预处理
1.首先是预处理模块,这里输入的是boost离线版本的html文件,需要从boost官网下载对应版本的离线包,我们这里使用的是boost1.53版本,从官网下载好以后从压缩包里可以找到一个doc目录,里面的html目录文件就是我么要使用的“原始数据”。光拿到html还不够,对于网页的html文件,会具有一下特点:
这里拿boost官网首页源代码为例,可以明显看到有许多诸如<div>,<head>,<title>这样的结构,这种结构在前端的语言当中叫做标签。用于页面的渲染,而对于我们实现的功能而言,标签与正文是无关的,所以第一个要点就开始了——如何去标签。
经过观察不难发现,标签的特点都是框在一对尖括号当中的,所以我们可以反向思考,只要是由 > 开始到 < 结束的就是正文部分。因此,对于此处我们是这样操作的:创建一个bool变量作为标记,判断当前是否为正文,以<为进入标签的标记,一旦进入<则接下来的内容就不会写入,而一离开>则开始写入最终结果,也就是代码中的content。但这里并不非常严谨,只是简单粗暴的把标签去掉,因为正文中出现的不一定就全是我们需要的。
而此时预处理的过程还没有结束,我们现在得到的去掉标签的文件还是一团由标题,正文以及url组成的乱麻(此处涉及粘包问题,只要是涉及字节流的问题都会联系到粘包问题),想要作为下一个模块的输入部分还需要将他们按一定格式处理,这里为了方便就按照一个行文本文件的格式输出,而中间则由分割符分割,但这里需要选择的是正文中不会包含的分割符,于是就是用了——不可见字符,\1,\2,\3。linux中他们是用^A,^B,^C表示的所以看起来代码就是在各个需要分割的字符中间加入了许多^C。输出的行文本文件就放在data目录中的raw_input中。
索引
2.有了预处理好的行文本文件,我们可以开始放心的建立索引了。这里主要要求我们找到一个合适的(高效的)索引方式,避免使用暴力遍历的方法。于是就到达了本模块的核心——正排索引与倒排索引。顾名思义,正派索引是根据文档的id来查询文档内容,而倒排刚好相反。这里建立一个DocInfo数组,包含编号docId,标题title,链接url以及正文content,来作为正排。而倒排本质上是一个键值对,key是之前得到的分词结果,而value则需要存储docId以及一个用于计算“权重”的Weight对象。而有了正排与倒排索引之后,则可以开始准备输入的数据了。raw_input是一个行文本文件,每一行对应一个文档,每行由标题,url以及正文三个部分组成,中间用\3分割。
开始build正排及倒排索引,首先按行读取文件,根据当前行构造正排索引,而后再次解析docId,在倒排索引中构造对应结构。在这里出现了一个小问题就是,在初次运行后发现,构造的时间长度根据不同的机器会有不同的响应速度,对于性能不太好的机器来说,长时间的无反应构造看起来就像是“机器死机了”。因此为了使这里的构造更加自然,我们给构造这个过程加上了日志打印,而由于文档数量较大,因此定为每100个文档构造完成打印一次,于是就有了以下滚动日志: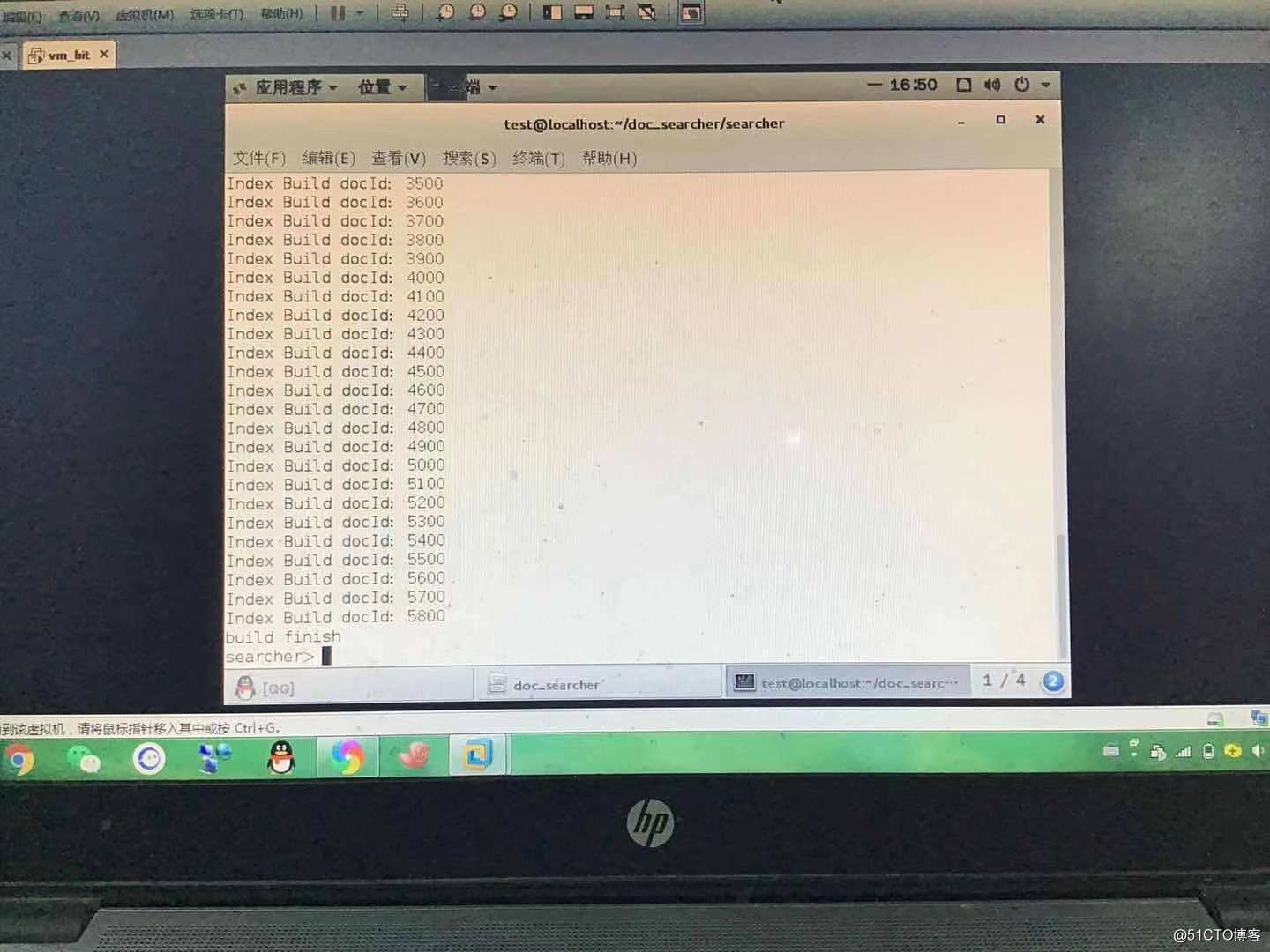
对于切分这里,c++标准库里没有很好的字符切割函数,c语言中有一个“凑合”的——strtok,但这个函数不仅用起来麻烦,并且会破坏字符串的结构,而且它的线程并不安全。就在一筹莫展的时候,boost库传来了喜讯,boost里有一个可以用于切割的函数——split!
boost::split(*ouput, input, boost::is_any_of(delimiter), boost::token_compress_off);```
其中output用于存放输出结果,input存放输入结果,is_any_of是切割符,token_compress_off/on用于确定切分的结果是否需要压缩,off表示不压缩,on表示压缩。这里的压缩是指,例如:
aaa\3bbb\3\3ccc,压缩后的切割结果有三个部分aaa,bbb,ccc;而不压缩的话则是四个部分aaa,bbb,\3,ccc。压缩相当于是把相邻的切割符压在一起。
对于倒排索引需要的权重这里,考虑到标题的相关性要比正文强,于是灵机一动便有了如下公式:
>最终权重 = 标题中出现次数 x 10 + 正文中出现次数。
有了公式以后便可以开始分词,这里就要用到我们另一个外部库来实现了——cppjieba,结巴分词。说到结巴分词,这是一个功能很强大的分词工具,支持三种分词模式:
1.精确模式,试图将句子最精确地切开,适合文本分析;
2.全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
3.搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
并且也包括支持繁体以及自定义词库。
结巴分词主要的功能函数如下:
1.jieba.cut 方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型
2.jieba.cut_for_search 方法接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细
待分词的字符串可以是 unicode 或 UTF-8 字符串、GBK 字符串。注意:不建议直接输入 GBK 字符串,可能无法预料地错误解码成 UTF-8
3.jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode),或者用
4.jieba.lcut 以及 jieba.lcut_for_search 直接返回 list
5.jieba.Tokenizer(dictionary=DEFAULT_DICT) 新建自定义分词器,可用于同时使用不同词典。jieba.dt 为默认分词器,所有全局分词相关函数都是该分词器的映射。
这里主要用到的是jieba.cut_for_search函数。使用结巴分词时需要先加载它的词典,得保证词典引用路径的正确的,如下:

这里还有一个要注意的点就是,对于文档的大小写区分问题。区分的话是指,Hello,hello以及HELLO为三个单词,各出现一次;不区分则认为成一个单词出现三次。这里参照搜狗的做法选择不区分,因此就要把所有的字母都转为小写。与之前情况一样,c++标准库中没有转化大小写的函数,而在boost库有这样一个函数:boost::to_lower(word),可以将内容全部转为小写。
全部分词完成之后,统计词在各处出现的次数。遍历统计结果(key-value),根据统计结果来更新倒排索引,再根据词来创造weight对象。此时,倒排构造这一结构的核心逻辑就完成了。
接下来写一个简单的测试代码,调用一下索引模块,观察weight的内容,正排中的内容以及文档存在的检查和计算公式计算的规则是否合理,通过之后就可以确定索引模块的完成。要注意这里只是一个简单的冒烟测试,如果要得出严谨的观察结论,则需要多方位的大量的测试用例了。