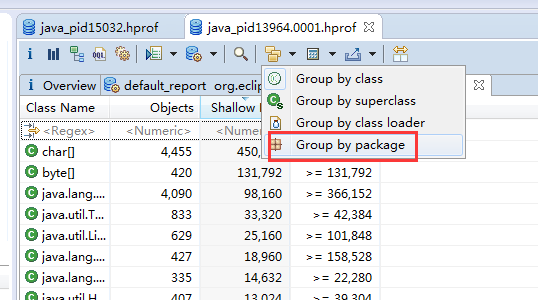
第三步,找到了我们自己的包名下所有的类,可以选择该类的引入/引出选项。
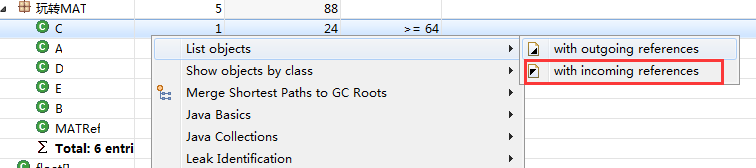
第四步,我们查看引入(incoming)关系。
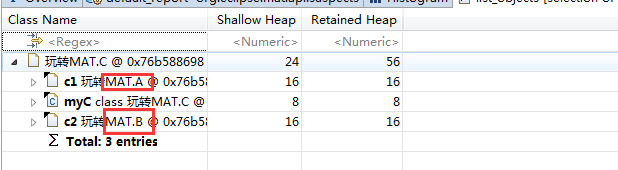
发现了A,B的对象。验证了我们开始的结论。(虽然是incoming,却查出的是被引用的类,感觉是有点怪)。
相反的,outgoing reference代表本类所持有哪些类的对象。

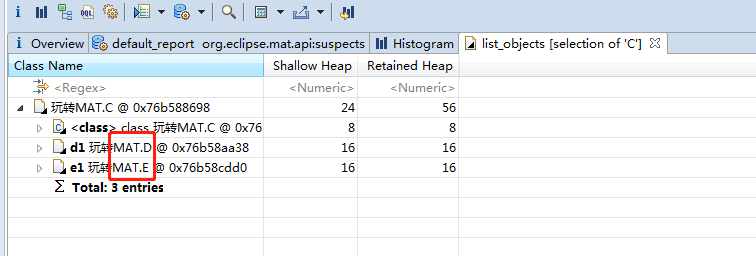
这个 outgoing references 和 incoming references 非常有用,因为我们做 MAT 分析一般时对代码不了解,排查内存泄漏也好,排查问题也好,垃圾回收中有一个很重要的概念,可达性分析算法,那么根据这个引入和引出,我就可以知道这些对象的引用关系,在 MAT 中我们就可以知道比如 A,B,C,D,E,F 之间的引用关系图,便于做具体问题的分析。
深堆/浅堆
概念理解
浅堆(shallow heap)
代表了对象本身的内存占用,包括对象自身的内存占用,以及“为了引用”其他对象所占用的内存。
深堆(Retained heap)
是一个统计结果,会循环计算引用的具体对象所占用的内存。但是深堆和“对象大小”有一点不同,深堆指的是一个对象被垃圾回收后,能够释放的内存大小,这些被释放的对象集合,叫做保留集(Retained Set)
Java对象内存大小的计算方式
JAVA 对象大小=对象头+实例数据+对齐填充
非数组类型
浅堆(shallow_size)=对象头+各成员变量大小之和+对齐填充
其中,各成员变量大小之和就是实例数据,如果存在继承的情况,需要包括父类成员变量
数组类型
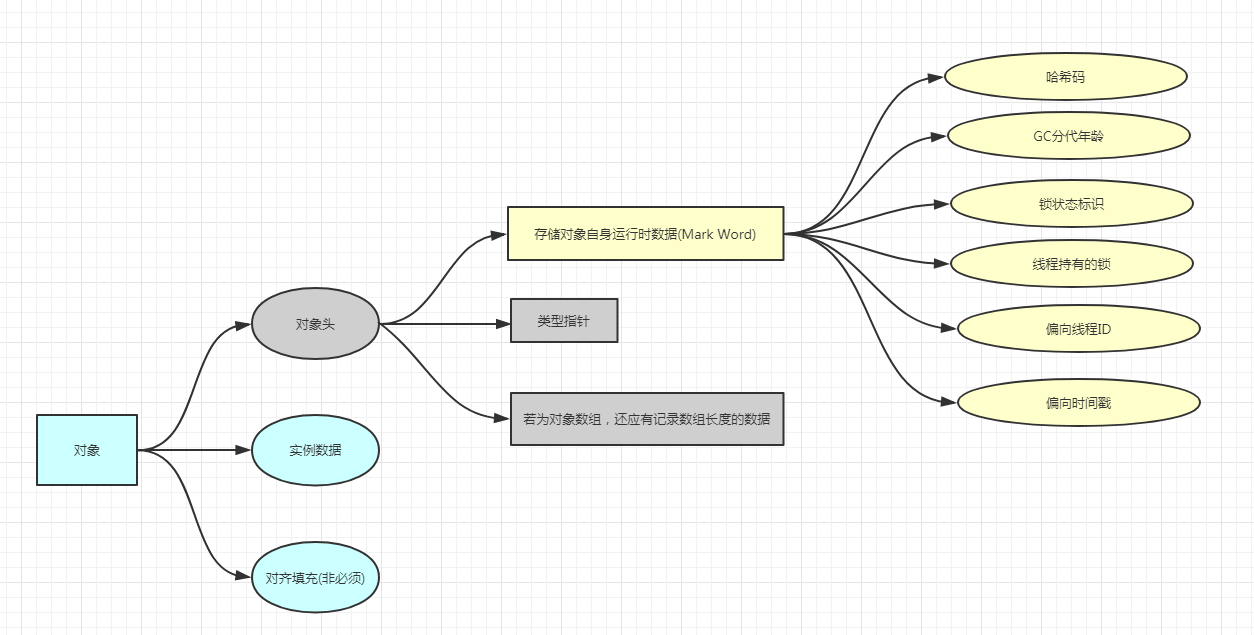
如图,数组相对于普通对象略有区别:深堆(Retained _size)=对象头+类型变量大小*数组长度+对齐填充,如果是引用类型,则是四字节或者八字节(64 位系统),如果是 boolean 类型,则是一个字节 。
注意:这里类型变量大小*数组长度 就是实例数据,强调是变量不是对象本身。
用案例理解深堆浅堆的概念
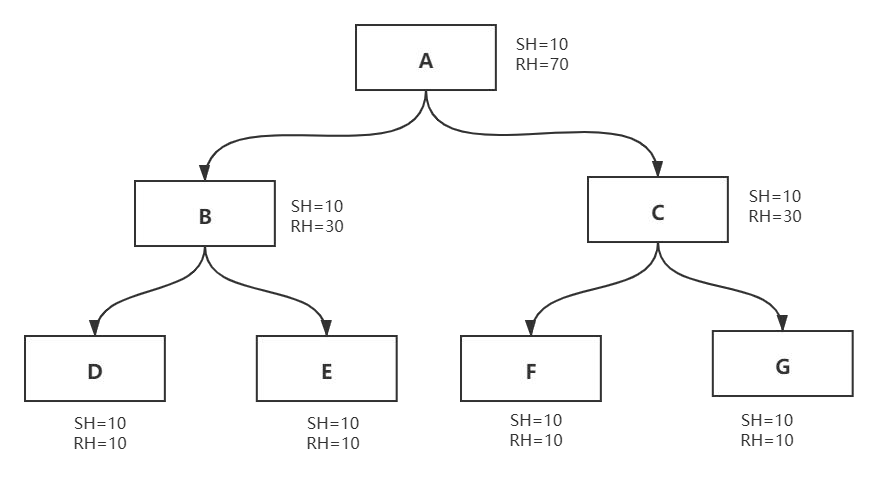
对象 A 持有对象 B 和 C 的引用。
对象 B 持有对象 D 和 E 的引用。
对象 C 持有对象 F 和 G 的引用。
一句话,浅堆就是自身对象大小,那么深堆就是根可达分析自己后面的引用链对象总大小+自己的大小呢?我们接着看。往往深堆更能体现出一个对象的回收价值。
引用变动对对象深堆的影响
在下面的示例中,让对象 H 开始持有对 B 的引用。注意对象 B 已经被对象 A 引用了。
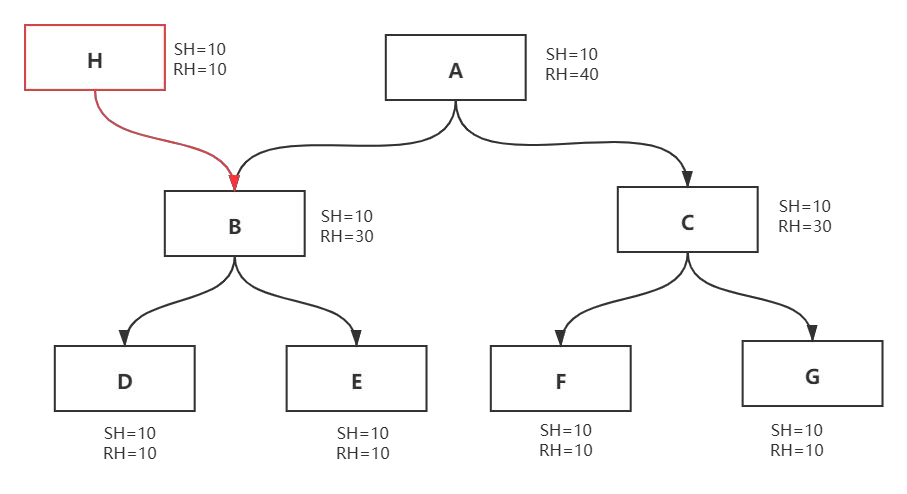
在这种情况下,对象 A 的 Retained heap 大小将从之前的 70 减小到 40 个字节
如果对象 A 被垃圾回收了,则将仅会影响 C、F 和 G 对象的引用。因此,仅对象 C、F 和 G 将被垃圾回收。另一方面,由于 H 持有对 B 的活动引用,因此对象 B、D 和 E 将继续存在于内存中。因此,即使 A 被垃圾回收,B、D 和 E 也不会从内存中删除。因此,A 的 Retained heap 大小为:= A的 shallow heap 大小 + C 的 shallow heap 大小 + F 的 shallow heap 大小 + G 的 shallow heap 大小 = 10 bytes + 10 bytes + 10 bytes + 10 bytes = 40
bytes.
深堆/浅堆概念存在的意义
因此我们说深堆大小并不能直接从引用链的角度来分析,而是要站在垃圾回收的根可达分析算法的角度,看这个对象会收的后真正可以释放的内存大小。我们分析问题时,往往去那些深堆很大,尤其那些浅堆比较小,但深堆比较大的对象。它们极有可能是有问题的对象。
使用MAT分析内存泄漏
我们现在来分析一组看着困难,实际简单的内存泄漏案例
内存泄漏的案例分析
对象引用关系

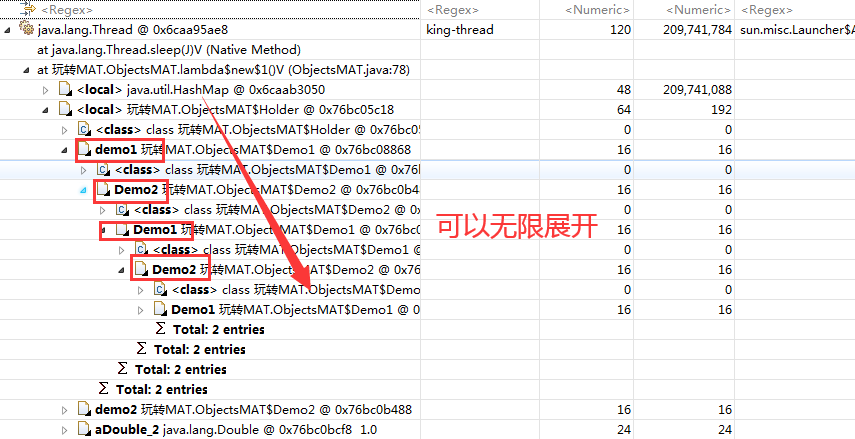
可以看到引用关系为A引出B,B引出C。C中持有一个List。

紧接着有Demo1,Demo两个类相互引用,并且有一个Holder类引出他们两个对象。
任务与实现类

案例关系图
经过简单的分析,这个代码就已经很明了了。这里再画一张结构图加深理解。
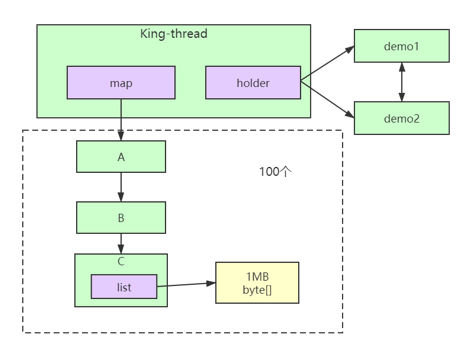
使用MAT分析泄漏原因
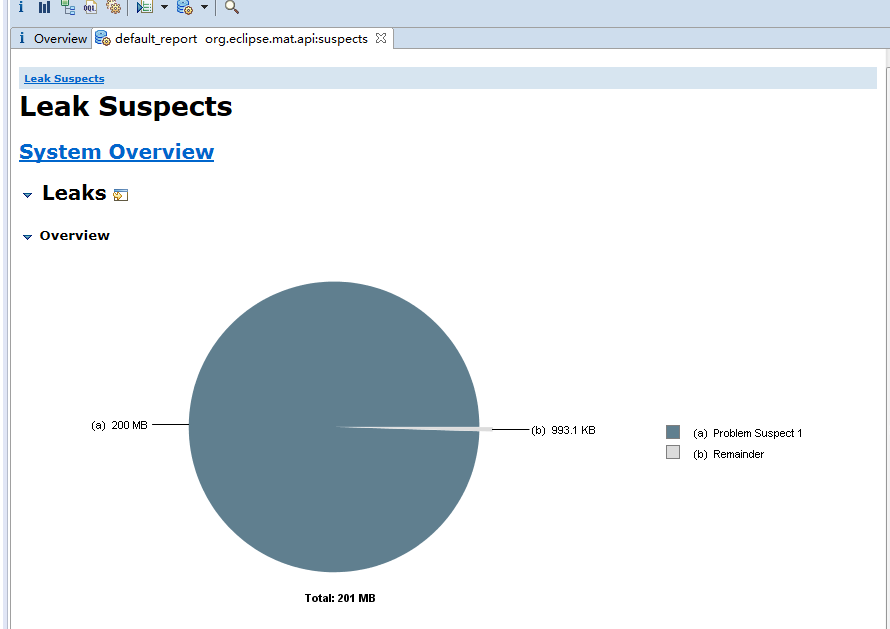
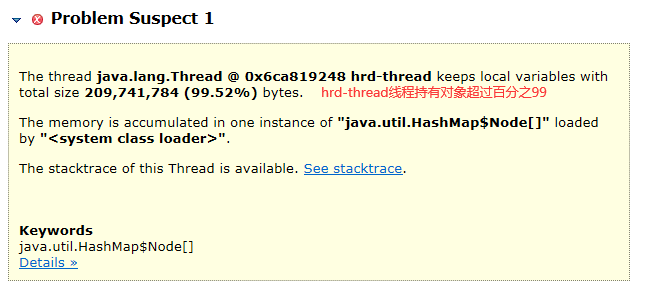
当我们产生问题时,MAT会帮助我们进行问题猜测。这个程序的泄漏很明显,就是线程无法结束,线程持有的对象都无法被垃圾回收。
而经过我们代码分析,我们知道我们一直在随机生成list,再将list存入map中。而又因为线程的长时间休眠,导致map一直无法被GC导致被泄漏。
我们再看上面的黄色截图。发现MAT已经帮我们进行了问题预测。hrd-thread 的线程,持有了超过 99% 的对象,数据被一个 HashMap 所持有。
这个就是内存泄漏的点,由于代码中对线程取了别名,因此可以更快的定位问题线程。所以像阿里等公司的编码规范中为什么一定要给线程取名字,这个是有依据的,如果不取名字的话,这种问题的排查将非常困难。
于特别明显的内存泄漏,在这里能够帮助我们迅速定位,但通常内存泄漏问题会比较隐蔽,我们需要做更加复杂的分析。
MAT的统计图的用途实战
支配树视图(运用深堆浅堆分析泄漏)
支配树列出了堆中最大的对象,第二层级的节点表示当被第一层级的节点所引用到的对象,当第一层级对象被回收时,这些对象也将被回收。这个工具可以帮助我们定位对象间的引用情况,以及垃圾回收时的引用依赖关系。支配树视图对数据进行了归类,体现了对象之间的依赖关系。我们通常会根据“深堆”进行倒序排序,可以很容易的看到占用内存比较高的几个对象,点击前面的箭头,即可一层层展开支配关系(依次找深堆明显比浅堆大的对象)。
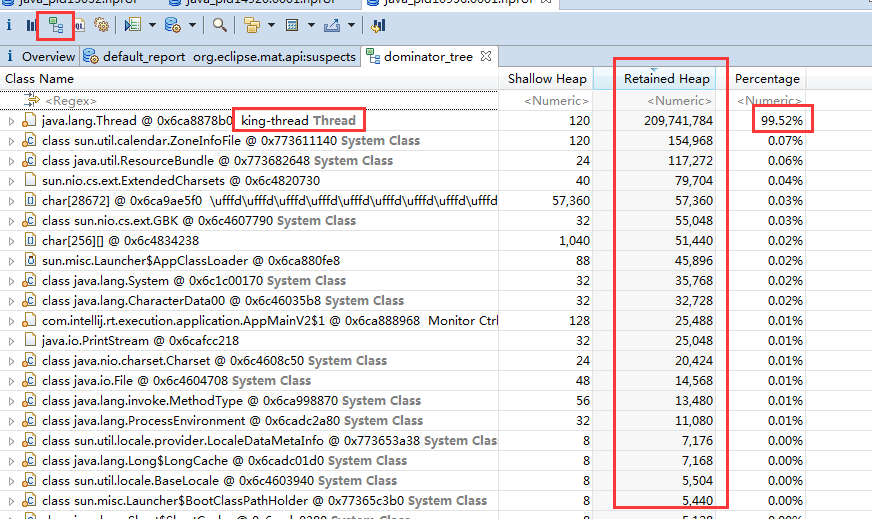
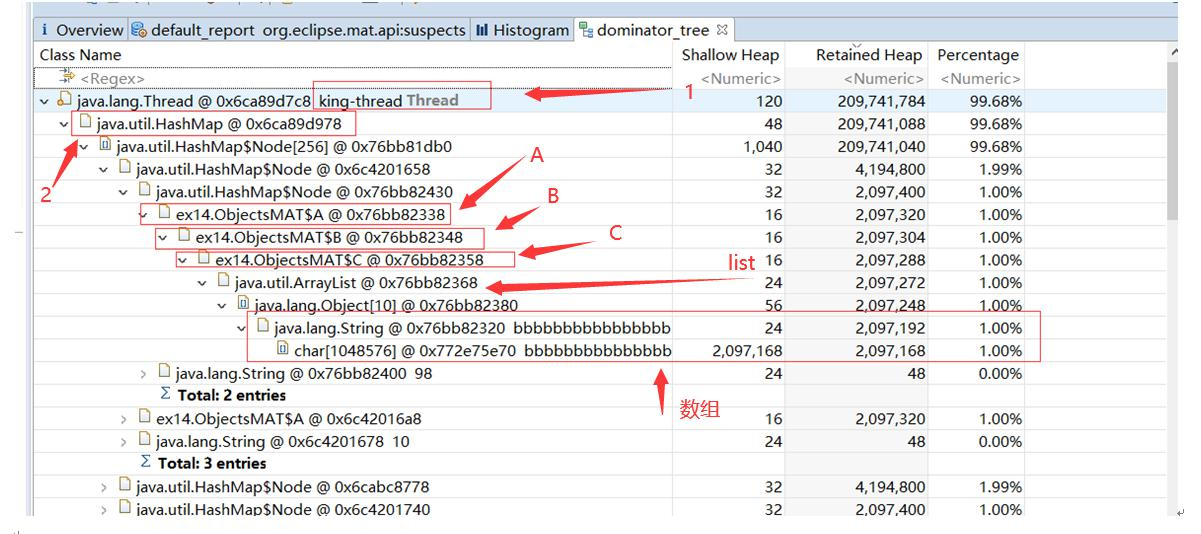
从上图层层分解,我们也知道,原来是 hrd-thread 的深堆比浅堆比例很多(深堆比浅堆多很多、一般经验都是找那些浅堆比较小,同时深堆比较大的对
象)
1、 一个浅堆非常小的 hrd-thread 持有了一个非常大的深堆
2、 这个关系来源于一个 HashMap
3、 这个 map 中有对象 A,同时 A 中引用了 B,B 中引用了 C
4、 最后找到 C 中里面有一个 ArrayList 引用了一个大数据的数组。
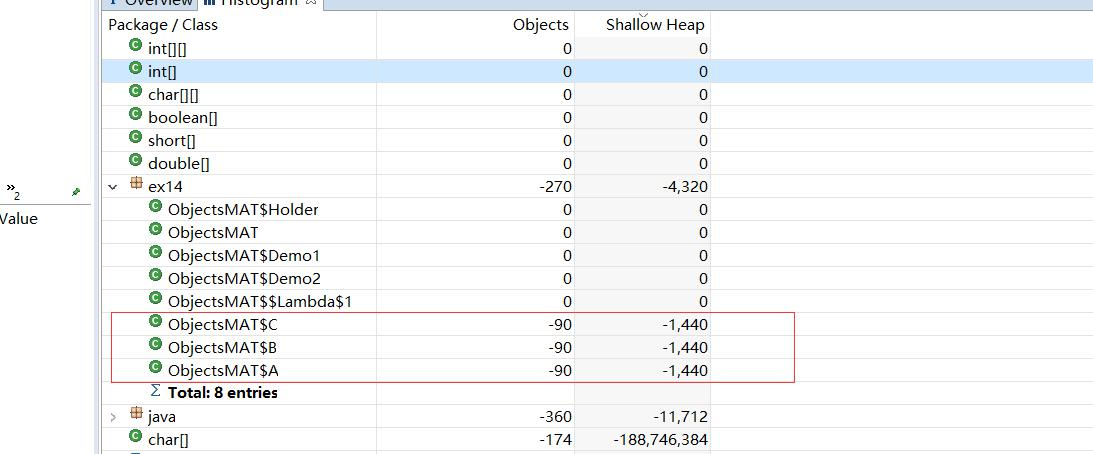 经过分析,内存的泄漏点就在此。线程中的map长期持有100个超大的ArrayList ,有可能导致内存泄漏。
经过分析,内存的泄漏点就在此。线程中的map长期持有100个超大的ArrayList ,有可能导致内存泄漏。
dump对比图(对不同的dump日志)
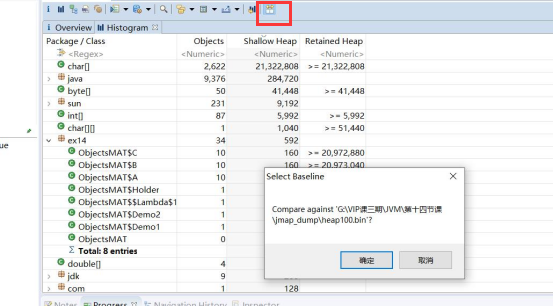
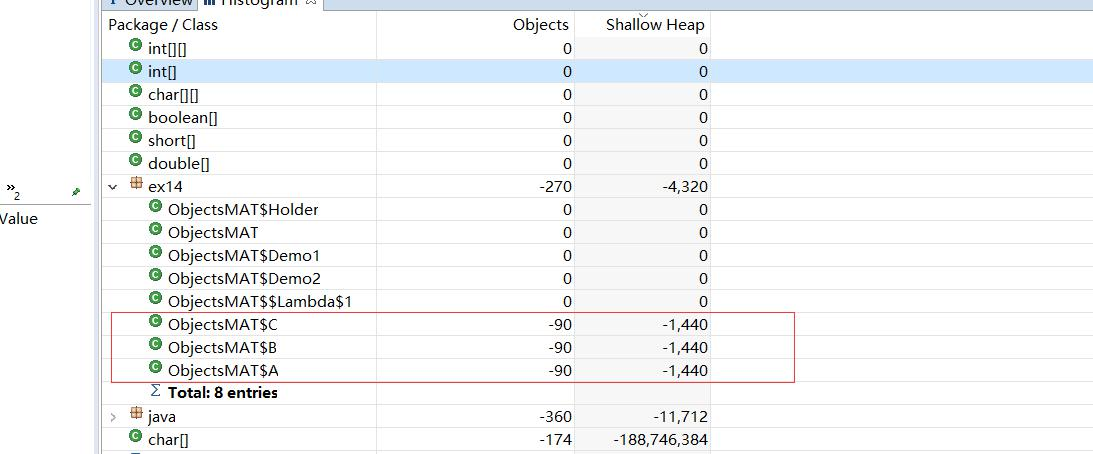
我们对于堆的快照,其实是一个“瞬时态”,有时候仅仅分析这个瞬时状态,并不一定能确定问题,这就需要对两个或者多个快照进行对比,来确定一个增长趋势。我们导出两份 dump 日志,分别是上个例子中循环次数分别是 10 和 100 的两份日志。
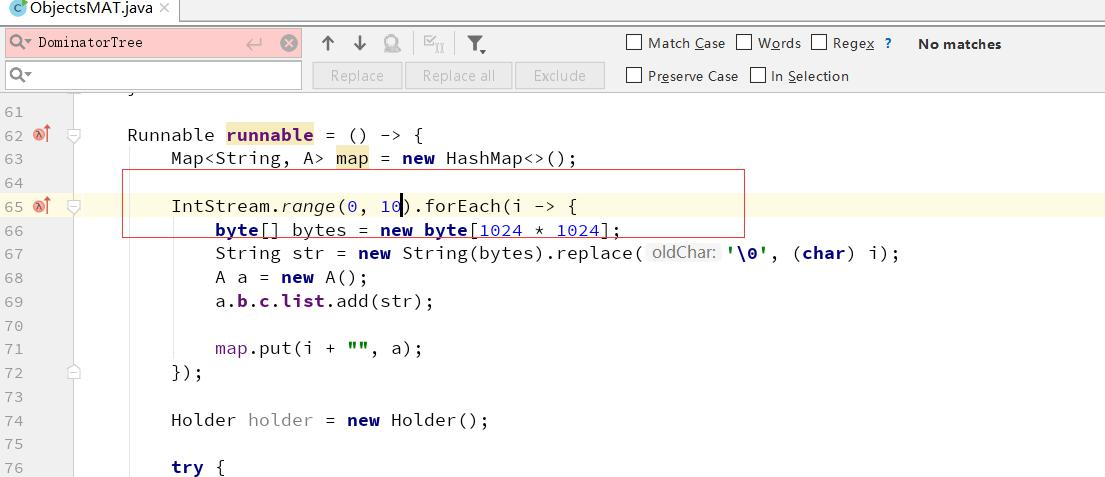
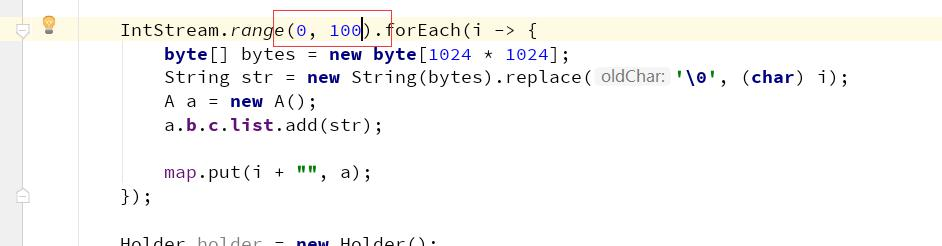
接下来的思路是,先打开一个dump,再打开另一个dump。对比存活对象的变化个数。

线程视图(以线程为GCRoots查找引用链)
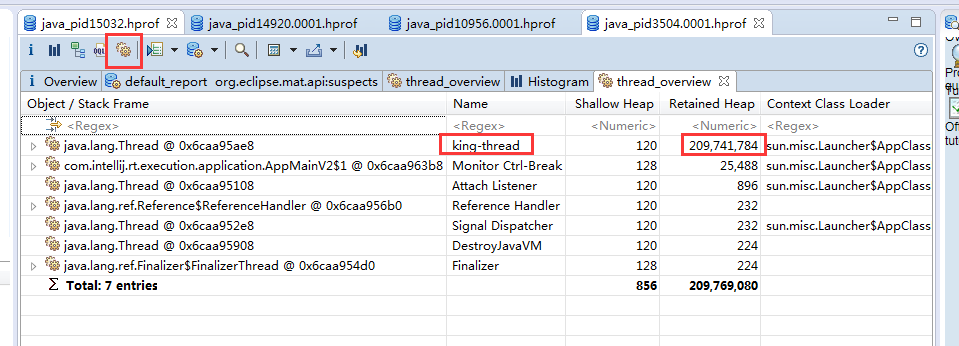
想要看具体的引用关系,可以通过线程视图。线程在运行中是可以作为 GC Roots 的。我们可以通过线程视图展示了线程内对象的引用关系,以及方法调用关系,相对比 jstack 获取的栈 dump,我们能够更加清晰地看到内存中具体的数据。我们找到了 king-thread,依次展开找到 holder 对象,可以看到内存的泄漏点
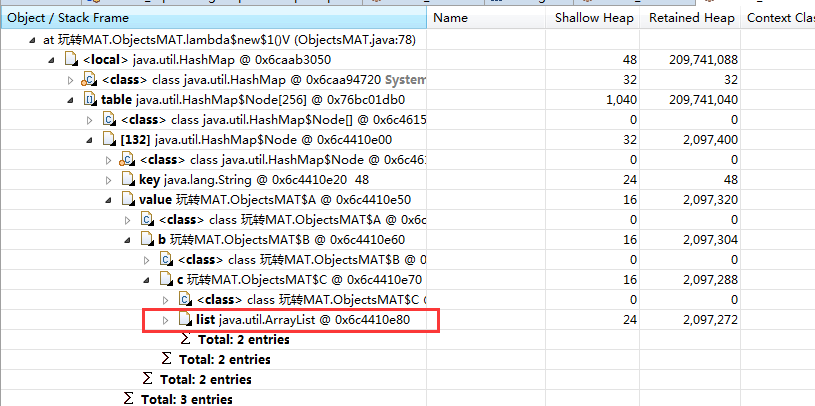
我们通过展开的层层定位也找到了主要占据内存的是这个list。
循环依赖(可达性分析算法能搞定)
还有另外一段是陷入无限循环,这个是相互引用导致的(进行问题排查不用被这种情况给误导了,这样的情况一般不会有问题---可达性分析算法的解决了相互引用的问题)。具体可以结合上面给出的代码分析图。
如上图,这种知道这个情况即可。
柱状图视图(查看对象大小与实例个数)
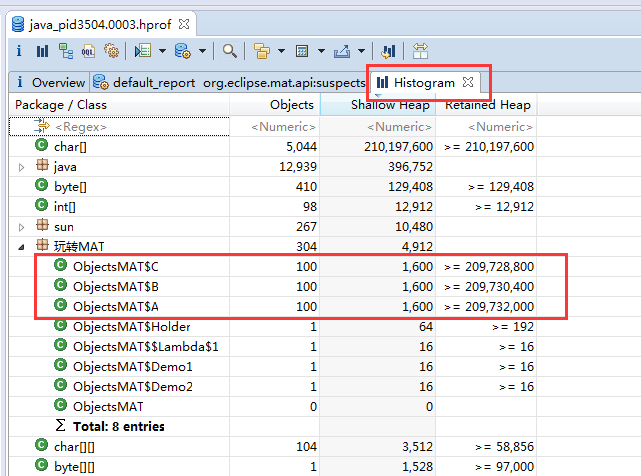
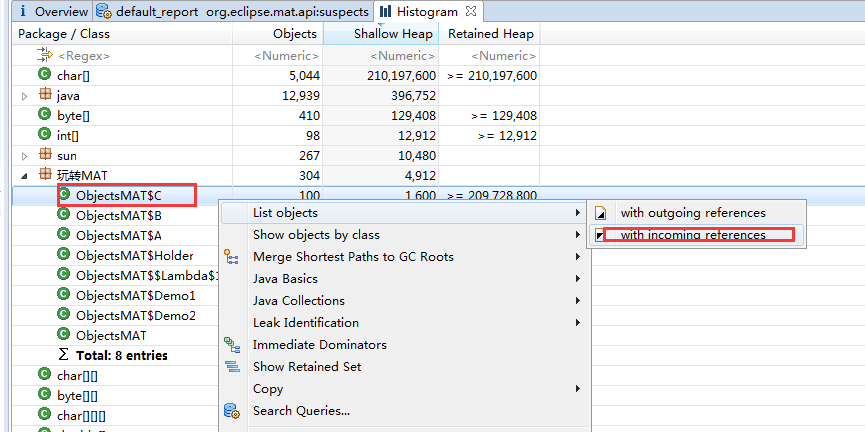
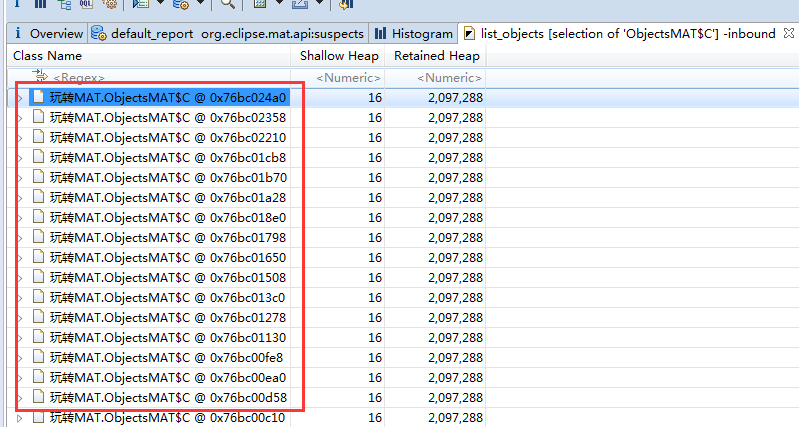
可以看到该类的引入的具体对象。之前的案例也围绕着这个图形多次举例。
Path To GC Roots(查找该对象到GCRoots的引用链,分析内存泄漏)
被 JVM 持有的对象,从这个对象到 GC Roots 的引用链被称为 Path to GC Roots,
通过分析 Path to GC Roots 可以找出 JAVA 的内存泄露问题,当程序不再访问该对象时,我们就可以看看这个引用这个对象的GCRoots到底是谁,以及GCRoots到这个对象之间的引用链,从未分析这个对象为什么无法回收(这个对象可能内存泄漏)。
再次选择某个引用关系,然后选择菜单“Path To GC Roots”,即可显示到 GC Roots 的全路径。通常在排查内存泄漏的时候,会选择排除虚弱软等引用。
我们通过刚才柱状图视图获得了对象的列表。
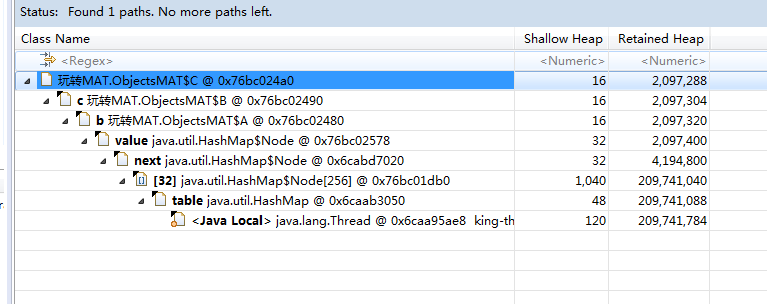
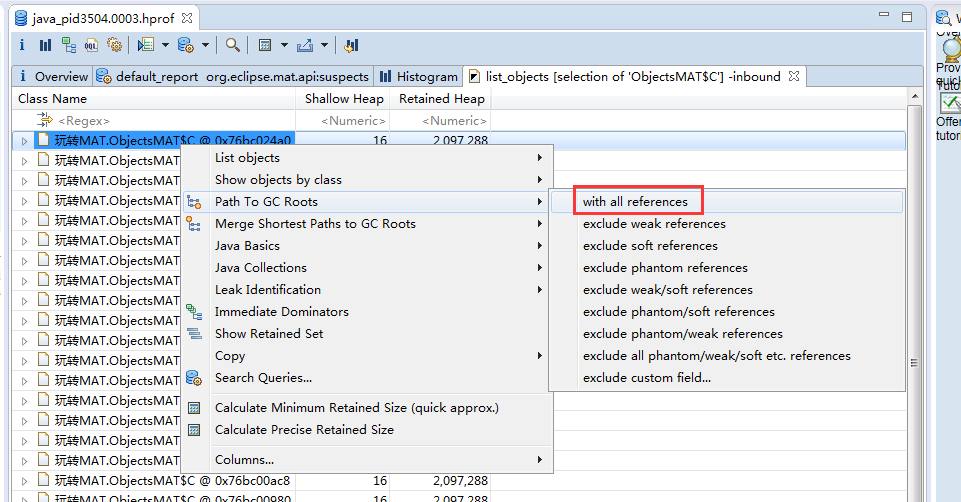
我们就可以得到清晰地该对象的引入链,一直到其对应的GCRoots。
高级功能—OQL(类似于SQL的查询功能)
MAT 支持一种类似于 SQL 的查询语言 OQL(Object Query Language),这个查询语言 VisualVM 工具也支持。
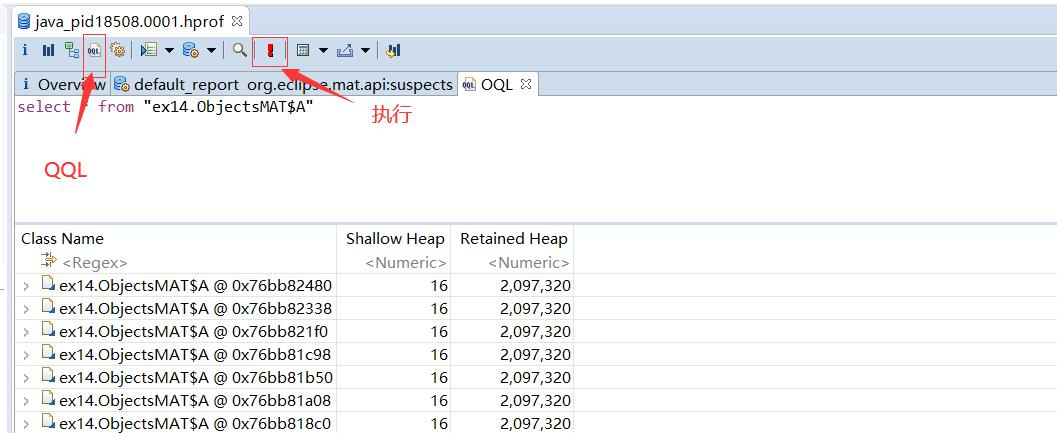
查询 A 对象:
select * from ex14.ObjectsMAT$A
查询包含 java 字样的所有字符串:
select * from java.lang.String s where toString(s) like ".*java.*"
OQL 有比较多的语法和用法,若想深入了解,可以了解这个网址:
http://tech.novosoft-us.com/products/oql_book.htm
总结
通过这些案例,我们知道MAT的强大之处只要在于对堆与对象的底层分析。在发生内存泄漏,或者OOM的时候,使用Arthas就不太合适了。如果用MAT工具,简单的问题预测与相信的引用关系链可以帮我们快速的定位到问题。因此,不同的场景运用合适的工具也是我们成为调优高手的关键。
定位问题后,如何分析问题
我们使用调优工具能将问题发的线程,原因(例如OOM)定位到后,依然需要去在代码中寻找具体的问题原因。此时,我们接着提供问题一些异常分析思路。
超大对象
代码中创建了很多大对象 (例如数据库查询一个超级大的list报表), 且一直因为被引用不能被回收,这些大对象会进入老年代,导致内存一直被占用,很容易引发 GC 甚至是 OOM。
超过预期访问量
通常是上游系统请求流量飙升,常见于各类促销/秒杀活动,可以结合业务流量指标排查是否有尖状峰值。比如如果一个系统高峰期的内存需求需要 2 个 G 的堆空间,但是堆空间设置比较小,导致内存不够,导致 JVM 发起频繁的 GC 甚至 OOM。
过多使用 Finalizer(一般很少)
过度使用终结器(Finalizer),对象没有立即被 GC,Finalizer 线程会和我们的主线程进行竞争,不过由于它的优先级较低,获取到的 CPU 时间较少,因此它永远也赶不上主线程的步伐,程序消耗了所有的可用资源,最后抛出 OutOfMemoryError 。(所以这个拯救线程真的就是为了面试而存在的玩意儿)。
内存泄漏
大对象引用没有被释放掉,JVM无法对其自动回收。如果观察一个系统,每次进行 FullGC 发现堆空间回收的比例比较小,尤其是老年代,同时对象越来越多,这个时候可以判断是有可能发生内存泄漏。内存溢出不一定是代码问题,但是泄漏一定是。
长生命周期的对象持有短生命周期对象的引用
例如将 ArrayList 设置为静态变量,则容器中的对象在程序结束之前将不能被释放,从而造成内存泄漏
连接未关闭
如数据库连接、网络连接和 IO 连接等,只有连接被关闭后,垃圾回收器才会回收对应的对象。
变量作用域不合理
例如,一个变量的定义的作用范围大于其使用范围,如果没有及时地把对象设置为 null,也会导致内存泄漏。
内部类持有外部类
Java 的非静态内部类的这种创建方式,会隐式地持有外部类的引用,而且默认情况下这个引用是强引用,因此,如果内部类的生命周期长于外部类的生命周期,程序很容易就产生内存泄漏(垃圾回收器会回收掉外部类的实例,但由于内部类持有外部类的引用,导致垃圾回收器不能正常工作)
解决方法:你可以在内部类的内部显示持有一个外部类的软引用(或弱引用),并通过构造方法的方式传递进来,在内部类的使用过程中,先判断一下外部类是否被回收;
集合中对象Hash值改变
在集合中,如果修改了对象中的那些参与计算哈希值的字段,会导致无法从集合中单独删除当前对象,造成内存泄露。
优化的三个角度
1. 程序优化,效果通常非常大
2. 扩容,如果金钱的成本比较小,不要和自己过不去;
3. 参数调优,在成本、吞吐量、延迟之间找一个平衡点